Author: Labyrinthine Leo?? Time: 2021.11.04
Key Words: CAT、Cognitive Diagnosis
公众号:Leo的博客城堡

欢迎各位读者关注公众号:Leo的博客城堡,如有任何问题,欢迎私聊博主互相探讨!
Quality meets Diversity:A Model-Agnostic Framework for Computerized Adaptive Testing
简称:MAAT
Reading
:[1]2021.10.20、
arXiv
:2021.01.15
cite
:5(2021.11.03)
published:
ICDM 2020
paper_url
: https://arxiv.org/pdf/2101.05986.pdf
github_url
: https://github.com/bigdata-ustc/MAAT
[1]
Bi H, Ma H, Huang Z, et al.
Quality meets Diversity: A Model-Agnostic Framework for Computerized Adaptive Testing
[C]//2020 IEEE International Conference on Data Mining (ICDM). IEEE, 2020: 42-51.

[x]
论文阅读笔记
[x]
Motivation
1、现有的计算机自适应测评(Computerized Adaptive Testing, CAT)系统往往需要观察一个特定的认知模型用于估计考生的知识水平,然后根据模型的评估设计合适的选题策略。这种指定特定认知模型的形式是非常不灵活的。
[x]
Contribution
1、设计了一种灵活的CAT框架(model-agnostic),可以嵌入不同的底层认知模型
2、提出了有效的选题策略,里面包含了三个模块组件:质量模块、多样性模块和重要性模块;解决了如何同时产生高质量和多样性做题序列的问题,能够为每位考生提供全面的知识诊断
[x]
Background
如何测量学习者的知识状态一直是与我们息息相关的问题,从小到大的各种科目的考试就是最常见的解决方案,其往往对不同测试者采用相同的卷子进行测试。虽然这种方式简单高效,但是难以保证所有选定题目的合理性,于是计算机自适应测评(Computerized Adaptive Testing)应运而生,目的就是为每个测试者量身定制合适的测试,优点包括:提高测试准确性、保证安全性和考生参与度。
CAT通常包括两个关键组件:认知诊断模型(CDM)和选题策略(Selection Strategy)。前者能够根据考生的答题表现评估学生的知识状态,后者在step by step的答题过程为考生选择适合的题目。
流程如图1所示,每个测试者均有初始的知识状态theta,每个step,选题策略会选出一道题目,然后认知模型根据测试者的作答情况对测试者进行评估,同时更新该测试者的知识状态theta,重复这个过程,直到达到最大测试长度,从而可见,每个测试者的做题序列是个性化的。

现有的CAT解决方案通常深入底层认知模型(CDMs),包括传统的项目反应理论(IRT)、多维项目反应理论(MIRT)以及神经网络认知模型(NCD)。因此大多数CAT方案都是基于底层认知诊断模型的选择,然后设计有效的选题策略,但是这种框架并不灵活,于是本文提出一种与底层模型无关性的CAT框架――MAAT。
[x]
Terminologies
其实对新人来说更关心的是CAT问题是如何进行建模描述的,下面做个简单介绍。
1、环境:
在CAT系统中,假定有测试者集合E={e1,e2,...,e|E|}和题目集合Q={q1,q2,...q|Q|},将测试者ei作答题目qj的记录用三元组r(i,j)=<ei,qj,a(i,j)>表示,这里的a(i,j)表示作答结果,如果回答正确则为1,回答错误则为0。将所有测试的记录集合记作R,测试者ei的记录为Ri。同时假定知识点集合为K={k1,k2,...,k|K|},题目和知识点的相关性可以使用二进制矩阵G表示,如果qi和kj相关,则(qi,kj)属于G。
2、状态:
基于上述静态的环境,CAT通常包含动态的状态对学习者进行自适应测试。对于测试者ei,他的作答记录Q可以被分为已测试题目集QT和待选未测试题目集QU,当他进入CAT系统时,QU=Q,QT为空。在每个step,会有一道题从QU中选出,然后测试者回答,进入下一个step,重复该过程,直到测试结束,QT就是为ei量身定制的测试序列。
3、目标:
需要注意的是CAT的根本目的是:
最大程度上评估出测试者的知识水平theta
。但是在真实数据集中并没有每个测试者知识水平的ground truth,所以只有通过测试过程让测试者在测试集上的答题结果尽可能接近其真实答题结果,也就间接达到了这个目的。
4、问题定义:
本文基于
主动学习(Active Learning)
的概念,将CAT问题建模成与认知诊断模型无关的问题,旨在解决质量和多样性问题。

给定新的测试者
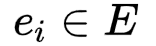 ,包含知识点K的题目池Q,任务是设计一个选题策略S每一步都选择具有最好质量和分布性的题目
,包含知识点K的题目池Q,任务是设计一个选题策略S每一步都选择具有最好质量和分布性的题目
 ,最终选择出N个问题构成集合
,最终选择出N个问题构成集合
 ,测试结束,通过计算
,测试结束,通过计算
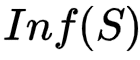 和
和
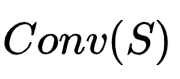 来衡量S的有效性。
来衡量S的有效性。
[x]
Algorithm
其实本文的算法部分结构非常清晰,主要是选题部分的三个子模块,质量模块(Quality Module)、分布性模块(Diversity Module)和重要性模块(Importance Module)。框架如图2所示:

先简述算法的整体框架,在测试阶段的第t步(因为CAT本质就是按步选题测试,循环进行),CAT会根据选题策略从当前测试者ei未测试过的题目集QU中选择一道题目,让ei进行回答,并根据作答情况更新该测试者的知识状态,基于更新后的知识状态,选题策略继续选择题目,重复该过程,直到达到终止条件。其中的选题策略最为关键,本文的选题策略从两个目标着手:高质量和分布性好,因此其包含三个组件:Quality Module、Importance Module和Diversity Module,分别量化题目的质量、量化知识点的重要度和对测试序列计算知识点覆盖程度。接下来对三个部分详细解释:
1、Quality Module
该模块的目的是量化候选题目的质量,并从候选题目集QU中根据质量高低选出top-KC个高质量题目构成QC。于是设计了一个质量评分函数,叫期望模型改变(Expected Model Change,EMC),其直觉上的原理就是,基于测试者当前的知识状态,如果选择的题目测试后让该测试者的知识状态改变的幅度越大,则表示这道题目的信息量非常大,也就是质量很高。挑战在于选择题目之前我们无法知道考生的反应,因此需要基于考生正确回答问题的概率来计算模型变化的期望。
公式如下,通过计算当前测试前后的指示状态改变值来反映题目的信息量。

该模块的具体的代码如下:
def expected_model_change(self, sid: int, qid: int, adaptest_data: AdapTestDataset):"""期望模型改变Args:sid: 学生idqid: 问题idadaptest_data: 测试集数据Returns:"""# 训练epoch数epochs = self.config['num_epochs']# 学习率lr = self.config['learning_rate']# 设备device = self.config['device']# 优化器optimizer = torch.optim.Adam(self.model.parameters(), lr=lr)# 只将知识状态theta设为可更新for name, param in self.model.named_parameters():if 'theta' not in name:param.requires_grad = False# 克隆theta初始权重值original_weights = self.model.theta.weight.data.clone()# 设置数据张量student_id = torch.LongTensor([sid]).to(device)question_id = torch.LongTensor([qid]).to(device)correct = torch.LongTensor([1]).to(device).float()wrong = torch.LongTensor([0]).to(device).float()# 根据sid做的题qid一条数据进行训练(以答对为目标)for ep in range(epochs):optimizer.zero_grad() # 梯度清零# 计算模型输出pred = self.model(student_id, question_id)# 计算lossloss = self._loss_function(pred, correct)loss.backward() # 反向传播optimizer.step() # 梯度下降# 记录正方向theta的值pos_weights = self.model.theta.weight.data.clone()# 将theta用初始权重替代self.model.theta.weight.data.copy_(original_weights)# 训练数据(以答错为目标)for ep in range(epochs):optimizer.zero_grad()pred = self.model(student_id, question_id)loss = self._loss_function(pred, wrong)loss.backward()optimizer.step()# 记录负方向theta的值neg_weights = self.model.theta.weight.data.clone()# 使用原始权重替换self.model.theta.weight.data.copy_(original_weights)# 模型参数回复记录梯度for param in self.model.parameters():param.requires_grad = True# 使用初始模型预测概率pred = self.model(student_id, question_id).item()# 返回概率(正负加权)return pred * torch.norm(pos_weights - original_weights).item() + (1 - pred) * torch.norm(neg_weights - original_weights).item()
将所选测试题目进行训练,加权计算答对和答错下测试者知识状态的变化值来反映题目的信息量,从而得出每道待选题的质量。
2、Importance Module
原文中是将重要性模块放在第三部分,但笔者觉得其为多样性模块的基础,因此将其前置讲解。所谓的重要性,就是指不同知识点的重要性,为了最大程度测量出测试者的知识水平,选出覆盖知识点更重要的题目是非常有必要的,因此需要解析题目与知识点的关系,从而学习知识点重要性。
文章作者的想法是:如果一个知识概念是重要的,那其相关的问题更具代表性,而如果一个题目与许多其他题目具有相似性,则可以认为该题目具有代表性(具有代表性的题目可以隐式测量出许多信息,这种直觉非常直观的)。为了量化题目的代表性,论文使用特征向量(feature vector)进行表征,这样每个问题都可以看做是嵌入表示空间中的一个点,一个点如果离周围邻居越近,则表明该问题与其他问题的相似度高,从而反映该问题具有代表性。于是论文通过历史数据(其实就是训练数据)来计算每个知识点相关问题的平均代表性(通过计算密度)即可得到每个知识点的重要性。
公式如下,主要使用考生在问题上的表现来表征问题本身,从而反映问题的难度和差异性,进而刻画问题之间的距离度量。

![]()


更多细节可以查看论文,不过笔者发现在开源代码中,这部分知识点重要程度的计算并没有代码体现。
3、Diversity Module
基于第一个质量模块选择出的KC个题目,仍然需要选出最佳的那个题目,因为每个step中只选择一个题目。分布性模块其实是计算KC个题目的知识点覆盖率,以往的计算方式如下:

计算所选题目涉及知识点占所有知识点的比例作为知识点覆盖率,但是这有很明显的弊端,就是将知识点按1:1计算了,也就是所有知识点只要涉及都是按一份计算,但其实不同知识点所选的次数是不同的,因此这种计算方法是非常不公平的;同时这种方法将知识点的重要程度看做相同。后者就是采用上述的重要性模块进行改进,而前者就是采用分布性模块进行改进,方式如下:

累计不同知识点被选择的次数,并且使用渐进式计算的方法使被选次数越多的知识点覆盖率占比越大。
[x] Experiment
实验部分采用了两个数据集:EXAM和ASSIST。同时对比算法包括了多种认知诊断基础模型(包括IRT、MIRT、NCDM等等),用来验证MAAT的策略有效性。实验结果如下:

