语义分割领域最常用的编解码方案中, 上采样是一个重要的环节, 用来恢复分辨率. 常用的是, 双线性插值和卷积的配合. 相较于具有一定的棋盘效应的转置卷积, 双线性插值简单快捷, 而且配合后续卷积, 也可以实现和转置卷积类似的效果, 而其他的方法, 如外围补零, 则是会引入过多的冗余无用信息。
当前的语义分割方法多使用了编解码架构来获得逐像素的预测结果,解码模块的最后一层通常是一个双线性插值上采样来恢复特征图的分辨率,但是这种数据无关而且过于简单的上采样可能会导致不是最优的分割结果。其在准确恢复像素预测方面的能力有限. 双线性上采样不考虑每个像素的预测之间的相关性,因为它是数据独立的。
因此,卷积解码器被需要来产生相对较高分辨率的特征图, 以便获得良好的最终预测. 但是这个需要也会导致两个问题:
- Out Stride越小,编码器中就需要更多多种尺寸的空洞卷积层,导致了计算复杂度和所需内存大幅度增加,例如deeplabv3+就很慢. (扩张卷积的主要缺点是计算复杂度和更大的内存需求, 因为这些卷积核的大小以及结果的特征映射变得更大.)
- 解码器需要融合来自更低层级的特征. 由于双线性上采样能力的不足, 导致最终预测的精细程度, 主要由更低层级的特征的分辨率占据主导地位. 结果, 为了产生高分辨率预测, 解码器必须将高分辨率特征置于低级层次上, 这样的约束限制缩小了特征聚合的设计空间, 因此可能导致次优的特征组合在解码器中被聚合.
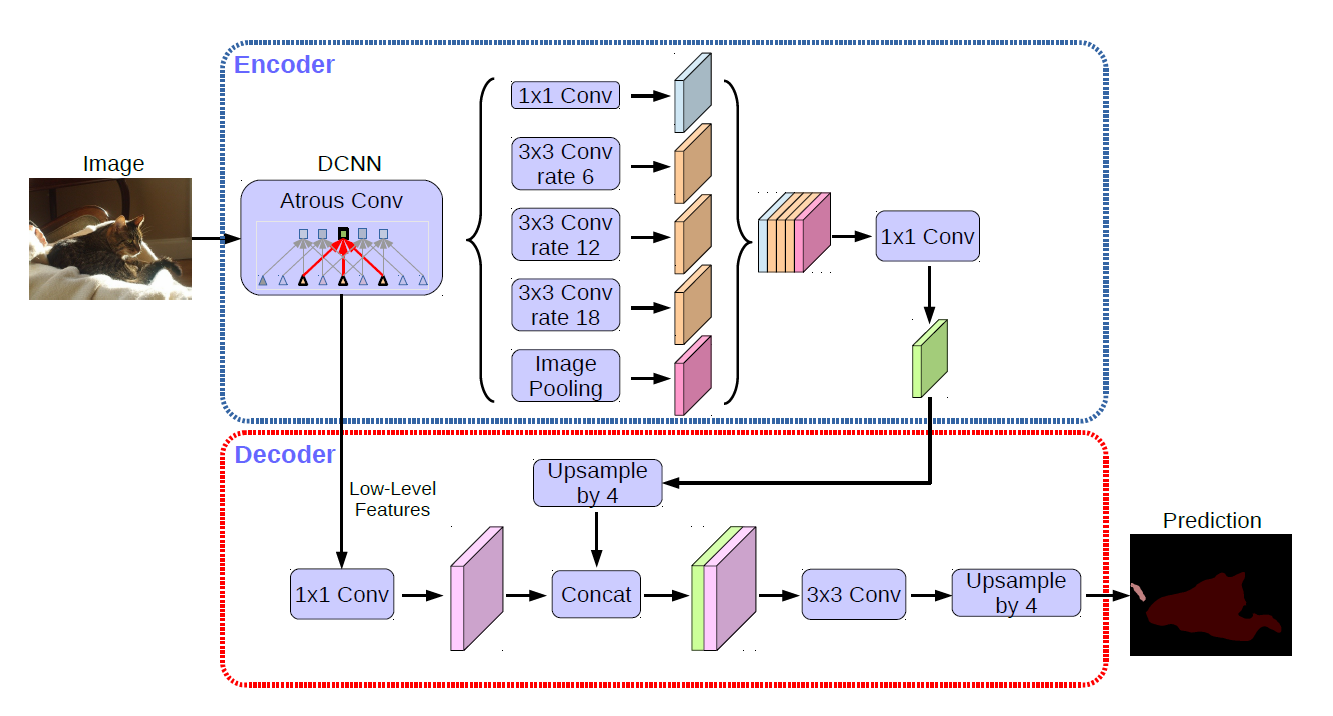
?为了处理这些问题, 文章提出了一个可学习的"上采样"模块: DUpsamling. 来替换被广泛使用的双线性插值上采样方法, 恢复特征图的分辨率. 来利用分割标签空间的冗余, 以及准确的恢复像素级预测. 减少了对卷积解码器的精确响应的需要. 因此, 编码器不再需要过度减少其整体步幅, 从而大大减少整个分割框架的计算时间和内存占用。
同时, 由于 DUpsampling 的有效性, 它允许解码器在合并之前将融合的特征降采样到特征映射的最低分辨率. 这种下行采样不仅减少了解码器的计算量, 更重要的是它将融合特征的分辨率和最终预测的分辨率解耦. 这种解耦使解码器能够利用任意特征聚合, 从而可以利用更好的特征聚合, 从而尽可能提高分割性能。
最后, DUpsampling可以通过标准的 1x1 卷积无缝地合并到网络中, 因此不需要ad-hoc编码. (也就是不需要专门为了使用它而设计网络)
总体而言, 该论文提出了一种新的解码器方案:
- 提出了一种简单而有效的数据依赖上采样 (DUpsampling) 方法, 从卷积解码器的粗略输出中恢复像素级分割预测, 替换以前方法中广泛使用的效果较差的双线性.
- 利用提出的 DUpsampling, 可以避免过度减少编码器的整体步幅, 显著减少了语义分割方法的计算时间和内存.
- DUpsampling 还允许解码器将融合的特征在融合它们之前, 降采样到特征图的最低分辨率.下采样不仅减少了解码器的计算量, 大大扩大了特征聚合的设计空间, 使得解码器能够利用更好的特征聚合.
论文提出的方法
论文第三节先是重新形式化带有DUpsampling的语义分割,然后提出适应性softmax函数更好地训练DUpsampling,最后展示这种方法如何大幅度提升最终效果。
重建误差
一个重要的观察是, 图片的语义分割标签Y并不是独立同分布的(i.i.d, 也就是互相有依赖), 其中包含着结构信息, 以至于Y可以被压缩而不会造成太大的损失,因此不同于其他方法中将F上采样至与Y尺寸相同。论文尝试将Y压缩至![]() ,然后计算F与
,然后计算F与 ![]() 的损失。为了将Y压缩成
的损失。为了将Y压缩成![]() ,论文设计了一个几乎无损的重构方式,给定r=OutStrider。Y被分为
,论文设计了一个几乎无损的重构方式,给定r=OutStrider。Y被分为![]() 的网格形式,对于每一个子窗口
的网格形式,对于每一个子窗口![]() ,将S变形为一个向量
,将S变形为一个向量![]() 其中
其中![]() 最终将向量v压缩成一个低维向量
最终将向量v压缩成一个低维向量![]() ,然后从水平和垂直方向排列x以形成
,然后从水平和垂直方向排列x以形成![]() 。
。
- 对于原始的F(HxWxC)使用大小为rxr的滑窗处理(这有些类似于pooling操作, 可能还会需要padding操作), 提取数据, 获得一个个的(rxrxC)大小的数据块.
- 之后各自reshape为大小为1xN(N=rxrxC)的张量
- 再进行维度的压缩, 从1xN变为1x
, 可以认为是一个1x1的卷积操作. 所有的H/r x W/r 个数据块对应的张量组合得到最终的压缩数据
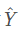 .
.
最简单的就是线性映射,形式化定义为:
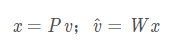
其中![]() 把v压缩成x,
把v压缩成x,![]() 是与其相反的转化,
是与其相反的转化,代表重建后的v.
P和W可以通过最小化v和 之间的误差得到,形式化定义为:
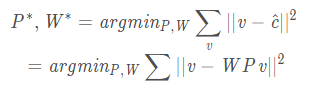
这个优化问题, 可以利用迭代的标准SGD算法优化. 同时, 这里提到, 使用正交约束, 可以简单的使用PCA来实现.
以 ![]() 为目标,可以使用回归损失对网络进行预训练来观察这个目标值是否是实际值:
为目标,可以使用回归损失对网络进行预训练来观察这个目标值是否是实际值:
![]()
此外更为直接的方式是直接计算在Y维度的损失,所以论文通过对学到的转换W来对F进行上采样,然后计算F和Y的损失:
![]()
通过这个重构,DUpsampling(F)将线性上采样W*f来应用到tensor F中的每一个特征![]() 中,由此替代了双线性插值。这个上采样过程和在空间维度应用点卷积一样,卷积核参数在W中存储,过程如下图所示:
中,由此替代了双线性插值。这个上采样过程和在空间维度应用点卷积一样,卷积核参数在W中存储,过程如下图所示:
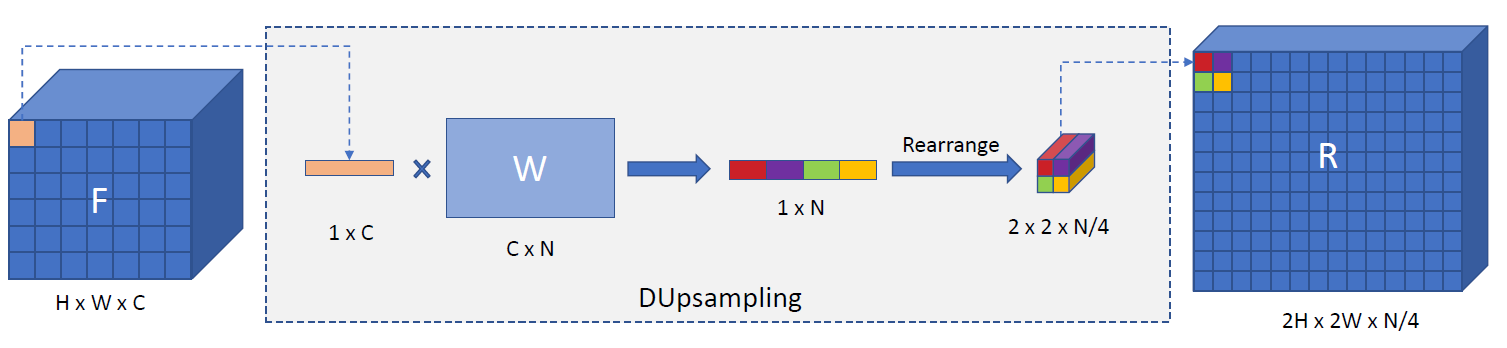
将DUpsampling和带有自适应T的Softmax结合
虽然可以通过1x1卷积操作实现DUpsampling, 但直接将其合并到框架中会遇到优化困难, 文章认为, 因为W是利用one-hot编码后的Y来计算的, 原始softmax和提出的DUpsample的计算, 很难产生较为锐利的激活.结果导致交叉熵损失在训练中被卡住, 使得训练过程收敛很慢.为了解决这个问题, 这里使用了Hinton著名论文 Distilling the knowledge in a neural network 里提到的"温度"的概念. 对softmax添加了一个"温度"T的参数, 来锐利/软化softmax的激活,以达到在各个类上的概率分布更加soft的效果,公式如下:
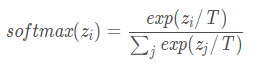
这个参数T可以再反向传播中自动学习, 无需调整.
灵活的卷积特征融合
极深卷积神经网络虽然在计算机视觉方向取得了很大的进展,但是其丢失了图像精细的位置特征,因此多个研究表明结合浅层的特征能够更好的提升语义分割的精度。
假定F是CNNs的特征图用于产生最终的逐像素预测结果,![]() 代表了在leveli的CNN的特征图和最终的特征图。先前方法的特征聚合可以形式化为:
代表了在leveli的CNN的特征图和最终的特征图。先前方法的特征聚合可以形式化为:
![]()
这种操作会导致(1)f即CNN是在上采样之后应用,f作为CNN,计算量依赖于输入的尺寸,这种操作无疑回增加解码器的计算难度,而且这种计算弱化了解码器融合浅层特征的能力;(2)待融合特征Fi和F的尺寸相等,也就是最终输出的四分之一,为了获得更高分辨率的预测图,解码器只能选择比较浅层的特征。

相反, 在提出的框架中, 恢复全分辨率预测的任务在很大程度上已经转移到DUpsampling.因此, 可以安全地下采样要使用的任何级别的低层特征到最后一个特征图Flast的分辨率(特征图的最低分辨率), 然后融合这些特性以产生最终的预测. 表示为:

这种重排不仅使特征始终以最低分辨率高效计算,而且还使底层特征 Fi 和最终分割预测的分辨率分离, 允许任何级别的特征进行融合.