这篇论文,作者提出了一个MEDA组成的MEDAN(多模态编码解码注意力网络)。
作者发现在共同注意中,在学习图像区域的细粒度特征时,首先学习问题引导注意特征与首先学习自我注意特征是不同的,后者可以获得更好的图像区域表示。原因可能是前者有助于理解图像,而后者更像是一个基于对图像的理解模块。
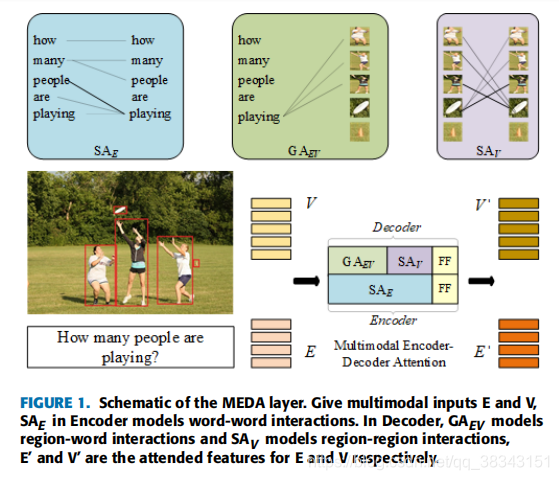
如上图所示,每个MEDA层都包括一个编码器模块和一个解码器模块(这里和transformer很像)。编码器的核心是一个文本自我注意单元,用来建模细粒度的文体特征;解码器主要包含一个问题引导注意单元和一个图像自注意单元,用来提取细粒度的图像区域特征。
模型流程

整个模型由三个模块组成,图像和问题的表示;多模态解码编码注意以及图像和问题特征的融合以及输出分类。
首先来看图像和问题的特征表示:
输入的图像通过faster-rcnn来提取特征,输入图像的特征被表示为V,这里V是k*2048,表示有k个目标区域。
输入的问题首先被标记为一个个单词,然后通过Glove得到词向量,然后经过LSTM获得问题特征E(u*512)。u是单词数量。
通常,我们将k和u固定为100和14(不够的使用0填充)

![]()
然后让V经过一个线性层,使其维度和问题特征相同。
多模态解码编码注意

解码编码都是基于上图这个transformer。

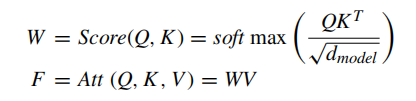
多头注意级联操作:

解码编码:
在编码器中,通过自注意学习问题特征。
首先将问题特征转化为qkv矩阵,如下所示
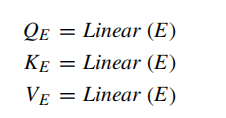
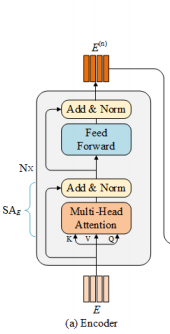
这个编码器主要用来学习问题中两个单词之间的相关性,下面为经过残差连接执行Add&Norm步骤
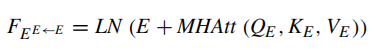 (LN为层归一化)
(LN为层归一化)
然后再经过Feed Forward(该层由具有relu函数的全连接层构成,并对其使用了dropout来防止过拟合),最后再通过Add&Norm得到加上注意力的问题特征
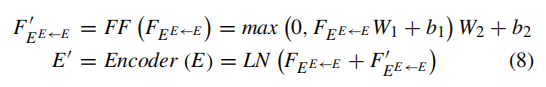
DECODER
这里来计算关于图像的特征,过程类似于问题特征,只是这里首先通过问题引导的注意力来计算图像特征。
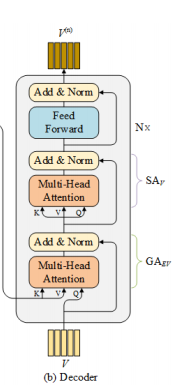
经过编码器的问题特征E传入到解码器,经过变换得到k和v,图像特征V变换为Q。
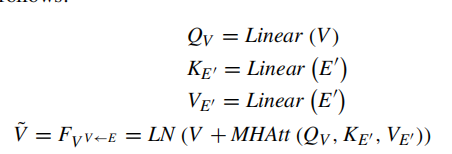
以上为解码器的第一阶段,问题引导注意;下面是第二阶段,使用得到的图像注意力特征进行自我注意
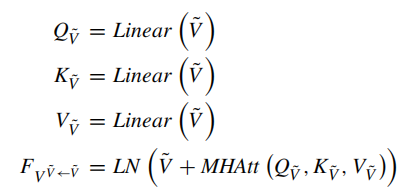
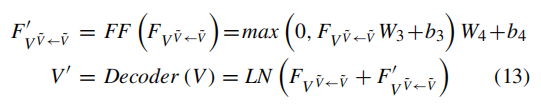
和问题的自我注意步骤一样
IMAGE-QUESTION FEATURE FUSION AND OUTPUT CLASSIFIER
最终得到的问题特征经过softmax计算出每一个单词的权重,然后加权求和;计算图像特征的步骤也是一样的。
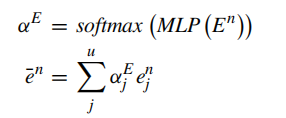
两个模态进行融合

f通过线性层改变输出维度(大小为训练集中出现频率最高的答案的个数),最后使用sigmod进行预测
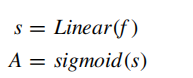
在vqa2.0上的实验结果如下
