原文链接:https://zhuanlan.zhihu.com/p/126780292
Lecture 14 Transformers and Self-Attention For Generative Models
guest lecture by Ashish Vaswani and Anna Huang
学习变长数据的表示,这是序列学习的基本组件(序列学习包括 NMT, text summarization, QA)
通常使用 RNN 学习变长的表示:RNN 本身适合句子和像素序列
- LSTMs, GRUs 和其变体在循环模型中占主导地位。
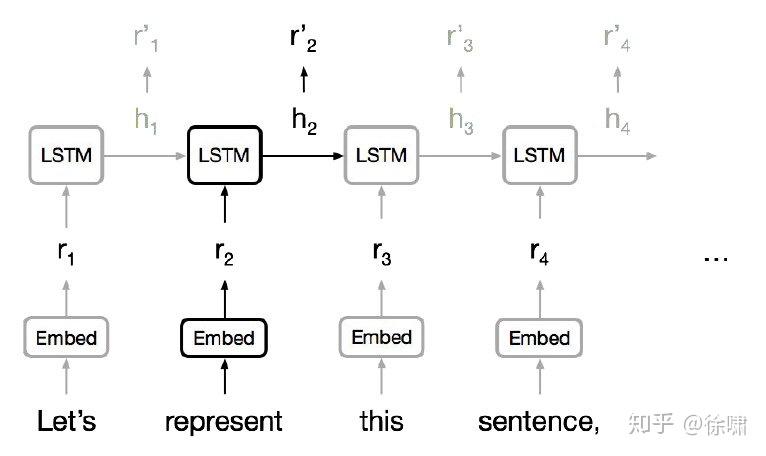
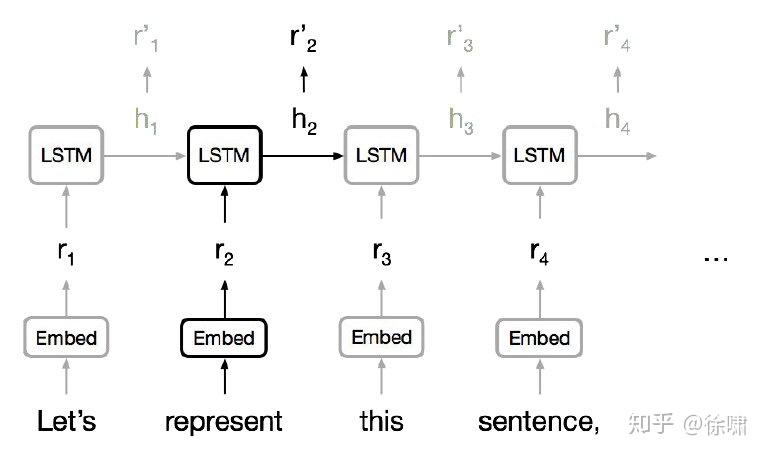
- 但是序列计算抑制了并行化。
- 没有对长期和短期依赖关系进行显式建模。
- 我们想要对层次结构建模。
- RNNs(顺序对齐的状态)看起来很浪费!
卷积神经网络
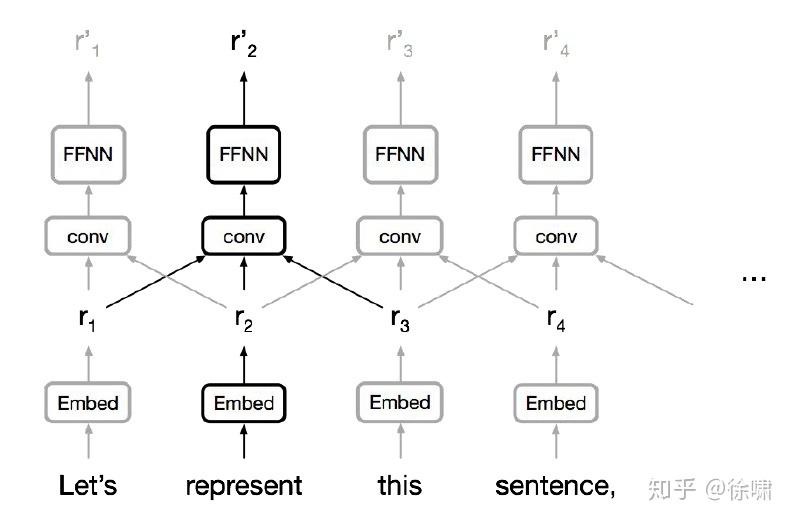
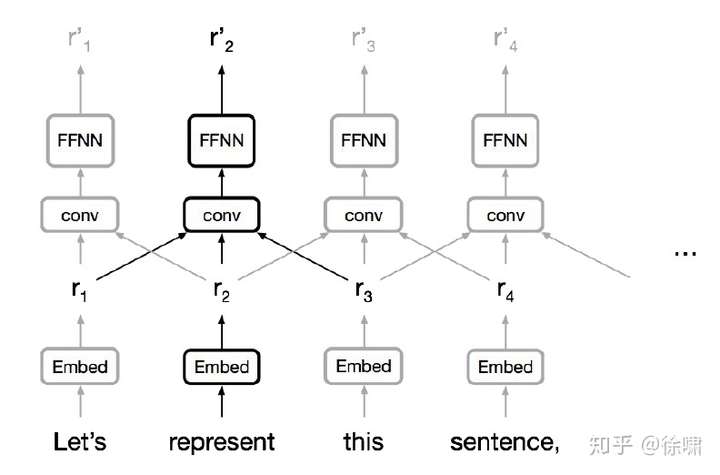
- 并行化(每层)很简单
- 利用局部依赖
- 不同位置的交互距离是线性或是对数的
- 远程依赖需要多层
注意力
NMT 中,编码器和解码器之间的 Attention 是至关重要的
那么为什么不把注意力用于表示呢?
Self-Attention
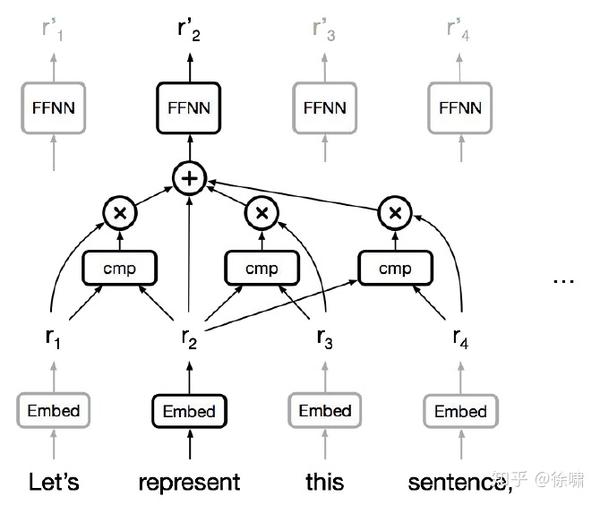
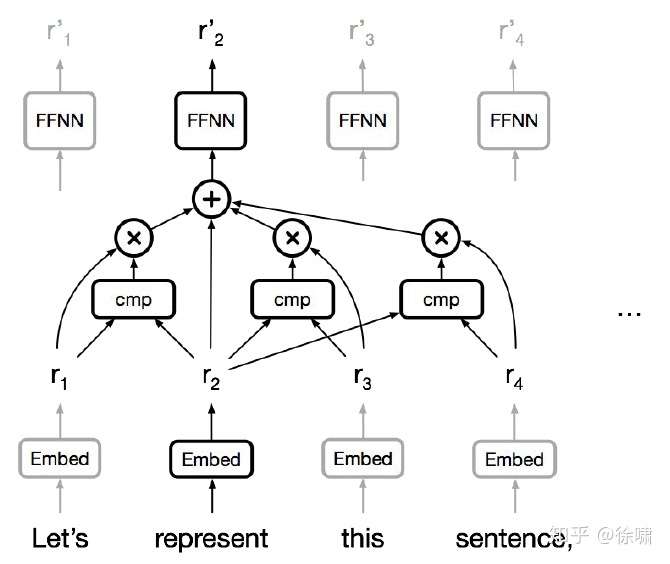
- 任何两个位置之间的路径长度都是常数级别的
- 门控 / 乘法 的交互
- 可以并行化(每层)
- 可以完全替代序列计算吗?
Text generation
Previous work
Classification & regression with self-attention:
Parikh et al. (2016), Lin et al. (2016)
Self-attention with RNNs:
Long et al. (2016), Shao, Gows et al. (2017)
Recurrent attention:
Sukhbaatar et al. (2015)
The Transformer
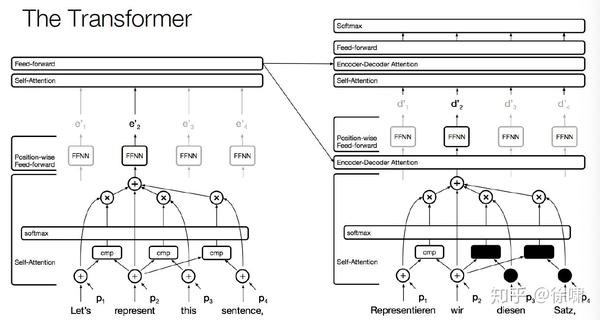
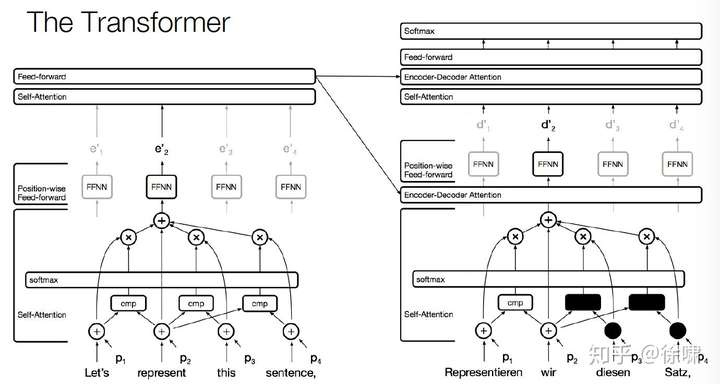
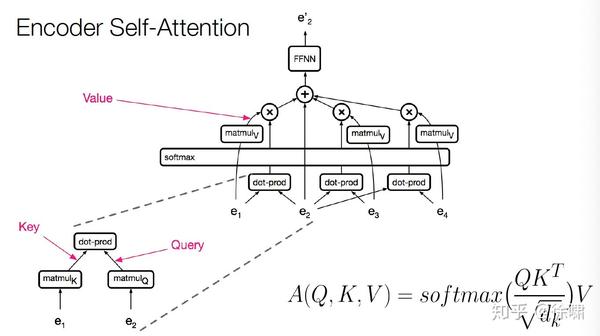
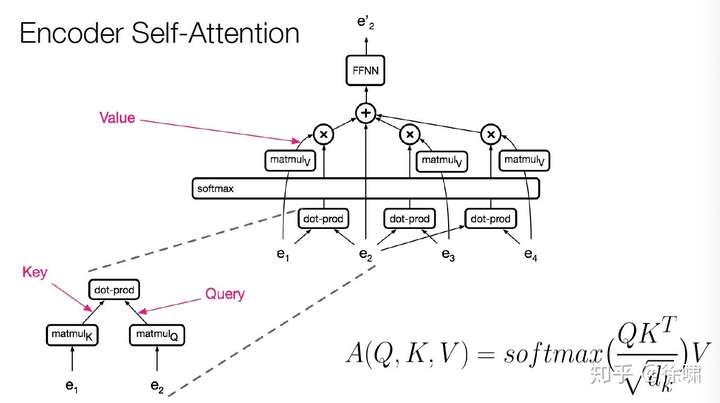
Encoder Self-Attention
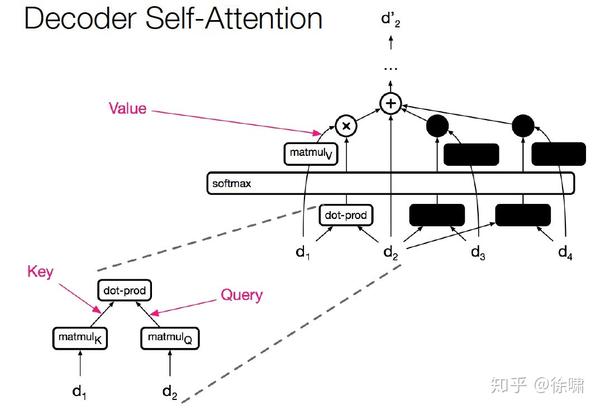
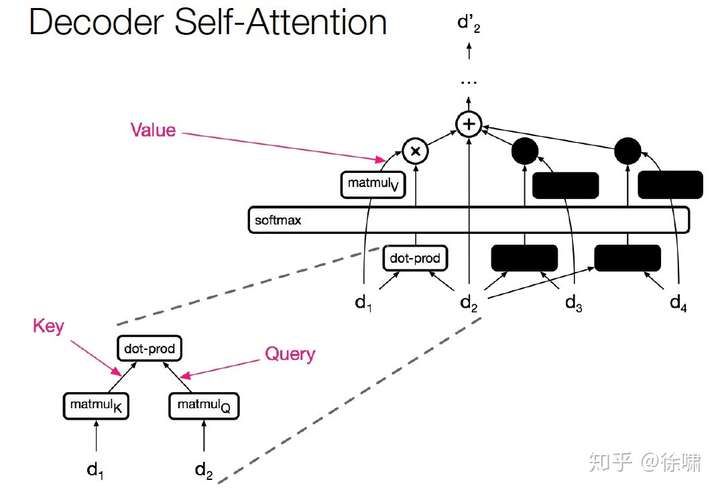
Decoder Self-Attention
复杂度
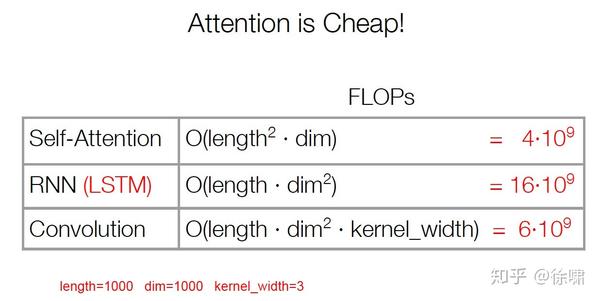

由于计算只涉及到两个矩阵乘法,所以是序列长度的平方
当维度比长度大得多的时候,非常有效
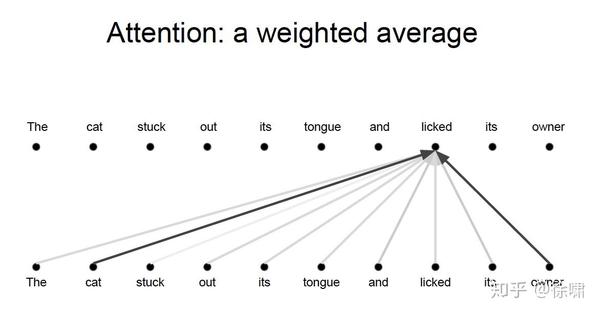
Problem
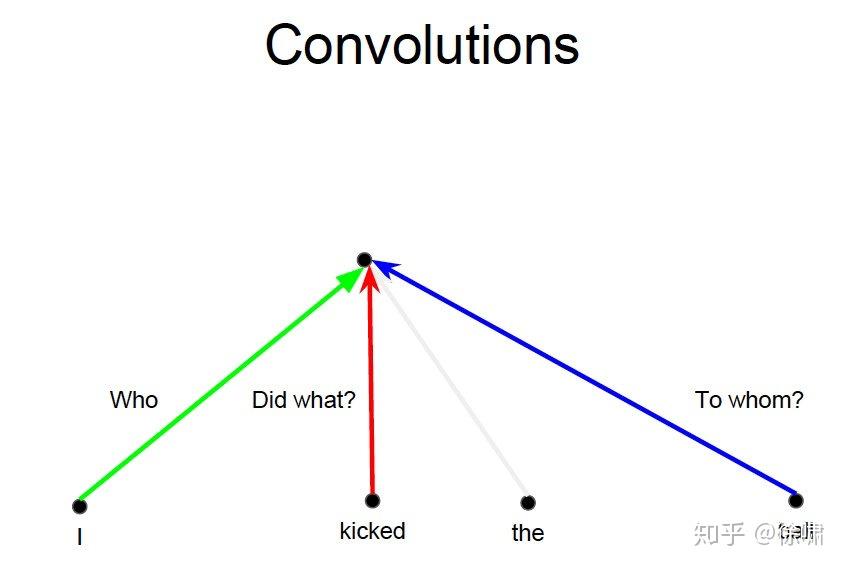
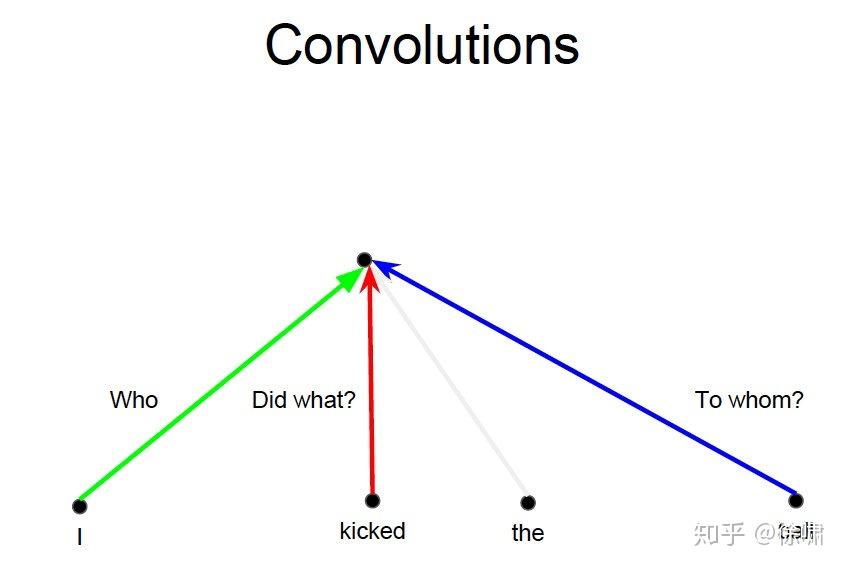
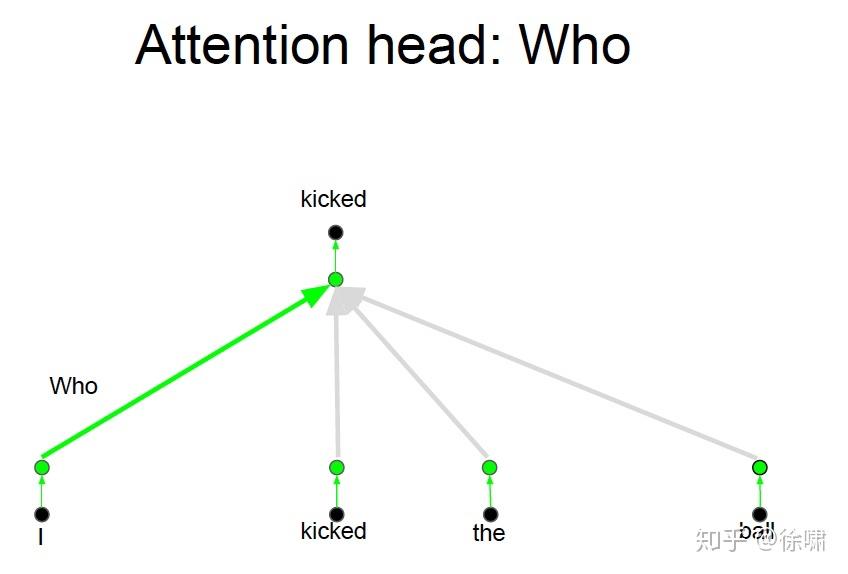
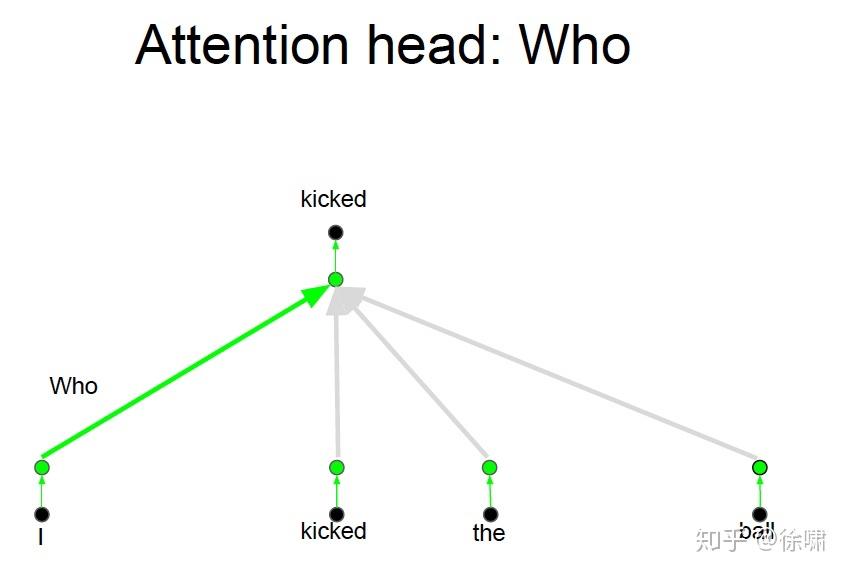
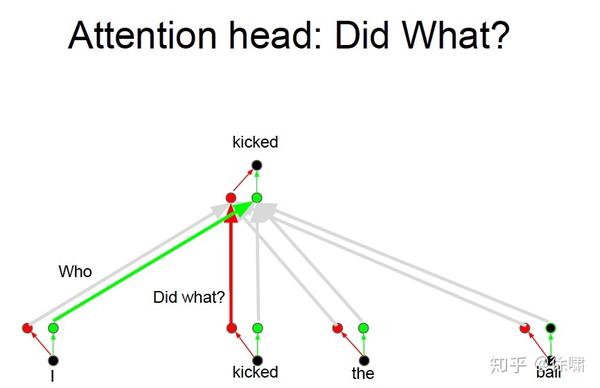
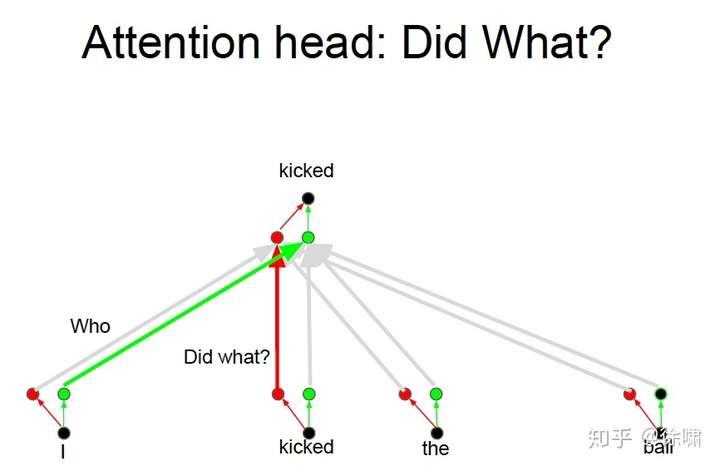
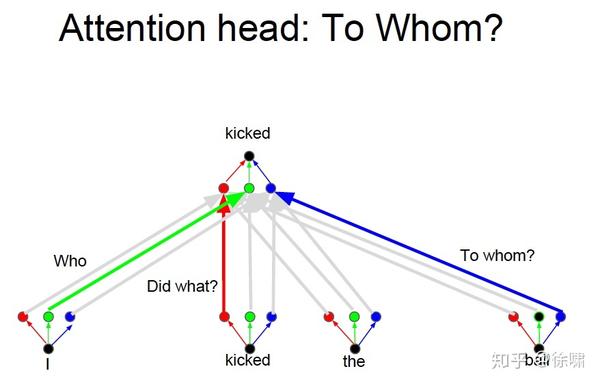
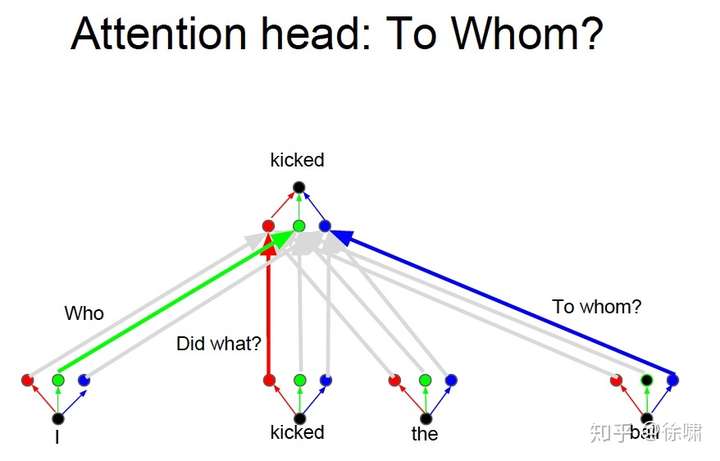
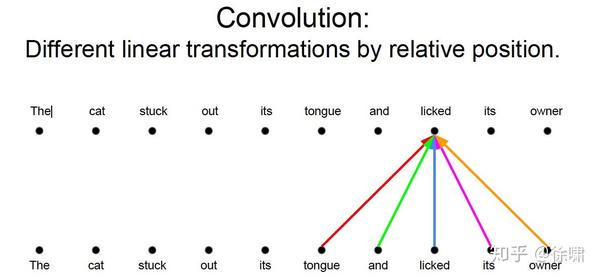
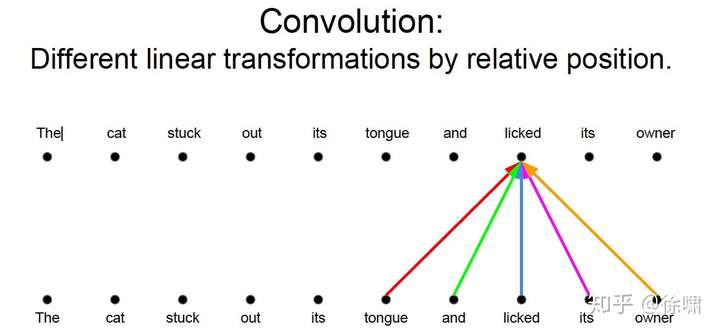
上例中,我们想要知道谁对谁做了什么,通过卷积中的多个卷积核的不同的线性操作,我们可以分别获取到 who, did what, to whom 的信息。

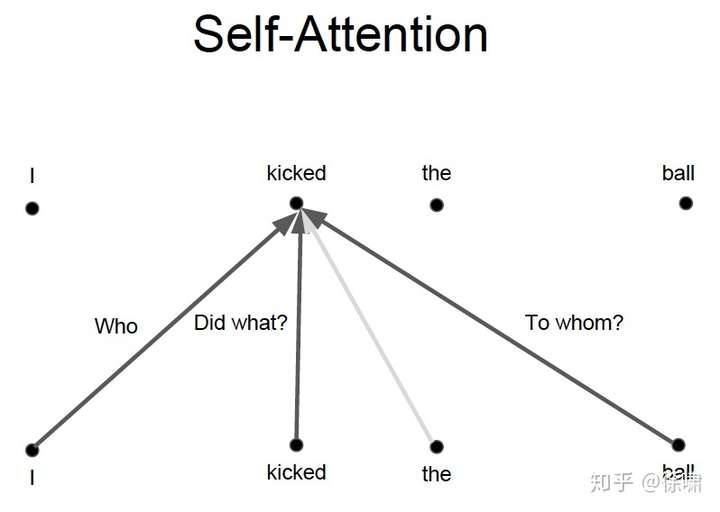
但是对于 Attention 而言,如果只有一个Attention layer,那么对于一句话里的每个词都是同样的线性变换,不能够做到在不同的位置提取不同的信息
这就是多头注意力的来源,灵感来源于 CNN 中的多个卷积核的设计
Solution
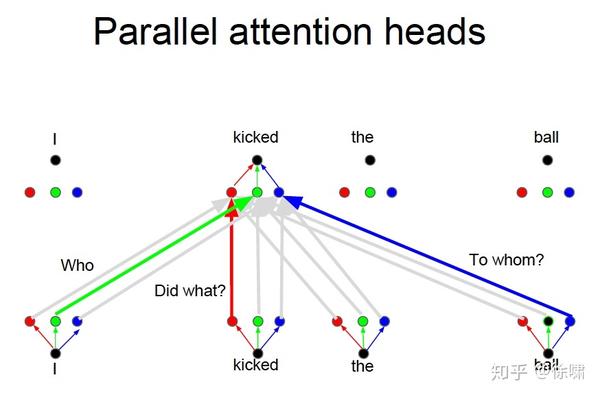
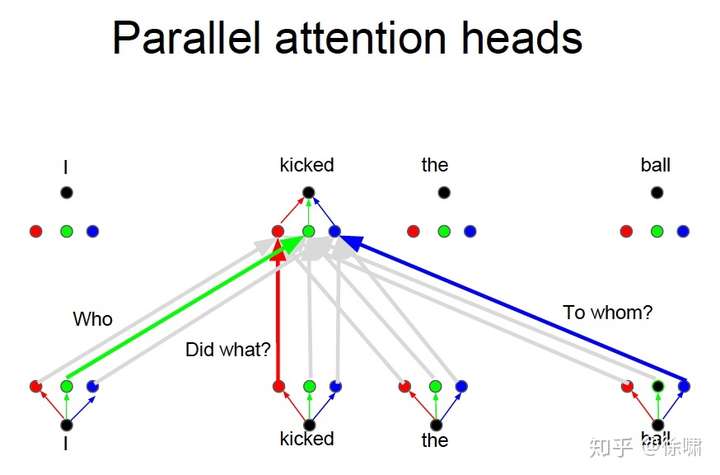
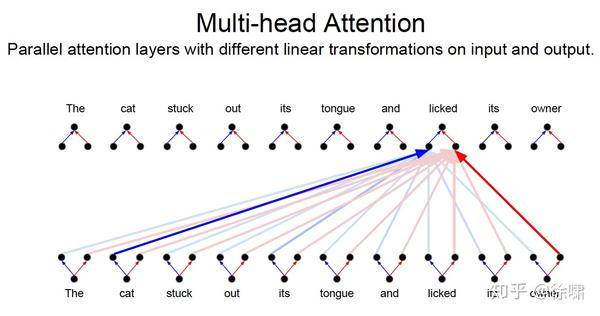
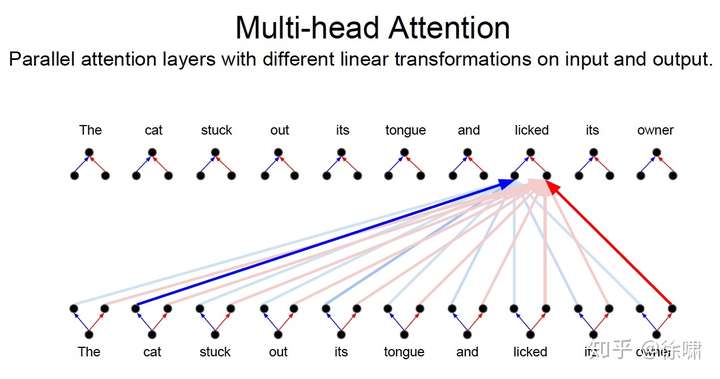
Who, Did What, To Whom 分别拥有注意力头
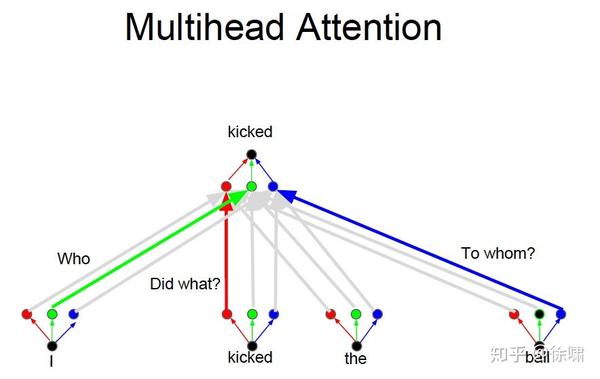
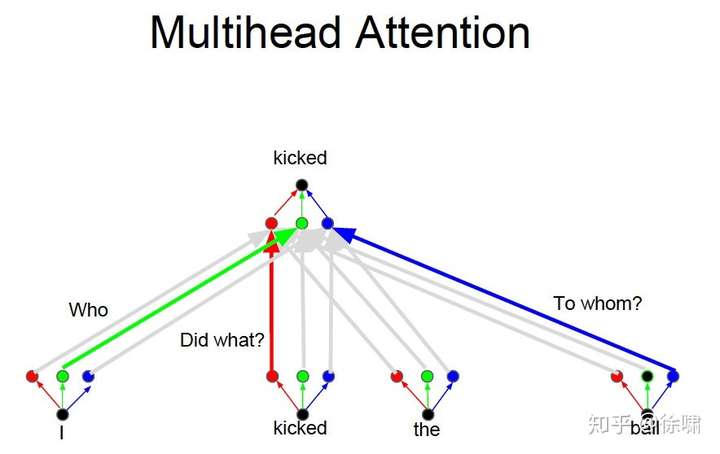
- 将注意力层视为特征探测器
- 可以并行完成
- 为了效率,减少注意力头的维度,并行操作这些注意力层,弥补了计算 差距
Results
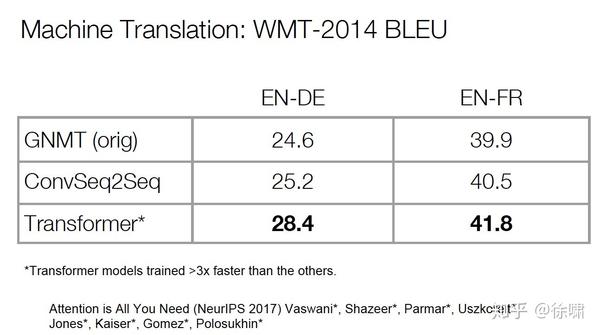
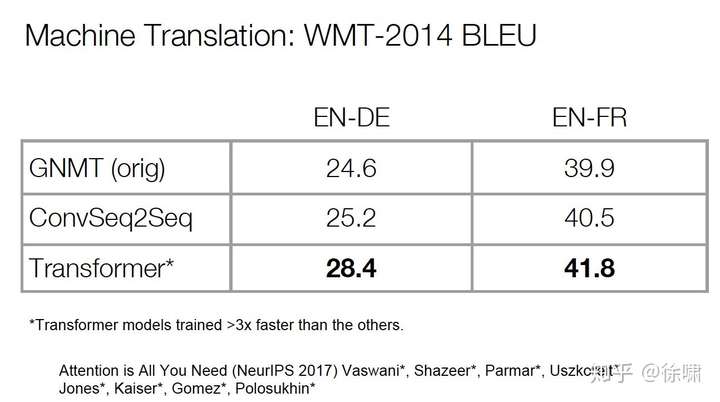
- 但我们并不一定比 LSTM 取得了更好的表示,只是我们更适合 SGD,可以更好的训练
- 我们可以对任意两个词之间构建连接
Importance of residuals


位置信息最初添加在了模型的输入处,通过残差连接将位置信息传递到每一层,可以不需要再每一层都添加位置信息
Training Details
- ADAM optimizer with a learning rate warmup (warmup + exponential decay)
- Dropout during training at every layer just before adding residual
- Layer-norm
- Attention dropout (for some experiments)
- Checkpoint-averaging
- Label smoothing
- Auto-regressive decoding with beam search and length biasing
- ……