http://blog.csdn.net/emilmatthew/article/details/774458
模糊聚類分析的實現(CuteFuzzy V0.5 Released)
EmilMatthew(EmilMatthew@126.com)
摘要:
在本文中,介紹了基本的模糊聚類分析及模糊聚類圖的繪制的算法及其程序。
關鍵詞: 模糊聚類分析,聚類圖
The implement of fuzzy cluster analysis(CuteFuzzy V0.5 Released)
EmilMatthew(EmilMatthew@126.com)
Abstract:
In the paper , I realize the basis part of fuzzy cluster analysis and the drawing of clustering picture , which are introduced both in algorithms and the codes.
Key Words: Fuzzy Cluster Analysis , Cluster Map
1前言:
1.1模糊數學簡介:
模糊數學是伴隨著上世紀五六十年代興起的控制論、信息論、系統論(俗稱「老三論」)而形成的一種分析統計數據以及給出決策的方法。模糊數學公認的創史人是Lotfi Zadeh教授。

他對該門學科的開山之作是:
Zadeh, Lotfi A., "Fuzzy Sets ," Information and Control, Vol. 8 (1965), pp. 338-353.
(該文可以在下面這個網址下載http://www-bisc.cs.berkeley.edu/)
模糊數學對於現實的意義,直觀的理解可以主要從以下兩個方面進行:
控制:舉個例子來說,比方說:一輛有模糊控制系統的火車,將能理解這樣的命令------「比平常的速度加快一點」,這加快,便是一個模糊的概念,以往的控制系統,如果不給出加快多少或者是加快的呈度,是很難完成這樣的任務的。
決策與分析:比方說,眼前有一堆學生的考試成績資料,如果要做一次針對學生學習能力的分析(雖然未必全能從考試成績反映出來),要求給出將學習成績好,較好,一般,較差,很差的學生進行分類,即將各個學生劃進相應的「群落」中,以便於教師更好的組織教學工作。這裡,就可以用模糊聚類的方法來解決。
在學科分類上,與模糊數學較近的方法主要是軟計算方面的一些方法,如人工神經網絡、遺傳算法、DNA計算等。它們在解決一些常用方法無法或難以解決的問題時,有相當不錯的效果。
模糊數學主要可以解決的問題有:數據的分類,模式識別,模糊決策與控制等。再舉一些例子來說明吧:如可以用C-MEAN法來對一幅圖片進行分割,提取其中的有效信息(聚類分析);再如,有世界各地的山區的土質的各方面的數據,需要分析哪些地區的土質情況較為接近(聚類分析)。
1.2聚類分析:
聚類分析的概念主要是來自多元統計分析,例如,考慮二維坐標系上有散落的許多點,這時,需要對散點進行合理的分類,就需要聚類方面的知識。
模糊聚類分析方法主要針對的是這樣的問題:對於樣本空間P中的元素含有多個屬性,要求對其中的元素進行合理的分類。最終可以以聚類圖的形式加以呈現,而聚類圖可以以手式和自動生成兩種方式進行,這裡采用自動生成方式,亦是本文的程序實現過程中的一個關鍵環節。
2模糊聚類的步驟及其關鍵算法:
這裡所實現的基本的模糊聚類的主要過程是一些成文的方法,在此簡述如下:
對於待分類的一個樣本集U={u1,u2,...,un},設其中的每個元素有m項指標,則可以用m維向量描述樣本,即:ui={ui1,ui2,...,uim}(i=1,2,...,n)。則其相應的模糊聚類按下列步驟進行:
1) 標准化處理,將數據壓縮至(0-1)區間上,這部分內容相對簡單,介紹略。(參[1])
2) 建立模糊關系:
這裡比較重要的環節之一,首先是根據「距離」或其它進行比較的觀點及方法建立模糊
相似矩陣,主要的「距離」有:
Hamming 距離: d(i,j)=sum(abs(x(i,k)-x(j,k))) | k from 1 to m
(| k from 1 to m表示求和式中的系數k由1增至m,下同)
Euclid 距離: d(i,j)=sum((x(i,k)-x(j,k))^2) | k from 1 to m
非距離方法中,最經典的就是一個夾角余弦法:
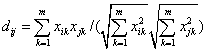
最終進行模糊聚類分析的是要求對一個模糊等價矩陣進行聚類分析,而由相似矩陣變換
到等價矩陣,由於相似矩陣已滿足對稱性及自反性,並不一定滿足傳遞性,則變換過程主要進行對相似矩陣進行滿足傳遞性的操作。使關系滿足傳遞性的算法中,最出名的,就是Washall算法了,又稱傳遞閉包法(它的思想在最短路的Floyd算法中亦被使用了)。
算法相當簡潔明了,復雜度稍大:O(log2(n)*n^3),其實就是把一個方陣的自乘操作,只不過這裡用集合操作的交和並取代了原先矩陣操作中的*和+操作,如下:(matlab代碼)
%--washall enclosure algorithm--%
unchanged=0;
while unchanged==0
unchanged=1;
%--sigma:i=1:n(combine(conj(cArr(i,k),cArr(k,j))))
for i=1:cArrSize
for j=1:cArrSize
mergeVal=0;
for k=1:cArrSize
if(cArr(i,k)<=cArr(k,j)&&cArr(i,k)>mergeVal)
mergeVal=cArr(i,k);
elseif(cArr(i,k)>cArr(k,j)&&cArr(k,j)>mergeVal)
mergeVal=cArr(k,j);
end
end
if(mergeVal>cArr(i,j))
copyCArr(i,j)=mergeVal;
unchanged=0;
else
copyCArr(i,j)=cArr(i,j);
end
end
end
%--copy back--%
for i=1:cArrSize
for j=1:cArrSize
cArr(i,j)=copyCArr(i,j);
end
end
end
3) 建立完等價矩陣cArr後,接下來就是聚類的過程了,聚類的方法其實是相當好做的。
取門限值limitLine,值由1遞減至0遞減幅度為0.1。在每一輪聚類過程中,凡是至cArr(i,j)>=limitLine的位置在0-1矩陣中均置1,而<limitLine的值都置0。若有相同的兩列或多列,即表示這些列彼此之前接近,則列的標號即代表原來的元素,作為一組中的元素加以記錄。不斷重復上述過程直至最終歸為一類。
聚類算法可以被描述成一個找出等價類的算法,復雜度O(n^2)(仍有改進的余地),描述如下:(matlab code)
%--cluster--%
limitLine=1; 『聚類門限起始值
limitStep=0.1; 『聚類門限步進值
expectedLimit=0.6; 『聚類下限值
comArr=zeros(1,cArrSize); 『將各列的值用一個唯一的二進制數表示,便於比較
groupIndentifyArr=zeros(1,cArrSize); 』當前該輪聚類分析中各元素所在的組號
groupDelegateArr=zeros(1,cArrSize); 『當前該輪聚類分析中各組的代表元素
groupNum=1;
while(limitLine>=expectedLimit)
%----construct Boolean array---
for i=1:cArrSize
for j=1:cArrSize
if(cArr(i,j)<limitLine)
cBoolArr(i,j)=0;
else
cBoolArr(i,j)=1;
end
end
end
%--make the comparation arr--%
for j=1:cArrSize
tempVal=0;
for i=1:cArrSize
tempVal=tempVal+cBoolArr(i,j)*2^(i-1);
end
comArr(j)=tempVal;
end
%--core part: pation the equivalence class--%
%--initialize part--%
groupIndentifyArr(1)=1;
groupDelegateArr(1)=1;
groupNum=1;
%--main part of the algorithm--%
for i=2:cArrSize
flag=0;
for count=1:groupNum %如果當前的元素屬於已分出的組,則並出其所在的組
if(comArr(groupDelegateArr(count))==comArr(i))
groupIndentifyArr(i)=count;
flag=1;
break;
end
end
%如果當前的元素不屬於任何已分出的組,則將其置入新組,並選該元素所為新組的代表元素
%--attention ,in matlab ,the exit val for count in for iteration is groupNum--%
if(flag==0) %--here can't use count==groupNum+1 as a judgement
groupNum=groupNum+1;
groupDelegateArr(groupNum)=i;
groupIndentifyArr(i)=groupNum;
end
end
limitLine=limitLine-limitStep;
end
3聚類分析圖的繪制算法:
3.1沒有交叉元素序列的生成算法:
在這相應實現程序中,最具有些挑戰意義的就是聚類圖的自動繪制的方法了。自動繪制可以考慮兩種方式,一種即可元素號按從小到大的順序排列,遇到有交叉的地方以一個半圓加以區分,這種方式相對容易,但實現過於煩瑣。另一種方式就是將所有元素序號重新排列成一種在繪制過程中沒有交叉的序列,從而進行繪制。從而,「繪」這個動作會變得很輕松,主要的精力將會被集中到有點tricky的「排成一個沒有交叉的序列」上。顯然,這種方式的實現在算法上要較第一種有挑戰和美感得多。所以,我自然是選這種方法來做的。
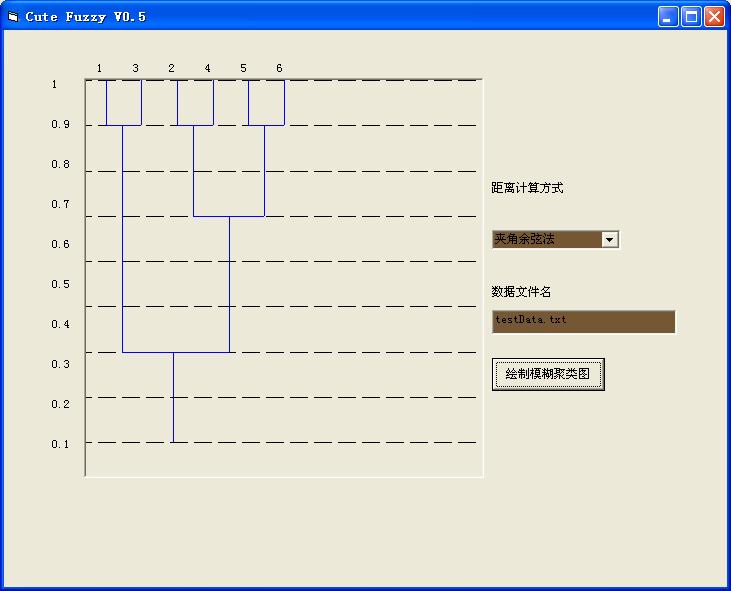
圖1
這裡最為關鍵的,就是如何理解「沒有交叉的序列」,用本文中出現頻率極高的一個詞語去形容,這個表述有點模糊,相對於有序,分類等概念,這個「沒有交叉的序列」,並不是一眼就能明了的概念。
首先問一個問題,「沒有交叉的序列」是否一定求得?對於絕大多數的數據,是可求得的,只有極少量的數據,在特定的方法中無法求得。簡單起見,先看一個沒有交叉的例子,即原始的元素序列就是最終的聚類元素序列的:
設第n輪聚類中,各元素有如下分類:{1 2 3}{4 5} (用{}表示一組)
在第n+1輪聚類中,各元素的分類為 {1 2 3 4 5}
再看一個有交叉的情況
n輪: {1} {2 3} {4 5}
n+1輪: {1 4 5} {2 3}
顯然,如果元素的序列不按1 4 5 2 3的序列排列的話,將會出現交叉,而本算法保證了其最終形成了沒能交叉的序列。
最後這個問題一定要說明一下,就是哪種情況叫「沒有交叉的序列無法求得」,在我測
試的數據中(四分數據樣本,各測三種方式),出現唯一的一種這樣的圖形(如圖2):仔細分析後,不是畫聚類圖的算法出了問題,而是這種方法的確是屬於「沒有交叉的序列無法求得」這樣一種情況,不知「沒有交叉的序列無法求得」是否真實存在或蓋因我的程序有不完備之處,望高人指點。(「沒有交叉的序列無法求得」均出現在最大最小距離的使用中)
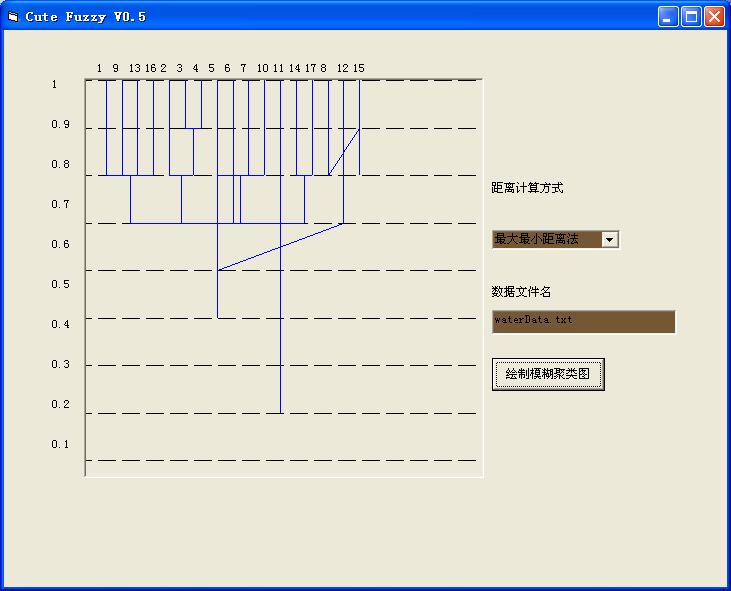
圖2
舉例說明「沒有交叉的序列無法求得」:
n輪: {1 2 3 }{4 5}
n+1輪:{1 2 3 4} {5}
這樣,就相當於元素4在前一輪和元素5是同組的,而到了下一輪分析中,反而不是了,
這就無法繪制我們所要求的聚類圖了。其中具體原因,有待深入探求,亦請高人指點。
所以,下面的算法都是在「沒有交叉的序列」一定可以求得的基礎上展開的,不妨將其
稱為性質1。
回到前面的分析中,在性質1的前提下,可以看到,「交叉」這個圖像上出現的情況,
反映到數據中,實際上就意味著有的集合擴張了,即有新的元素並入了原來的集合中,使得一些集合消失,一些集合擴大,最終在逐輪的聚類中,將導致並為一組,即聚類為一組。
這個合並的動作用抽象數據結構,可以這樣描述:
設需要被聚類的元素為e(1)~e(k),第n次聚類中,已有分組g(1)~g(m)
則對於第n+1次聚類過程中,有相應的聚類算法如下,復雜度O(k*m):
For i = 1 To k Step 1
checkArr(i) = False 『標識元素是否已處理的數組
Next i
j = 1 'cur seqArr Index
k = 1 'group Index
While (還有未被標記的元素)
For k=1 to m setp 1
首先查看g(k)中的元素,如未被標記
{
則將其加入g』(j)
checkArr(當前g(k)元素的下標)=true
}
再查看在第n+1次迭代中,有無新加入g』(j)的元素,如果有且未標記
{
將其加入g』(j)
checkArr(新加入g』(j)的元素的下標)=true
}
Next m
j=j+1
Wend
這裡尤其要注意的是這裡所采用的集合必須為元素存放策略為「先來位置靠前」的集合,
不妨簡記為FIPF(first in position first) ,即越先加入的元素在被訪問時就越在前面。如果集合內部采用的是隊列這種結構來存放數據,則最終數據將以類似加入隊列的形式加入到隊列中,讀取時則類似於出隊(只是不應真的從集合數據中去除)。
為了更進一步說明這裡應采用FIPF集合這樣一種數據結構,這裡舉個例子說明:
設第n次聚類中,聚類集合的情況如下:
{1 9 13 16} … {5}
在第n+1次聚類中,元素5加入到了第一個集合中即有:
{1 9 13 16 5} 這樣是不會有交叉的(圖3)。
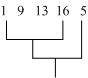
圖3
如果集合不是FIPF,通常會自然的按照元素序號大小(數組,下標遍歷,很容易就造成這並不期待的有序)在集合內部排布,則第一個集合中的元素存放情況就變成了:
{1 5 9 13 16} 這樣顯然出現了交叉(圖4)。
圖4
由於每一步聚類都保證了當前的聚類圖中無交叉的情況出現,所以在最終聚類成一類
時,相應的元素的序列即為各元素間無交叉的聚類序列。
3.2聚類圖的繪制算法:
當得到了各元素間無交叉的聚類序列後,再繪制聚類圖就容易多了。
我采用一個隊列q作為輔助數據,其中存放了每次聚類過程中各集合的中的數據的個數,而每次聚類過程中的集合的順序,則是由3.1中完成的無交叉的聚類序列所決定的。
繪制聚類圖的算法如下:(請注意,這裡的代碼只是偽碼,部分變量名與源代碼中的實
現時的意義並不一致)
說明:setPointArr對應於當前輪中各集合對應的繪制點的x,y值。
preI = 1 『指向當前輪的下標
descI = 1 『指向下一輪的數據點數組的下標
While (隊列中存放的「當前輪中各集合中的元素個數」的數據沒有用完)
If (前一輪的集合(preI)在當前輪中需要合並) Then
找到需要合並的集合個數m,由性質1,可知這m個集合就位於集合preI的右側。
在setPointArr(preI)和setPointArr(m)間劃一直線
在setPointArr(preI)和setPointArr(m)沒Y軸方向前進stepY
記錄新的集合對應的x,y及元素的個數至setPointArr2(descI)
preI = preI + m+1
Else
setPointArr(preI)沿Y軸方向前進stepY個單位
preI = preI + 1
End If
descI = descI + 1
Wend
拷貝setPointArr2至setPointArr
4算法的應用效果:
采用本算法對2000及2005年全國大學生數學建模試題中可以使用模糊聚類分析之處進
行測試:
測試1:2000CUMCM 試題A DNA的分類:對試題中給出的已知樣本的20組DNA序
列(已分成兩類),進行測試。采用夾角余弦法進行分類,取得到了較好的效果,如圖 ,除了第四號DNA序列分類不明顯外,其余元素DNA序列分類明確且分類效果好(圖5):
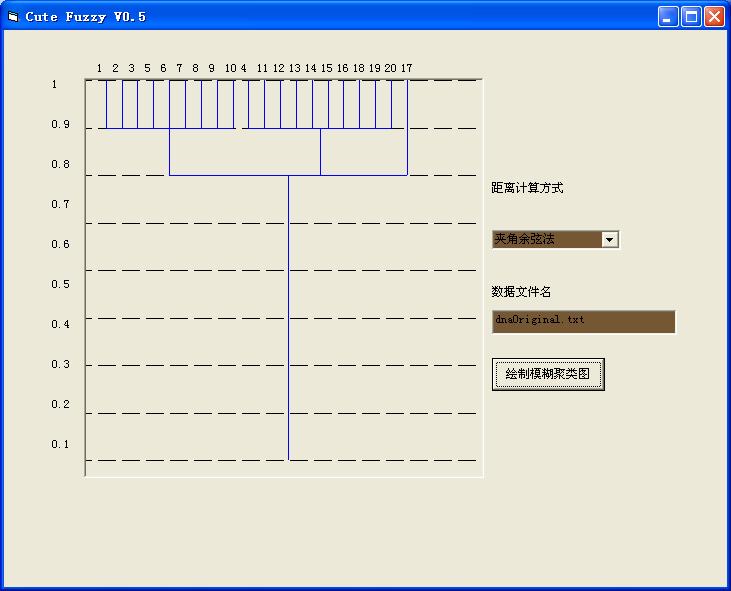
圖5
測試2:2005CUMCM 試題A長江水質的評價。在第一問中對數據進行內梅羅平均的
基礎上,采用夾角余弦法,進行分類(圖6):
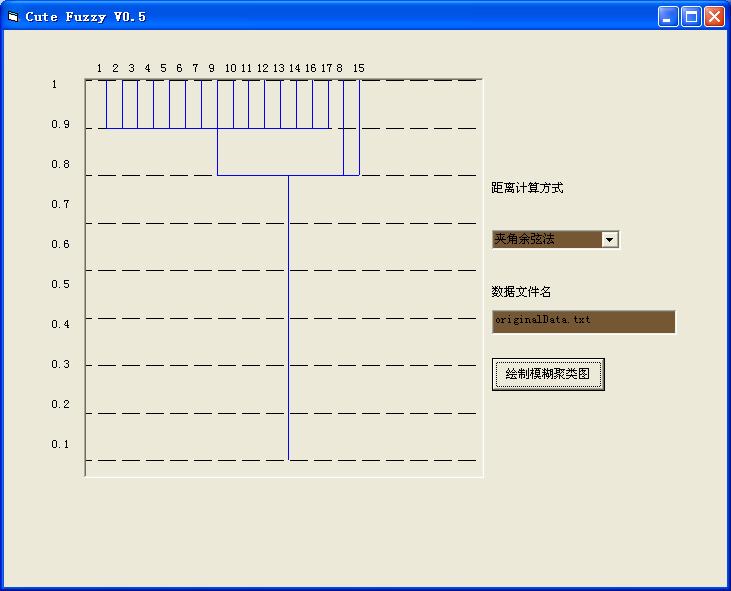
圖6
參考下表,可知上述分類方法很好的將污染最為嚴重的8號站點四川樂山岷江大橋及15號站點江西南昌滁槎從其余站點中區分了出來。
| 表1:各個觀測點的水監測項目的內梅羅平均值表 單位:mg/L |
||||||
| 點位名稱 |
主要監測項目(單位:mg/L) |
主要污染物 |
|
|||
| pH* |
DO |
CODMn |
NH3-N |
|
||
| 四川攀枝花龍洞 |
8.4861 |
8.0635 |
4.6436 |
0.8723 |
|
|
| 重慶朱沱 |
8.2112 |
8.156 |
3.4464 |
0.5035 |
|
|
| 湖北宜昌南津關 |
8.0301 |
7.5694 |
4.5774 |
0.4831 |
|
|
| 湖南岳陽城陵磯 |
7.9902 |
7.657 |
5.0166 |
0.3833 |
|
|
| 江西九江河西水廠 |
8.0176 |
7.0155 |
2.8972 |
0.2221 |
|
|
| 安徽安慶皖河口 |
7.5982 |
6.7669 |
3.9768 |
0.3198 |
|
|
| 江蘇南京林山 |
7.776 |
6.7339 |
3.0676 |
0.2371 |
|
|
| 四川樂山岷江大橋 |
7.8297 |
4.5891 |
7.9214 |
1.5451 |
DO,CODMn,NH3-N |
|
| 四川宜賓涼姜溝 |
8.4404 |
7.5606 |
5.9785 |
1.4466 |
NH3-N |
|
| 四川瀘州沱江二橋 |
8.021 |
5.2399 |
5.1045 |
3.9312 |
NH3-N |
|
| 湖北丹江口胡家嶺 |
8.2831 |
8.2727 |
2.2435 |
0.1185 |
|
|
| 湖南長沙新港 |
7.3638 |
5.8901 |
3.8851 |
1.2309 |
NH3-N |
|
| 湖南岳陽岳陽樓 |
8.1496 |
7.0107 |
5.9527 |
0.6924 |
|
|
| 湖北武漢宗關 |
8.0039 |
6.0935 |
4.7888 |
0.341 |
|
|
| 江西南昌滁槎 |
8.2554 |
4.077 |
6.5727 |
17.4228 |
DO,CODMN,NH3-N |
|
| 江西九江蛤蟆石 |
7.9982 |
6.9485 |
7.0231 |
0.5152 |
CODMN |
|
| 江蘇揚州三江營 |
7.9969 |
6.5721 |
4.3139 |
0.3955 |
|
|
相較於其它方法,夾角余弦法是一種簡單而聚類效果又好的算法,在搜索引擎的實現中,有一種很長用的區分文檔關聯度的方法也是用的夾角余法。
5關於程序:
程序采用VB6開發,代碼尚有改進之處,希望高人指出不足和可改進之處(比方說,造成沒有交叉的序列無法求得的原因究竟是什麼),謝謝。
目前程序最多區分20組,你可以很方便的對這個限制進行擴充,添加一個label2控件數組即可。
參考文獻:
[1]肖位樞,模糊數學基礎及其應用,航空工業出版社,1992
程序完成日:06/06/04
文章完成日:06/06/05
附錄:
1測試程序下載:
http://www.newdreamworks.com/emilmatthew/MyPapers/FuzzyClusterV3[VB].rar
若直接點擊無法下載(或瀏覽),請將下載(或瀏覽)的超鏈接粘接至瀏覽器地( 推薦MYIE或GREENBORWSER)址欄後按回車.若不出意外,此時應能下載.
若下載中出現了問題,請參考:
http://blog.csdn.net/emilmatthew/archive/2006/04/08/655612.aspx
後記:
1Lotfi Zadeh

Lotfi Zadeh教授不僅僅關注於模糊、控制論及軟計算方面的學術工作,對於社會,對於青年人的成長也是抱以相當大的熱情的,有機會不訪去找一下和他相關的文章來讀一下,相信定能獲益非淺。
2如何看到高級分析方法:
雖然像人工神經網絡、DNA計算等。它們在解決一些常用方法無法或難以解決的問題時,有相當不錯的效果。但是,我們也不能對這些方法過於熱衷。遇到什麼問題,想都不想,就以為用個FUZZY、ANN這樣的「大招」就可以解決戰斗了。這樣的情緒是有害的。一者,這就是在套「公式」,而絕非什麼科學研究,喪失了最根本的科學研究中的探索與進取的精神;二者,這類方法雖然已能解決不少問題,但本身的體系遠沒有達到像經典物理學那樣的宏大而又精致的地步,其理論還有相當多的問題需要去解決。當然,在能力和時間允許的情況下,這些方法仍是值得掌握並使用的,我只是想提醒:千萬不要把它們當成包治百病的萬能藥水,而放棄了自己對所解決問題的探索。
3失敗的教訓:
由於對於該程序可能遇到的問題沒有經過縝密的思考,關鍵在於對「沒有交叉的聚類圖」這個問題沒有清楚的認識到底意味著什麼。導致最終實現時調錯了許多地方,無謂的浪費了許多時間,尤如身陷泥潭而不可自拔。另外,在數據結構的實現上,亦較抽象層的模型相對為遙遠,給代碼層的實際編制工作帶來了一定的麻煩,這些,都是在以後的程序編制過程中,所應深刻吸取的教訓。