ЙйЗНЮФЕЕЃК
Hadoop ЈC Apache Hadoop 2.7.5
ЁЖHadoopШЈЭўжИФЯЁЗЕкЫФАцжаЮФАцpdfЃК
СДНгЃКhttps://pan.baidu.com/s/1WDWgZLlErWf6S-9JJwiAqQ
ЬсШЁТыЃКumnh
ВЮПМПЮГЬЃКЁОКУГЬађдБЁПзюаТДѓЪ§ОнHadoopШыУХЛљДЁЪгЦЕНЬГЬЃЌЪЪКЯСуЛљДЁздбЇЕФДѓЪ§ОнПЊЗЂПЮГЬ_пйСЈпйСЈ_bilibili
ЯТдиhadoop:
https://hadoop.apache.org/releases.html

ПЩвдЯТдизюаТАцБОЃЌвВПЩвддкЭјеОжаевЕНЗЂВММЧТМРяздМКЯывЊЕФАцБОЃЌетРяЮвЯТдиЕФЪЧhadoop-2.7.5.tar.gzАцБОЁЃ
- зМБИШ§ЬЈЛњЦїгУвдДюНЈ3ИіНкЕуЕФhadoopМЏШК
| Hostname | IP | Role |
| hadoop01 | 192.168.126.132 | NameNode DataNode NodeManager |
| hadoop02 | 192.168.126.133 | SecondaryNameNode NodeManager |
| hadoop03 | 192.168.126.134 | DataNode NodeManager |
- АВзАJDK(АВзАВНжшВЮПМЃКhttps://blog.csdn.net/QYHuiiQ/article/details/86560498)

- ЙиБеЗРЛ№ЧНЃЌвдБЃжЄШ§ЬЈНкЕужЎМфПЩвдЯрЛЅЭЈаХ
[root@localhost wyh]# systemctl stop firewalld
[root@localhost wyh]# systemctl disable firewalld
[root@localhost wyh]# systemctl status firewalld
[root@localhost wyh]# vi /etc/selinux/config
SELINUX=disabled
- аоИФжїЛњУћ
[root@localhost wyh]# vi /etc/hostname
hadoop01
#жиЦєЪЙжЎЩњаЇ
[root@localhost wyh]# reboot
#ВщПДжїЛњУћ
[root@hadoop01 ~]# hostname
hadoop01
[root@hadoop02 ~]# hostname
hadoop02
[root@hadoop03 ~]# hostname
hadoop03
- ЬэМгжїЛњipгыжїЛњУћжЎМфЕФгГЩфЙиЯЕ
[root@hadoop01 ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6192.168.126.132 hadoop01
192.168.126.133 hadoop02
192.168.126.134 hadoop03#НЋХфжУЮФМўЗжЗЂИјСэЭтСНЬЈЛњЦї
[root@hadoop01 ~]# scp /etc/hosts root@hadoop02:/etc/hosts
[root@hadoop01 ~]# scp /etc/hosts root@hadoop03:/etc/hosts
- ХфжУУтУмЕЧТМ
#ЪЙгУrsaМгУмММЪѕЩњГЩЙЋдПКЭЫНдПЃЛУќСюжДааЙ§ГЬжаШЋВПЪфШыЛиГЕМДПЩЃЈЗжБ№дкШ§ЬЈЛњЦїЩЯжДааЃЉЁЃ
[root@hadoop01 ~]# ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:P3ZWmLDVyGvYaWw8SQemtnkr2bHWmaGm5pIzBat+bIY root@hadoop01
The key's randomart image is:
+---[RSA 2048]----+
| o |
| + + |
| + = o |
| .. % B |
| So= ^ o |
| ...B O + |
| + o* X + |
| E X..O |
| ..+ *o |
+----[SHA256]-----+#НјШыhomeФПТМЯТЕФ.sshвўВиФПТМЃЌЪЙгУssh-copy-idУќСюНЋжїЛњ1ЕФЙЋдПЗжЗЂИјжїЛњ2ЃЌЪЙЕУжїЛњ1ПЩвдЪЕЯжЖджїЛњ2ЕФУтУмЕЧТМ
[root@hadoop01 ~]# cd
[root@hadoop01 ~]# ll -a
total 28
dr-xr-x---. 3 root root 147 Mar 7 07:32 .
dr-xr-xr-x. 17 root root 244 Mar 7 08:03 ..
-rw-------. 1 root root 1371 Feb 28 17:03 anaconda-ks.cfg
-rw-------. 1 root root 830 Mar 7 08:03 .bash_history
-rw-r--r--. 1 root root 18 Dec 28 2013 .bash_logout
-rw-r--r--. 1 root root 176 Dec 28 2013 .bash_profile
-rw-r--r--. 1 root root 176 Dec 28 2013 .bashrc
-rw-r--r--. 1 root root 100 Dec 28 2013 .cshrc
drwx------. 2 root root 57 Mar 7 08:26 .ssh
-rw-r--r--. 1 root root 129 Dec 28 2013 .tcshrc
[root@hadoop01 ~]#
[root@hadoop01 ~]# cd .ssh/
[root@hadoop01 .ssh]# ll
total 12
-rw------- 1 root root 1679 Mar 7 08:26 id_rsa
-rw-r--r-- 1 root root 395 Mar 7 08:26 id_rsa.pub
-rw-r--r--. 1 root root 694 Mar 7 08:18 known_hosts
[root@hadoop01 .ssh]#
[root@hadoop01 .ssh]# ssh-copy-id hadoop02
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub"
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@hadoop02's password:Number of key(s) added: 1Now try logging into the machine, with: "ssh 'hadoop02'"
and check to make sure that only the key(s) you wanted were added.#ЗжЗЂГЩЙІЃЌГЂЪдЕЧТН
[root@hadoop01 .ssh]# ssh hadoop02
Last login: Mon Mar 7 08:07:55 2022 from 192.168.126.100#ГЂЪддкжїЛњ2ЩЯНЋЙЋдПИДжЦИјжїЛњ3(root@ПЩвдЪЁТдВЛаДЃЌвђЮЊФЌШЯОЭЪЧвдrootеЫЛЇНјааВйзї)
[root@hadoop02 ~]# ssh-copy-id root@hadoop03
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub"
The authenticity of host 'hadoop03 (192.168.126.134)' can't be established.
ECDSA key fingerprint is SHA256:G87zFtUxK/e6e1PR5z23FSTd5FnEZn7Df9m4WDxzaWc.
ECDSA key fingerprint is MD5:f0:df:12:7b:ad:f0:68:53:d7:69:2a:a7:08:e2:6c:af.
Are you sure you want to continue connecting (yes/no)? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@hadoop03's password:Number of key(s) added: 1Now try logging into the machine, with: "ssh 'root@hadoop03'"
and check to make sure that only the key(s) you wanted were added.[root@hadoop02 ~]# ssh hadoop03
Last login: Mon Mar 7 08:08:40 2022 from 192.168.126.100гЩгкУтУмВйзїЪЧЕЅЯђЕФЃЌЫљвдашвЊдкУПИіНкЕуЩЯЖМвЊЖдСэЭтСНИіНкЕужДааssh-copy-idУќСюЪЙжЎПЩвдЫЋЯђУтУмЃЌвВПЩвдЖдздМКБОЛњвВжДааcopyУќСюЪЙЦєЖЏМЏШКЪБЖдздМКвВжДааУтУмЃЌетРяОЭЪЁТдгрЯТЕФЗжЗЂВйзїЁЃЗжЗЂжЎКѓЃЌПЩвдПДЕН.sshФПТМЯТЖрСЫвЛИіauthorized_keysЮФМўЃЌетИіЮФМўОЭЪЧгУРДБЃДцЦфЫћНкЕуЕФЙЋдПЁЃid_rsa.pubЪЧздМКЕФЙЋдПЃЌid_rsaЪЧздМКЕФЫНдПЁЃ
[root@hadoop01 .ssh]# ll
total 16
-rw------- 1 root root 790 Mar 7 08:50 authorized_keys
-rw------- 1 root root 1679 Mar 7 08:26 id_rsa
-rw-r--r-- 1 root root 395 Mar 7 08:26 id_rsa.pub
-rw-r--r--. 1 root root 694 Mar 7 08:18 known_hosts

УтУмЕЧТМЕФЪЕЯждРэЃК
жїЛњ01НЋздМКЩњГЩЕФЙЋдПЗЂЫЭИјжїЛњ02ЃЌ02ЪеЕН01ЗЂЫЭЕФЙЋдПжЎКѓНЋ01ЕФЙЋдПБЃДцЕНздМКЕФauthorized_keysЮФМўжаЁЃЕБ01ЯывЊУтУмЕЧТМ02ЪБЃЌЛсЯђ02ЗЂЫЭЧыЧѓЃЌЧыЧѓУќСюжаАќКЌСЫ01здМКЕФipЁЂжїЛњЕШаХЯЂЃЌ02ЪеЕН01ЗЂЫЭЕФЕЧТМЧыЧѓКѓЃЌЛсШЅздМКЕФauthorized_keysжаВщевгаУЛга01ЖдгІЕФipЕШЕЧТНаХЯЂЃЌШчЙћВщЕНСЫга01ЕФаХЯЂЃЌФЧУДОЭЛсЫцЛњЩњГЩвЛИізжЗћДЎВЂгУ01ЕФЙЋдПНјааМгУмЃЌНЋМгУмКѓЕФзжЗћДЎЗЕЛиИј01ЃЌ01ЪеЕН02МгУмКѓЕФзжЗћДЎКѓЃЌЛсгУздМКЕФЫНдПЖдИУзжЗћДЎНјааНтУмЃЌШчЙћздМКЕФЫНдППЩвдНтУмГЩЙІЃЌОЭНЋНтУмКѓЕФзжЗћДЎЗЕЛиИј02ЃЌ02ЪеЕНЗЕЛиЕФзжЗћДЎКѓЛсгыздМКзюПЊЪМЩњГЩЕФЫцЛњзжЗћДЎНјаабщжЄЃЌШчЙћбщжЄГЩЙІЃЌОЭБэУїдЪаэ01УтУмЕЧТМЁЃ
- МЏШКНкЕуМфЕФЪБМфЭЌВН
МЏШКМфЕФЪБМфБиаыБЃГжЭЌВНЃЌЫћУЧжЎМфЕФЪБМфВюВЛФмГЌЙ§30sЁЃвдЦфжавЛЬЈЛњЦїЕФЪБМфЮЊзМЃЌНЋСэЭтСНЬЈЛњЦїгыЦфЭЌВНЁЃ
дк01ЩЯАВзАntp(ЪБМфЭЌВНЗўЮёЦї)
[root@hadoop01 .ssh]# yum -y install ntpдк01ЩЯаоИФЮФМўЃК

дк01ЩЯПЊЦєntpdЗўЮёЃК
[root@hadoop01 .ssh]# systemctl start ntpdВщПДзДЬЌЃК
[root@hadoop01 .ssh]# systemctl status ntpd
дк02КЭ03ЩЯАВзАntpdateЃЌЭЌВН01ЕФЪБМфВЂЬэМгЖЈЪБШЮЮёЃК
[root@hadoop02 .ssh]# yum install -y ntpdate
[root@hadoop02 .ssh]# ntpdate -u hadoop01#ЬэМгЖЈЪБШЮЮёЪЙжЎЖЈЪБШЅЭЌВНЪБМф
[root@hadoop02 .ssh]# crontab -e
no crontab for root - using an empty one
crontab: installing new crontabЁЂ#ЪфШыiзЊЮЊБрМФЃЪНЬэМгШчЯТФкШн,* * * * *БэЪОУПЗжжгжДаавЛДЮ
[root@hadoop02 .ssh]# crontab -e
* * * * * /usr/sbin/ntpdate -u hadoop01 > /dev/null 2>&1- АВзАhadoop
[root@hadoop01 wyh]# tar -zxvf hadoop-2.7.5.tar.gz#ЬэМгШчЯТФкШн
[root@hadoop01 wyh]# vi /etc/profile
HADOOP_HOME=/usr/local/wyh/hadoop-2.7.5
PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_HOME PATH#ЪЙХфжУЩњаЇ
[root@hadoop01 wyh]# source /etc/profile#ВщПДhadoopАцБОбщжЄАВзАГЩЙІ
[root@hadoop01 wyh]# hadoop versionПЩвдНЋЩЯЪіВйзїдк02КЭ03ЩЯвРДЮжДааЃЌвВПЩвджБНгНЋНтбЙКѓЕФАВзААќКЭаоИФКѓЕФ/etc/profileЮФМўscpДЋЕНСэЭтСНЬЈЛњЦїЩЯЃЌЕЋДЋЙ§ШЅжЎКѓЛЙЪЧвЊжДааsourceУќСюЪЙХфжУЩњаЇЁЃ
- аоИФhadoopХфжУЮФМў
дкhadoopАВзААќЯТhadoop-2.7.5/share/doc/hadoop/xxxxжаЛсгаИїИіФЃПщФЌШЯЕФxxxx-default.xmlХфжУЮФМў:

ЮвУЧПЩвддкДњТыжаЛђxxx-site.xmlЮФМўжааоИФХфжУЃЌетШ§ДІХфжУдкеце§ЩњаЇЪБЕФгХЯШМЖЪЧЃКДњТыХфжУ>xxx-site.xml>xxx-default.xmlЁЃ
ЮвУЧвЊаоИФЕФХфжУЮФМўдк/usr/local/wyh/hadoop-2.7.5/etc/hadoopФПТМЯТЃК
core-site.xml
<configuration><property><!--ФЌШЯЮФМўЯЕЭГЕФУћГЦЁЃЭЈГЃжИЖЈnamenodeЕФURIЕижЗЃЌАќРЈжїЛњКЭЖЫПкЁЃИУЖЫПкЮЊПЭЛЇЖЫгУвдНЛЛЅЕФRPCЖЫПкЃЌдкhadoop 1.xжаИУЖЫПкКХФЌШЯЪЧ9000ЃЌдкhadoop2.xжаИУЖЫПкКХФЌШЯЪЧ8020ЃЌПЩвдЪЁТдВЛаД--><name>fs.defaultFS</name><value>hdfs://hadoop01:8020</value></property><property><!--hadoopдЫааЙ§ГЬжаВњЩњЕФЮФМўЫљДцЗХЕФФПТМЃЌАќРЈЮвУЧвЊДцДЂЕФЪ§ОнЖМЪЧДцЗХдкИУФПТМЯТ,ИУФПТМВЛашвЊЮвУЧздМКЪжЖЏШЅДДНЈЃЌдкhdfsИёЪНЛЏЪБЛсАяЮвУЧДДНЈЁЃФЌШЯХфжУЪЧ/tmp/hadoop-${user.name}--><name>hadoop.tmp.dir</name><value>/usr/local/wyh/hadoop-2.7.5/tmp</value></property>
</configuration>hdfs-site.xml
<configuration><!--гУгкДцЗХnamenodeЪиЛЄНјГЬЙмРэЕФдЊЪ§ОнЮФМўfsimageЃЌШчЙћетИіжЕгУЖККХИєПЊЃЌаДСЫЖрИіжЕЃЌФЧУДОЭЛсдкетЖрИіТЗОЖЯТЖМЗХвЛЗн--><property><name>dfs.namenode.name.dir</name><value>file://${hadoop.tmp.dir}/dfs/name</value></property><!--ДцЗХЪ§ОнПщЕФЮЛжУЃЌЖККХИєПЊПЩвддкЖрИіФПТМжаЖМДцДЂвЛЗн--><property><name>dfs.datanode.data.dir</name><value>file://${hadoop.tmp.dir}/dfs/data</value></property><!--ПщЕФИББОЪ§--><property><name>dfs.replication</name><value>3</value></property><!--ПщЕФДѓаЁЃЌвдзжНкЮЊЕЅЮЛ--><property><name>dfs.blocksize</name><value>134217728</value></property><!--secondaryНкЕуЕФЕижЗ--><property><name>dfs.namenode.secondary.http-address</name><value>hadoop02:50090</value></property><!--webНчУцПЩЗУЮЪЕФЕижЗ--><property><name>dfs.namenode.http-address</name><value>hadoop01:50070</value></property>
</configuration>mapred-site.xml
дЪМЪЧmapred-site.xml.templateЮФМўЃЌЫљвдЮвУЧашвЊcopyвЛЗнаТЕФВЂжиУќУћЮЊmapred-site.xmlЁЃ
<configuration><!--жИЖЈyarnзїЮЊmapreduceЕФзЪдДЙмРэЦї--><property><name>mapreduce.framework.name</name><value>yarn</value></property><!--ХфжУзївЕРњЪЗЗўЮёЦїЕФЕижЗ--><property><name>mapreduce.jobhistory.address</name><value>hadoop01:10020</value></property><!--ХфжУзївЕРњЪЗЗўЮёЦїЕФhttpЕижЗ--><property><name>mapreduce.jobhistory.webapp.address</name><value>hadoop01:19888</value></property>
</configuration>yarn-site.xml
<configuration><!--жИЖЈyarnЕФshuffleММЪѕ--><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!--жИЖЈresourcemanagerЕФжїЛњУћ--><property><name>yarn.resourcemanager.hostname</name><value>hadoop01</value></property><!--жИЖЈshuffleЖдгІЕФРр--><property><name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name><value>org.apache.hadoop.mapred.ShuffleHandler</value></property><!--ХфжУresourcemanagerЕФФкВПЭЈбЖЕижЗ--><property><name>yarn.resourcemanager.address</name><value>hadoop01:8032</value></property><!--ХфжУresourcemanagerЕФschedulerЕФФкВПЭЈбЖЕижЗ--><property><name>yarn.resourcemanager.scheduler.address</name><value>hadoop01</value></property><!--ХфжУresourcemanagerЕФзЪдДЕїЖШЕФФкВПЭЈбЖЕижЗ--><property><name>yarn.resourcemanager.resource-tracker.address</name><value>hadoop01:8031</value></property><!--ХфжУresourcemanagerЕФЙмРэдБЕФФкВПЭЈбЖЕижЗ--><property><name>yarn.resourcemanager.admin.address</name><value>hadoop01:8033</value></property><!--ХфжУresourcemanagerЕФweb uiЕФМрПивГУц--><property><name>yarn.resourcemanager.webapp.address</name><value>hadoop01:8088</value></property><!--ПЊЦєШежООлМЏЙІФм--><property><name>yarn.log-aggregation-enable</name><value>true</value></property><!--ШежОаХЯЂБЃДцдкЮФМўЯЕЭГЩЯЕФзюГЄЪБМфЃЌЕЅЮЛЮЊУы--><property><name>yarn.log-aggregation.retain-seconds</name><value>640800</value></property>
</configuration>hadoop-env.sh
#аоИФJAVA_HOME
export JAVA_HOME=/usr/local/wyh/jdk1.8.0_311yarn-env.sh
# export JAVA_HOME=/home/y/libexec/jdk1.6.0/
if [ "$JAVA_HOME" != "" ]; then#echo "run java in $JAVA_HOME"#аоИФJAVA_HOOMEJAVA_HOME=/usr/local/wyh/jdk1.8.0_311
fi
slaves
#ХфжУdatanodeНкЕу
[root@hadoop01 hadoop]# cat slaves
hadoop01
hadoop02
hadoop03
ЛиЕНЩЯвЛМЖetcФПТМЯТЃЌНЋИеВХЫљзіЕФетаЉХфжУЮФМўЕФаоИФИДжЦЕНСэЭтСНЬЈНкЕуЩЯЃК
[root@hadoop01 etc]# scp -r hadoop/ hadoop02:$PWD
[root@hadoop01 etc]# scp -r hadoop/ hadoop03:$PWD
- ИёЪНЛЏМЏШК
дкжїНкЕуhadoop01ЩЯжДааЃК
[root@hadoop01 ~]# hdfs namenode -format
ИёЪНЛЏГЩЙІжЎКѓЃЌОЭЛсЗЂЯждкcore-site.xmlжаЮвУЧХфжУЕФtmp.dirТЗОЖЯТДДНЈКУtmpФПТМЃК

- ЦєЖЏМЏШК
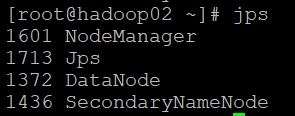
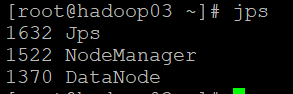
дкжїНкЕуЩЯЪЙгУЦєЖЏНХБОЦєЖЏМЏШКЃЌетбљЛсЪЙећИіМЏШКжаЕФШ§ИіНкЕуЖМЦєЖЏЃЌЦєЖЏNameNode/SecondaryNode/DataNodeетМИжжНЧЩЋЕФНјГЬЃК
#ЦєЖЏгыhdfsЯрЙиЕФНјГЬ
[root@hadoop01 current]# start-dfs.sh

ЦєЖЏЭъГЩжЎКѓПЩвдЪЙгУjpsУќСюВщПДЕБЧАНјГЬЃК



ЦєЖЏгыyarnЯрЙиЕФНјГЬЃЌжївЊЪЧResourceManager/NodeManagerЃК
[root@hadoop01 current]# start-yarn.sh


########################################################
ШчЙћЯывЊвЛДЮадЕиАбhdfsКЭyarnЯрЙиЕФНјГЬШЋВПЦєЖЏЃЌПЩвдЪЙгУЯТУцЕФУќСю(stopвВЪЧвЛбљЕФ)ЃК
[root@hadoop01 current]# start-all.sh
########################################################
ЦєЖЏГЩЙІКѓЃЌПЩвддкфЏРРЦїжаЗУЮЪwebНчУцЃЌетИіЕижЗКЭЖЫПкКХдкhdfs-site.xmlжаХфжУЕФdfs.namenode.http-addressЕФжЕ:
http://192.168.126.132:50070/

ПЩвдПДЕНМЏШКжаЕФЛюдОНкЕуЪ§ЮЊ3ЃК

зюКѓЙиБеМЏШКЃК
[root@hadoop01 current]# stop-all.sh

вдЩЯОЭЪЧДюНЈhadoopМЏШКЕФМђЕЅЪЕЯжШЋЙ§ГЬЁЃ