摘要
情感可控的回复生成是一项兼具吸引力和价值性的任务,旨在使开放域的对话更具同理心和吸引力。现有的方法主要是通过在标准交叉熵损失中加入正则化项来增强情感表达,从而影响训练过程。然而,由于缺乏对内容一致性的进一步考虑,加剧了回复生成任务中常见的安全回复问题。此外,以往的模型还简单地忽略了有助于建模查询和回复之间关系的查询情感,从而进一步损害了一致性。为了缓解这些问题,我们提出了一种名为“课程式对偶学习”(CDL)的新框架,该框架将情感可控的回复生成扩展为对偶任务,以交替生成情感回复和情感查询。CDL利用聚焦在情感和内容层面的两种奖励来提高对偶性。此外,它还应用课程式学习,根据表达各种情感的困难,逐步产生高质量的回复。实验结果表明,CDL在连贯性、多样性以及与情感因素的关系等方面都明显优于基线。
1 介绍
在对话系统中注入情感可以使会话主体更加人性化,有利于人机交互。在一些现实场景中,我们需要定制和控制主体的情感,以便其能够表达特定的情感。例如,在心理咨询中,会话主体应该可以向患者表达悲伤表示同情,也要传达快乐,让患者振作起来。
最近,一种称为情感聊天机(ECM)的框架(周等人,2018a)被提出以受控的方式解决情感因素,该框架侧重于生成具有特定情感的回复(表1中的示例1)。

在控制情感回复生成的研究领域,ECM和它后续的一些方法(科伦坡等人,2019年;宋等人,2019年)主要将给定的情感类别表示为向量,并将其添加到解码步骤中,以影响回复生成的过程,这将加剧安全回复问题。对于回复生成任务,安全回复是臭名昭著的,因为模型往往会生成一些通用但无意义的回复,如“谢谢”、“我不知道”、“是”等等。由于情感因素的限制,恰当回复的规模缩小,模型更有可能将任何查询映射到该情感类别中频繁出现的回复。也就是说,如果给的情感是“厌恶”,回复往往是“你太糟糕了”,而如果是“快乐”,它将是“哈哈,你也是”(表1中的示例2到4)。
直观地说,对于一对好的查询和回复,它们应该具有紧密的关系,并且具有同等的质量。这样,查询到回复映射和回复到查询映射都会更容易、更自然。相反,无论是在内容层面还是情感层面,安全回复都很难通过相反生成达到原始的查询。同时,产生各种情感的难度是不同的,特别是在噪声和质量参差不齐的数据集上。因此,我们可以根据来自反向过程的反馈来评估回复,以提高连贯性(Zhang等人,2018年;崔等人,2019;Luo等人,2019b),并尝试从容易到复杂的数据学习,以产生适当的、情感丰富的回复。
本文提出了一种新的情感可控回复生成框架--课程式对偶学习(CDL)。我们把带有情感的回复和查询生成学习作为一个对偶任务,并用对偶性来建模它们之间的相互关系。通过强化学习(RL)交替训练前向和后向模型。这里设计的奖励旨在鼓励情感表达和内容一致性。具体地说,情感表达既可以是显性的(体现在一些明显的情感词中),也可以是隐性的(体现在整个句子的组织上)。比如,“很高兴再次见到她”因为“高兴”二字是显示的,而“好像吃了蜂蜜”是是隐式的,但当我们把这句话作为一个整体来考虑时,就能感受到这种开心。基于这些特征,我们分别用句子情感分类的准确率和情感词占比作为隐性情感和显性情感的反馈。对于内容一致性,我们应用重构概率作为一致性的度量(3.1节)。此外,为了更好地利用来自噪音和质量参差不齐的数据集的多种情感样本,我们将课程式学习(第3.2节)纳入了我们的对偶学习框架(第3.3节)。
在自动评价和人工评价上的实验结果表明,对于给定的查询和情感类别,我们的CDL能够成功地表达期望的情感,并保持回复的信息量和与查询的一致性。
2 背景
对于产生情感可控的回复,在给定查询q和情感类别er的情况下,目标是生成不仅有意义而且符合期望情感的回复![]() 。
。
情感聊天机(ECM)使用三种新的机制来解决情感因素:情感类别嵌入、内部记忆和外部记忆。具体而言,1)情感类别嵌入通过嵌入情感类别对情感表达的高层抽象进行建模,并在每个解码步骤将相应的嵌入与输入连接起来。2)内部记忆通过读写门捕捉隐含的内部情感状态的变化,3)外部记忆运用外部情感词汇来明确表达情感,最终赋予情感和通用词不同的生成概率。一个训练样本(q,r)(q=q1,q2,…,qn,r=r1,r2,…,rm)上的损失函数定义为:
![]()
其中ot和pt是预测的词分布和黄金分布,αt是选择情感词或通用词的概率,qt∈{0,1}是它们在r中的真实选择,![]() 是最后步骤m处的内部情感状态。第一项是交叉熵损失,第二项是用来监督选择情感或通用词的概率,最后一项是用来确保生成完成后,内部情感状态得到了完整的表达。更多详情请参考原文。
是最后步骤m处的内部情感状态。第一项是交叉熵损失,第二项是用来监督选择情感或通用词的概率,最后一项是用来确保生成完成后,内部情感状态得到了完整的表达。更多详情请参考原文。
3 用于情感可控回复生成的CDL
由于我们CDL方法是对偶学习(DL)和课程学习(CL)的结合,我们首先介绍了DL的主要组成部分,包括状态、行动、策略和奖励,然后介绍了课程式学习的合理性。最后描述了CDL的训练算法。
3.1 DL架构
DL的架构如图1所示。前向模型Mf和后向模型Mb都是具有独立的参数的ECM,并根据最大似然估计(MLE)进行初始化。CLS是一个预先训练好的分类器,用于计算内隐情感表达的得分。

通常,Mf为给定的查询q和情感类别er生成回复r',然后获得由CLS的Re和Mb的Rc组成的奖励R(图一中的红色部分)。类似地,Mb为给定的回复r和情感类别eq生成查询q',并获得由CLS的Re和Mf的Rc组成的奖励R(图1中的蓝色部分)。这两个模型通过强化学习(RL)交替训练。具体地说,动作是要生成的对话回复。动作空间是无限的,因为可以生成任意长度的序列。状态由查询表示,该查询进一步由编码器转换成矢量表示。策略采用GRU编解码器的形式,并由其参数定义。遵循Li等人(2016c)和张等人(2018)的工作,我们使用策略的随机表示,即给定状态下动作的概率分布。
为了同时鼓励内容一致性和情感表达,我们引入了两个奖励,并用它们来训练Mf和 Mb。对模型Mf的两项奖励定义如下:
情感表达的奖励 对于隐性情感表达,一种简单的方法是使用预先训练好的分类器CLS来评估生成的回复R'的情感类别,并以分类准确率作为奖励:
![]()
其中,?为CLS的参数,在训练时固定。对于显式的情感表达,奖励公式为:
![]()
其中n(wer)是属于类别er的情感词的数量,|r'|是r'的长度。
然后,将情感奖励定义为:
![]()
其中λ控制隐性奖励和显性奖励的相对重要性。
内容一致性奖励 如果回复是连贯的,并且与查询相关,则通过回代来重现查询将更容易。灵感来自于张等人(2018年);崔等人(2019年);罗等人(2019b),我们通过重构给定r'下的q来测量相关性。形式上,内容一致性奖励定义为:
![]()
其中η为反向模型Mb的参数,在Mf的训练过程中固定。
总的奖励 我们用上述两项奖励的加权和作为最终奖励:
![]()
其中γ是控制Rc(q,r')和Re(q,r')之间的折衷的超参数。
3.2 课程式合理性
直观地说,从噪声较小且质量均匀的数据集学习会更简单,但在这项任务中,数据本身就很复杂,因为其中混合了多种情感。为了更好地利用这些数据,我们将课程式学习整合到对偶学习框架中。课程式学习的核心是设计一个复杂度评估,先给模型提供简单的样本,然后逐步增加难度。根据特定的排名标准,通过对训练集中的每个样本进行排序来安排训练。
在这里,我们将样本重新排序从容易的,即情感分类准确率高的,到难的。我们将预训练后的分类精度作为学习顺序的一个指标。另一种直观的方法是将无情感的样本(标记为“中立”)放在第一位,然后是有情感的样本,但在我们的实验中表现出较差的性能。在训练步骤t,从整个排序的训练样本的顶部f(t)部分获得一批训练样本。跟随Platanios等(2019)和蔡等人(2020),我们将函数f(t)定义为:
![]()
其中,![]() 被设置为0.01,这意味着模型使用1%最容易的训练样本开始训练,而T是表示课程学习持续时间(课程长度)的超参数。在训练过程的早期阶段,模型从课程的简单部分的样本中学习,那里只有一个情感类别。随着课程的推进,难度逐渐增加,出现了来自更多不同类别的复杂训练样本。训练T批次后,从整个训练集中抽取每一批次的训练样本,与常规训练过程相同。
被设置为0.01,这意味着模型使用1%最容易的训练样本开始训练,而T是表示课程学习持续时间(课程长度)的超参数。在训练过程的早期阶段,模型从课程的简单部分的样本中学习,那里只有一个情感类别。随着课程的推进,难度逐渐增加,出现了来自更多不同类别的复杂训练样本。训练T批次后,从整个训练集中抽取每一批次的训练样本,与常规训练过程相同。
3.3 CDL训练
最优化 我们使用策略梯度方法(Williams,1992)来寻找产生更大预期回报的参数。对于前向学习过程,生成的回复r'的期望回报及其近似梯度被定义为:
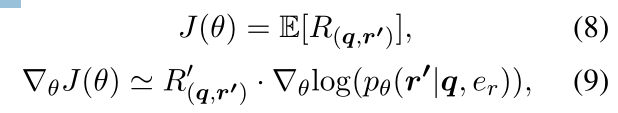
其中θ是正向模型Mf的参数,![]() bf值是Mf的贪婪搜索解码方法的基线值,用于减小估计的方差。类似地,对于后向学习过程,将生成的查询q'的期望回报和对应的近似梯度定义为:
bf值是Mf的贪婪搜索解码方法的基线值,用于减小估计的方差。类似地,对于后向学习过程,将生成的查询q'的期望回报和对应的近似梯度定义为:
![]()
其中η是反向模型Mb的参数,![]() bb是来自Mb的贪婪搜索解码方法的基线值。
bb是来自Mb的贪婪搜索解码方法的基线值。
Teacher Forcing 当Mf和Mb只使用对偶任务的奖励进行训练时,训练过程很容易崩溃,因为它可能会找到一种意想不到的方式来获得高奖励,但无法保证生成的文本的流畅性或可读性。为了稳定训练过程,每次更新后根据公式9或11,Mf和Mb暴露在真实的查询回复对中,并通过MLE进行训练,(也称为Teacher Forcing )
算法1总结了CDL的训练过程。首先,我们使用MLE在训练集中对带有查询-回复对和情感标签的Mf、Mb和 CLS进行预训练。在预训练阶段之后,我们按照第3.2节中的排名标准对训练集中的样本进行排序。对于前向学习过程,基于回复进行排序,而对于后向学习过程,基于查询进行排序。然后,我们可以得到每个方向的两个排序训练集Df和Db。最后,Mf和Mb通过奖励和Teacher Forcing的正则化交替进行优化。

4 实验
在这一部分中,我们进行实验来评估我们提出的方法。我们首先介绍了一些经验设置,包括数据集、超参数、基线和评估方法。然后,我们举例说明了我们在自动和人工评估下的结果。最后,我们给出了一些不同模型产生的案例,并对我们的方法做了进一步的分析。
4 实验
在这一部分中,我们进行实验来评估我们提出的方法。我们首先介绍了一些经验设置,包括数据集、超参数、基线和评估方法。然后,我们举例说明了我们在自动和人工评估下的结果。最后,我们给出了一些不同模型产生的案例,并对我们的方法做了进一步的分析。
4.1 数据集
我们将我们的方法应用于NLPCC 2017情感会话生成挑战的语料库,即NLPCC2017数据集,它是周等人(2018a)收集的数据集的扩展版。所提供的数据集已经被切分成中文单词。有100多万个查询-回复对,其中查询和回复都被贴上了“高兴”、“愤怒”、“厌恶”、“悲伤”、“喜欢”和“中立”之间的一个情感标签。数据集已经分过词了。我们将整个数据集随机分为训练/验证/测试集,数量为1,105,487/11,720/2,000。训练集的详细统计如表2所示

4.2 超参数设置
Mf和Mb的设置都遵循原始ECM论文(周等人,2018a)的默认实现细节,其中编码器和解码器具有两层GRU结构,每层具有256个隐藏单元,单词和情感类别的嵌入大小被设置为100,词汇大小被限制为4万。最小和最大句子长度分别设置为3和30。我们训练了一个基于TextCNN的分类器(Kim,2014),在测试集上的分类准确率达到了65.6%,与(周等人,2018a)和(Song等人,2019年)使用的分类器性能相似。在课程式对偶学习前,Mf和Mb通过MLE预训了10个epoch。优化器是Adam,预训练初始学习率0.05,课程式对偶学习初始学习率为10?5。批处理大小设置为64。等式4中的λ是0.5,等式6中的γ等于1,等式7中的T等于100k。课程式对偶学习训练一直进行,直到验证集上的性能没有提高。
4.3 baseline
我们将我们的方法与四个有代表性的基线进行比较:(1)S2S-Attn:Sang等人提出的具有注意机制的Seq2Seq模型。(2015年)。(2)EmoEmb:一种Seq2Seq变体,它将情感类别的嵌入作为每个解码位置的额外输入(Ficler和Goldberg,2017;Li等人,2016b)。(3)EmoDS:一种基于词汇的注意力和基于单词的分类器的情感对话系统(Song等人,2019年)。(4)ECM:周等人(2018a)提出的情感聊天机。
此外,我们还进行了消融研究,以便更好地分析我们的方法,如下所示:(5)CDL-emo:仅有情感奖励的CDL;(6)CDL-con:仅有内容奖励的CDL,类似于Zhang等人(2018)的工作;(7)CDL-DL:两种奖励都有但没有课程式学习的CDL。
4.4 评估方法
为了更好地评估我们的结果,我们在实验中同时使用了量性指标和人类判断。
4.4.1 自动评测
对于自动评估,我们主要选择四种指标:1)嵌入分数(平均、贪婪、极端和连贯);2)BLEU评分(Papineni et al.,2002)0~1分;3)dist-1、dist-2(Li等人,2016a)和4)情感-acc,情感-词(周等人,2018a;宋等人,2019年)。
嵌入分数和BLEU分数用来衡量内容相关性方面生成的回复的质量。而DIST-1和DIST-2用于评价回复的多样性。采用情感准确度和情感词对情感表达进行测试。具体地说,EMO-acc是通过之前训练的TextCNN分类器在事实标签和预测标签之间的一致性。Emo-word是包含相应情感词的生成回复的百分比。由于测试集中没有多情感的基本事实,为了公平比较,我们只计算标记了情感e的基本事实和生成的回复(也标记为e)之间的指标。
4.4.2 人工评测设置
灵感来自于周等人(2018a);Song等人(2019年),进行人工评估为了更好地分析生成的回复的质量。首先,我们从测试集中随机抽取200个查询。除了S2S-Attn之外,每种方法都为6个情感类别生成6个回复,而S2SAttn为每个查询生成来自波束搜索解码的前6个回复 。然后,我们将(查询、回复、情感)的三元组无序地发送给三个人工标注人员,并要求他们分别从内容和情感两个层面对每个回复进行评估。
内容和情感分别由3级评分(0,1,2)和2级评分(0,1)衡量。来自内容级别的评估是对于查询回复是否流畅、连贯和有意义,而来自情感级别的评估确定回复是否表达了所需的情感。
4.5 实验结果
现在,我们展示我们在自动评价和人工评价上的实验结果。
4.5.1 自动评估结果
自动结果如表3所示。

上面部分是所有基线模型的结果,我们可以看到CDL在所有度量上都优于其他方法(t检验,p值<0.05)。CDL在连贯性、情感准确度和情感词汇性三个方面都有显著的提高,表明它可以同时提高内容一致性和情感表达能力。EmoDS和ECM有相似的表现,因为它们都使用前向方法来更多地关注情感因素。S2S-Attn只能生成基于语义映射的流畅回复,不能表达多样化回复。
表3的底部显示了我们的消融研究结果。CDL-emo、CDL-con和CDL的比较表明,组合奖励在情感表达和内容一致性方面都是有效的。此外,我们还发现,在课程式学习的支持下,CDL比CDL-DL能取得更好的效果。
4.5.2 人类评估结果
结果如表4所示。

CDL在情感表达(0.582)和内容连贯(1.286)两个方面都获得了最好的表现(t检验,p值<0.05)。正如我们所看到的,EmoDS和ECM之间没有明显的区别。由于“愤怒”的训练数据不足(查询79,611个,回复138,198个),S2S-Attn为它获得了最好的内容得分,这与周的结果相似。
表4中情感和内容的结果是独立的。为了更好地评估生成的回复的整体质量,我们通过同时考虑内容和情感得分,在表6中提供了结果。

CDL产生的反应中有32.5%用情感分数2和内容分数1标注,这表明CDL在产生连贯和丰富情绪的回复方面表现更好。
衡量三个注释者之间一致性是用Fleiss的kappa计算的(Fleiss和Cohen,1973)。Fleiss的kappa对内容和情感得分分别为0.497和0.825,分别表示“适度一致”和“基本一致”。
4.6 个例研究
表5显示了S2S-Attn、ECM和CDL生成的示例。从它可以看出,对于一个给定的输入,有多个情感类别适合于它在对话中的回复。S2S-Attn生成带有随机情感的响应,而ECM和CDL可以利用特定的情感标签。与ECM相比,CDL能产生具有任何想要的情感的连贯且信息丰富的回复。此外,情感可以以显式或隐式方式表达。例如,“你/根本/不懂/生活!(Y ou do not understand life at all!)“。当我们整体阅读这句话时表达愤怒,而“美丽(beautiful)”或“开心(happy)”是代表“喜欢”或“快乐”的强烈情感词。

4.7 对CDL的进一步分析
在这里,我们进行进一步的分析,以显示这项任务的一些特点和CDL的效果。表7列出了每个类别预训练后的情感词典大小和分类准确率(N(正确预测)/类别大小)。我们可以看到,分类准确率与情感词典的大小并不完全相关,表明情感表达可能是内隐的,也可能是外显的。

为了更好地说明CDL的学习效率,我们在验证集上绘制了情感-Acc的变化。如图2所示,CDL有效地加速了学习,并且始终优于CDL-DL。

5 相关工作
由传统的开放领域对话系统生成的回复通常是安全和通用的。为了产生多样化和信息量丰富的回复,研究人员试图或者导入用于模型构建的隐变量,或者利用一些额外的知识,例如句子类型、人物角色、情感、文档和知识三元组/图。本文主要涉及两个方面的研究:情感回复生成和自然语言处理中的对偶学习。
5.1 情感回复生成
早期研究已经证明,具有适当情感表达和反应的对话系统可以直接提高用户满意度(Prendinger和Ishizuka,2005;Prendinger等人,2005),并有助于有效用户的表现(Partala和Surakka,2004)。Polzin和Waibel(2000)和Polzin和Waibel(2000)使用基于规则的方法从会话语料库中选择情感回复,但这些规则很难扩展到大型语料库。随着深度学习的到来,一些研究人员利用神经网络来解决这个问题(Ghosh等人,2017;Hu等人,2017;周和王,2018;Sun等人,2018)。此外,Valence, Arousal, and Dominance(V AD)词典(Warriner等人,2013;Mohammad,2018)被嵌入到序列到序列模型(Sutskever等人,2014)中,以提供额外的情感信息(Asghar等人,2018;钟等人,2019年)。
由上述研究产生的回复可以简单地延续查询的情感。为了产生情感可控的回复,周等人(2018a)考虑了大规模对话中的情感因素,并提出ECM根据不同的给定情感生成回复。在那之后,科伦坡等人(2019年)使用VAD嵌入来增强ECM,并修改了损失函数和解码过程。宋等人(2019年)使用基于词汇的注意力机制和基于单词的分类器来提高情感表达能力。
5.2 自然语言处理中的对偶学习
He等人(2016年)首次提出了对偶学习(DL)用于机器翻译,将源语言到目标语言的翻译和目标语言到源语言的翻译视为双重任务。在那之后,唐等人实现了一个用于问答系统的对偶框架。张等人(2018)和崔等人(2019年)都在对话生成任务中使用类似的想法来产生连贯但不安全的回复,因为他们发现更多样化和更具体的回复通常被转换回给定查询的可能性更高。罗等人(2019b)和罗等人(2019a)在非监督文本样式转换中利用DL来缓解对并行数据的需求。
我们的方法与5.1节和5.2节中的方法不同之处在于:(1)通过DL方法同时考虑情感表达和内容一致性。(2)不把查询看作一个没有情感的句子,我们利用查询的情感,帮助建模情感的转移和连贯,从而提高回答的质量。(3)为了更好地模拟查询和回复之间情感和内容的变化,将DL方法与课程式学习相结合,提高了学习的有效性和通用性。
6 结论
在本文中,我们提出了一种新的框架课程式对偶学习,以控制的方式产生情感回复。由于现有方法只关注目标标签的情感表达,而没有考虑查询的情感,导致安全回复问题恶化,损害了内容的一致性。CDL通过对偶学习利用两种奖励同时提升情感和内容。此外,在课程式学习的支持下,它可以更有效率。实验结果表明,CDL能够产生流畅、连贯、信息丰富的情感回复。
对偶学习:https://zhuanlan.zhihu.com/p/26618637、https://www.msra.cn/zh-cn/news/features/tie-yan-liu-dual-learning-20161223
课程式学习:https://zhuanlan.zhihu.com/p/114825029、https://zhuanlan.zhihu.com/p/133332379
MLE:https://www.cnblogs.com/zongfa/p/10294867.html、https://blog.csdn.net/GongPF/article/details/88827692
reinforcement learning:https://blog.csdn.net/extremebingo/article/details/79373740
policy gradient:https://zhuanlan.zhihu.com/p/21725498、https://blog.csdn.net/qq_30615903/article/details/80747380
Teacher Forcing:https://zhuanlan.zhihu.com/p/93030328、https://blog.csdn.net/qq_30219017/article/details/89090690