·ТлФОДЈєhttps://blog.paperspace.com/pytorch-101-understanding-graphs-and-automatic-differentiation/
ЛµФЪЗ°ГжЈєХвЖЄОДХВКЗAyoosh Kathuria№ШУЪPyTorchЅМіМµДПµБРОДХВЈ¬·ЗіЈПІ»¶ЛыµДПµБРЅМіМЈ¬ЅІµДєЬПкПёєЬУРЖф·ўЎЈТтґЛ°СФОДµДПµБРЅМіМ·ТлБЛПВАґЈ¬ІўЅбєПБЛЧФјєµДІї·ЦАнЅвЎЈТтОЄ±ѕИЛДЬБ¦УРПЮЈ¬ДСГвєНФОД±нґпµДє¬ТеУРЛщіцИлЈ¬ЅцЅцЧчОЄЅ»БчК№УГЎЈ
PyTorch 101Ј¬Part1ЈєјЖЛгНјµДАнЅвЎўЧФ¶ЇОў·ЦєНAutogradДЈїй

PyTorchКЗЧоЦШТЄµДЙо¶ИС§П°ївЦ®Т»ЎЈЛьКЗЙо¶ИС§П°СРѕїІ»ґнµДСЎФсЈ¬ІўЗТЛжЧЕК±јдµДНЖТЖЈ¬ФЅАґФЅ¶аµД№«ЛѕєНСРѕїКµСйКТ¶јФЪІЙУГХвёцївЎЈ
ФЪХвёцПµБРЅМіМЦРЈ¬ОТ»бПтДгГЗЅйЙЬPyTorchЎўИзєОід·ЦАыУГХвёцївТФј°О§ИЖЧЕЛьЛщ№№ЅЁµД№¤ѕЯЙъМ¬ПµНіЎЈОТГЗКЧПИ»бЙжј°»щ±ѕµД№№ФмДЈїйЈ¬И»єуЅМДгИзєОїмЛЩµД№№Фм¶ЁЦЖµДјЬ№№ЎЈЧоєуОТГЗ»бУГБЅЖЄОДХВЧЬЅбИзєОИҐА©Х№ДгµДґъВлЈ¬ІўЗТИзєОИҐµчКФіцґнµДґъВлЎЈ
ХвКЗОТГЗPyTorch 101ПµБРОДХВµДµЪТ»Ії·ЦЎЈ
- јЖЛгНјАнЅвЎўЧФ¶ЇОў·ЦєНAutogradДЈїй
- №№ФмДгµДµЪТ»ёцЙсѕНшВз
- УГPyTrochЧЯµДёьЙо
- ДЪґж№ЬАнТФј°К№УГ¶аGPU
- АнЅвHooks
ДгїЙТФФЪGitHubІЦївХвАпµГµЅХвЖЄОДХВЈЁТФј°ЖдЛыОДХВЈ©µДЛщУРґъВлЎЈ
ДїВј
PyTorch 101Ј¬Part1ЈєјЖЛгНјµДАнЅвЎўЧФ¶ЇОў·ЦєНAutogradДЈїй
1 З°СШЦЄК¶
2 ЧФ¶ЇОў·Ц
3 Т»ёцјтµҐАэЧУ
4 јЖЛгНј
5 јЖЛгМЭ¶И
6 PyTorch Autograd
6.1 Tensor
6.2 єЇКэ
7 PyTorchµДНјєНTensorFlowµДНјУРКІГґІ»Н¬Јї
8 Т»Р©јјЗЙ
8.1 requires_grad
8.2 torch.no_grad()
9 ЅбВЫ
1 З°СШЦЄК¶
- БґКЅЗуµј·ЁФт
- »щ±ѕБЛЅвЙо¶ИС§П°
- PyTorch 1.0
2 ЧФ¶ЇОў·Ц
єЬ¶аPyTorchµДПµБРОДХВ¶јКЗТФМЦВЫКІГґКЗНшВзµД»щ±ѕјЬ№№їЄКјµДЎЈµ«КЗЈ¬ОТПІ»¶ПИМЦВЫТ»ПВЧФ¶ЇОў·ЦЎЈ
ЧФ¶ЇОў·ЦІ»ЅцКЗPyTorchЈ¬¶шЗТ»№КЗГїТ»ёцЙо¶ИС§П°ївµДТ»ёц№№ФмїйЎЈФЪОТїґАґЈ¬PyTorchµДЧФ¶ЇОў·Ц»ъЦЖЅРЧцAutogradЈ¬ЛьКЗТ»ёцєЬ°фµД№¤ѕЯАґАнЅвЧФ¶ЇОў·ЦКЗИзєО№¤ЧчµДЎЈХвІ»ЅцУРЦъУЪДгёьєГµДАнЅвPyTorchЈ¬¶шЗТёьєГµДАнЅвЖдЛыЙо¶ИС§П°ївЎЈ
ПЦФЪµДЙсѕНшВзјЬ№№УРЙП°ЩНтёцїЙТФС§П°µДІОКэЎЈґУјЖЛгµДЅЗ¶ИАґЛµЈ¬СµБ·Т»ёцЙсѕНшВзУЙБЅёцЅЧ¶ОЧйіЙЈє
- З°Птґ«ІҐИҐјЖЛгЛрК§єЇКэ
- ·ґПтґ«ІҐИҐјЖЛгїЙС§П°ІОКэµДМЭ¶И
З°Птґ«ІҐ·ЗіЈµДЦ±ЅУЎЈТ»ІгµДКдіцѕНКЗБнТ»ІгµДКдИлЈ¬ТАґОАаНЖЎЈ·ґПтґ«ІҐЙФОўУРµгёґФУЈ¬ТтОЄЛьРиТЄОТГЗК№УГБґКЅЗуµј·ЁФтИҐјЖЛгИЁЦШПа¶ФУЪЛрК§єЇКэµДМЭ¶ИЎЈ
3 Т»ёцјтµҐАэЧУ
ОТГЗѕЩТ»ёц·ЗіЈјтµҐµДЙсѕНшВзµДАэЧУЈ¬ЛьУР5ёцЙсѕФЄЎЈОТГЗµДЙсѕНшВзѕНПсПВГжХвСщЎЈ

ПВГжµДµИКЅГиКцБЛОТГЗµДЙсѕНшВзЈє
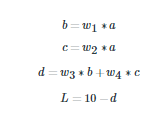
ИГОТГЗАґјЖЛгТ»ПВГїТ»ёцїЙС§П°µДІОКэwµДМЭ¶ИЈє
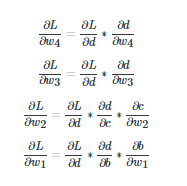
ЛщУРµДХвР©МЭ¶И¶јТСѕК№УГБґКЅ·ЁФтЗуµГБЛЎЈЧўТвЈ¬ЙПГжЛщУРµДµИКЅУТ±ЯµДµҐ¶АµДМЭ¶И¶јїЙТФЦ±ЅУµГµЅЈ¬ТтОЄМЭ¶ИµД·ЦЧУКЗ·ЦДёµДПФєЇКэЎЈ
4 јЖЛгНј
ТтОЄЙПГжµДАэЧУ·ЗіЈјтµҐЈ¬ЛщТФОТГЗїЙТФКЦЛгТ»ПВНшВзµДМЭ¶ИЎЈЙиПлТ»ПВЈ¬Из№ыПЦФЪДгУРТ»ёц152ІгНшВзЈ¬»тХЯЈ¬Из№ыХвёцНшВзУР¶аёц·ЦЦ§Ј¬КЦЛгїЙДЬѕН»б±ИЅПВй·іБЛЎЈµ±ОТГЗЙијЖИнјюИҐКµПЦЙсѕНшВзµДК±єтЈ¬ОТГЗПЈНыУРТ»ёц·Ѕ·ЁЈ¬І»№ЬНшВзЅб№№КЗКІГґАаРНµДЈ¬ОТГЗ¶јїЙТФОЮ·мПОЅУµШИҐјЖЛгМЭ¶ИЎЈЛщТФЈ¬µ±НшВз·ўЙъ±д»ЇµДК±єтЈ¬іМРтФ±І»РиТЄИҐКЦ¶ЇјЖЛгМЭ¶ИЈ¬Ц»РиТЄНЁ№эИнјюАґКµПЦЎЈ
ОТГЗУГјЖЛгНјµДКэѕЭЅб№№АґКµПЦХвёцПл·ЁЎЈјЖЛгНјєНОТГЗФЪЙПГжЦЖЧчµДКѕТвНј·ЗіЈµДПаЛЖЎЈµ«КЗЈ¬јЖЛгНјЦРµДЅбµг±нКѕµДКЗ»щ±ѕµДФЛЛгЎЈіэБЛРиТЄ±нКѕУГ»§ЧФ¶ЁТеµД±дБїНвЈ¬ХвР©Ѕбµг»щ±ѕЙПКЗКэС§ФЛЛг·ыЈЁјУјхіЛіэЈ©ЎЈ
ЧўТвОЄБЛ±нКцЗеОъЈ¬ФЪНјЦРОТГЗТСѕ±кјЗБЛТ¶ЧУ±дБїa,w1,w2,w3,w4ЎЈµ«КЗРиТЄЧўТвµДКЗЈ¬ЛыГЗІ»КЗјЖЛгНјЦРµДТ»Ії·ЦЎЈФЪОТГЗµДНјЦРЈ¬ЛыГЗґъ±нТ»ёцУГ»§ЧФ¶ЁТе±дБїµДМШКвЗйїцЈ¬ОТГЗЅцЅцЧчОЄТ»ёцАэНвЈЁНјЦРА¶Й«µДІї·ЦКЗЅбµгЈ¬ЧПЙ«µДКЗТ¶ЧУЅбµгЈ¬Т¶ЧУЅбµгІўІ»КЗјЖЛгНјµДТ»Ії·ЦЈ©ЎЈ

±дБїb,cєНdЧчОЄКэС§ФЛЛгµДЅб№ыЈ¬И»¶шa,w1,w2,w3єНw4УЙУГ»§ЧФјєіхКј»ЇµДЎЈТтОЄЛыГЗІ»ДЬУЙКэС§ФЛЛгАґґґЅЁЈ¬єНЛыГЗПа№ШµДґґЅЁµДЅбµгУЙЛыГЗЧФјєµДГыЧЦ±нКѕЈ¬НјЦРЛщУРµДТ¶ЧУЅбµг¶јКЗХвСщЎЈ
5 јЖЛгМЭ¶И
ПЦФЪЈ¬ОТЧј±ёЅІТ»ПВЈ¬ИзєОК№УГТ»ёцјЖЛгНјИҐјЖЛгМЭ¶ИЎЈ
іэБЛТ¶ЧУЅбµгЈ¬јЖЛгНјЦРµДГїёцЅбµг¶јїЙТФїґЧцКЗТ»ёцєЇКэЈ¬ЛьЅУКХТ»ёцКдИлИ»єујЖЛгТ»ёцКдіцЎЈјЩЙиНјµДЅбµгЈ¬ЛьїЙТФґУw4cєНw3bЦРјЖЛгµГµЅ±дБїdЎЈТтґЛЈ¬ОТГЗїЙТФХвСщРґЈє
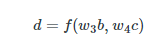
ЙПГжµДєЇКэїЙТФК№УГјЖЛгНјАґ±нКѕЈє

ПЦФЪЈ¬ОТГЗїЙТФЗбЛЙµШјЖЛгіцfПа¶ФУЪЛьµДКдИлµДМЭ¶ИЎЈ??/(??3?)єН??/(??4?)ЈЁЛьГЗ¶јКЗ1Ј©ПЦФЪЈ¬УГЛьГЗПа¶ФµДМЭ¶ИёшКдИлЅбµгµДёчёц±ЯМщЙП±кЗ©Ј¬ПсПВГжНјЖ¬Т»СщЈє

ОТГЗёшХыХЕНјМщЙП±кЗ©ЎЈХвХЕНјїґЖрАґКЗХвСщµДЈє

ЅУПВАґЈ¬ОТГЗГиКцјЖЛгНјЦРЛщУРЅбµгПа¶ФУЪЛрК§LµДµјКэµДЛг·ЁЎЈјЩЙиОТГЗПлТЄИҐјЖЛгµјКэ??/(??4)Јє
- ОТГЗКЧПИПтєу»ШЛЭґУdµЅw4µДЛщУРїЙДЬµДВ·ѕ¶
- ФЪХвАпЦ»УРТ»ёцВ·ѕ¶
- ОТГЗСШЧЕВ·ѕ¶іЛТФѕ№эЛщУРµД±Я
ДгїґЈ¬ХвёціЛ»эѕНКЗєНОТГЗК№УГБґКЅЗуµј·ЁФтµГµЅµДТ»СщЎЈИз№ыУРІ»Ц№Т»МхВ·ѕ¶ґУLµЅТ»ёц±дБїЈ¬И»єуЈ¬ОТГЗСШЧЕГїТ»ёцВ·ѕ¶іЛТФ±ЯЈ¬ЅУЧЕ°СЛьГЗјУФЪТ»ЖрЎЈѕЩАэАґЛµЈ¬??/??ѕНКЗЈє
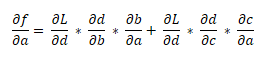
6 PyTorch Autograd
ПЦФЪЈ¬ОТГЗТСѕАнЅвКІГґКЗјЖЛгНјБЛЈ¬ОТГЗ»ШµЅPyTorchЈ¬АнЅвФЪPyTorchЦРЙПГжµДБґКЅЗуµј·ЁФтКЗИзєОКµПЦµДЈє
6.1 Tensor
TensorКЗТ»ёцКэѕЭЅб№№Ј¬ЛьКЗPyTorchµДТ»ёц»щ±ѕµД№№ФмїйЎЈTensorєНnumpy arrays·ЗіЈПсЈ¬іэБЛTensorsїЙТФід·ЦАыУГGPUµДЖЅРРјЖЛгДЬБ¦Ј¬ХвµгєНnumpyІ»Т»СщЈ¬TensorЖдЛыµДУп·ЁєНnumpy arrays·ЗіЈАаЛЖЎЈ
In [1]: import torchIn [2]: tsr = torch.Tensor(3,5)In [3]: tsr
Out[3]:
tensor([[ 0.0000e+00, 0.0000e+00, 8.4452e-29, -1.0842e-19, 1.2413e-35],[ 1.4013e-45, 1.2416e-35, 1.4013e-45, 2.3331e-35, 1.4013e-45],[ 1.0108e-36, 1.4013e-45, 8.3641e-37, 1.4013e-45, 1.0040e-36]])TensorЛьЧФјєѕНПсТ»ёцnumpy ndarrayЎЈХвёцКэѕЭЅб№№їЙТФИГДгёьїмЛЩµДЅшРРПЯРФФЛЛгЎЈИз№ыДгПлИГPyTorchИҐґґЅЁєНХвР©ФЛЛг·ыПа№ШµДНјЈ¬ДгТЄЙиЦГTensorµДrequires_gradµДКфРФОЄTrueЈ¬ХвСщІЕ»бјЖЛгХвёцTensorµДМЭ¶ИЎЈ
ФЪХвАпЈ¬ХвёцAPIїЙДЬЙФОўУРµгИГИЛ·ЛТДЛщЛјЎЈФЪPyTorchЦРЈ¬УРєЬ¶а·Ѕ·ЁИҐіхКј»ЇТ»ёцTensorsЎЈЛдИ»ДгїЙТФК№УГТ»Р©·Ѕ·ЁЈ¬ФЪЛьµД№№ФмМеЦРПФКѕ¶ЁТеrequires_gradЈ¬µ«КЗЈ¬ЖдЛы·Ѕ·ЁТЄЗуДгФЪґґЅЁTensorЦ®єуЈ¬КЦ¶ЇИҐЙиЦГЈє
>> t1 = torch.randn((3,3), requires_grad = True) >> t2 = torch.FloatTensor(3,3) # No way to specify requires_grad while initiating
>> t2.requires_grad = Truerequires_gradКЗїЙґ«µЭµДЎЈХвТвО¶ЧЕµ±Т»ёцTensorУЙЖдЛыTensorsФЛЛгµГµЅµДК±єтЈ¬јЩЙиХвР©ЅшРРФЛЛгµДTensorsЦРЦБЙЩУРТ»ёцµДrequires_gradОЄTrueЈ¬ДЗГґЅб№ыTensorµДrequires_gradѕН»бЦГОЄTrueЎЈ
ГїёцTensor¶јУРТ»ёцЅРЧцgrad_fnµДКфРФЈ¬ЛьЦёµДКЗ±дБїµДКэС§ФЛЛгЎЈИз№ыrequires_gradЦГОЄБЛFalseЈ¬ДЗГґgrad_fnТІ»бКЗNoneЎЈ
ФЪОТГЗµДАэЧУЦРЈ¬dµДМЭ¶ИєЇКэКЗТ»ёцјУ·ЁФЛЛгЈ¬ТтОЄfЅ«ЛьµДКдИл¶јјУФЪТ»ЖрБЛЎЈЧўТвЈ¬јУ·ЁФЛЛгТІКЗОТГЗНјЦРµДЅбµгЈ¬ЛьµДКдіцКЗdЎЈИз№ыОТГЗµДTensorКЗТ»ёцТ¶ЧУЅбµгЈЁУЙУГ»§іхКј»ЇЈ©Ј¬ДЗГґgrad_fnТІКЗNoneЎЈ
import torch a = torch.randn((3,3), requires_grad = True)w1 = torch.randn((3,3), requires_grad = True)
w2 = torch.randn((3,3), requires_grad = True)
w3 = torch.randn((3,3), requires_grad = True)
w4 = torch.randn((3,3), requires_grad = True)b = w1*a
c = w2*ad = w3*b + w4*c L = 10 - dprint("The grad fn for a is", a.grad_fn)
print("The grad fn for d is", d.grad_fn)Из№ыФЛРРЙПГжµДґъВлЈ¬ДгѕН»бµГµЅПВГжµДКдіцЈє
# ТтОЄaєНw1,w2¶јКЗУРУГ»§Ц±ЅУЦё¶Ё,ЛыГЗКЗТ¶ЧУЈЁleaf nodeЈ©Ј¬ТтґЛІ»ґжФЪgrad_fn
The grad fn for a is None
# dКЗФЪЗ°Птґ«ІҐЦРКЗНЁ№эјУ·ЁФЛЛгµГµЅµДЈ¬ТтґЛУРgrad_fn
The grad fn for d is <AddBackward0 object at 0x1033afe48>
НЁ№эЙПГжµДАэЧУЈ¬ОТГЗїЙТФµГµЅБЅёцРЕПўЈє
- Т¶ЧУЅбµгµДrequires_gradОЄTrueЈ¬µ«КЗІ»ґжФЪgrad_fn
- ЅбµгµДrequires_gradОЄTrueЈ¬ІўЗТґжФЪgrad_fn
ОТГЗїЙТФК№УГіЙФ±єЇКэis_leafАґЕР¶ПТ»ёц±дБїКЗ·сКЗТ¶ЧУTensorЈ¬К№УГdata.requires_gradАґЕР¶ПТ»ёцХЕБїКЗ·сїЙТФЅшРРМЭ¶ИјЖЛгЎЈ
6.2 єЇКэ
ФЪPyTorchЦРЈ¬ЛщУРµДКэС§ФЛЛг¶јРиТЄКµПЦtorch.nn.Autograd.FunctionАаЎЈХвёцАаУРБЅёцОТГЗРиТЄ№ШЧўµДіЙФ±єЇКэЎЈ
µЪТ»ёцКЗforwardєЇКэЈ¬ХвёцєЇКэК№УГКдИлјтµҐµШјЖЛгКдіцЎЈ
ХвёцbackwardєЇКэЅУКХЛьЗ°ГжІї·ЦНшВзµДМЭ¶ИЎЈХэИзДгїґµЅµДЈ¬ґУєЇКэf·ґПтґ«ІҐАґµДМЭ¶ИЈ¬»щ±ѕЙПКЗґУЛьЗ°ГжµДІгµЅfµД·ґПтґ«ІҐµДМЭ¶ИіЛТФТФfОЄКдіцµДПа¶ФУЪЛьµДКдИлµДѕЦІїМЭ¶ИЎЈТІХэКЗbackwardєЇКэФЪЧцµДКВЗйЎЈ
ИГОТГЗФЩґОЛјїјОТГЗµДАэЧУЈє
![]()

- dКЗОТГЗµДTensorЎЈЛьµДgrad_fnКЗ<ThAddBackward>ЎЈХвКЗТ»ёц»щ±ѕµДјУ·ЁФЛЛгЈ¬ТтОЄ№№ФмdµДєЇКэЈ¬Ѕ«КдИл¶јјУФЪБЛТ»ЖрЎЈ
- ЛьµДgrad_fnµДforwardєЇКэЅУКХБЛКдИлw3bєНw4cЈ¬ІўЗТ°СЛьГЗјУФЪТ»ЖрЈ¬ХвёцЦµ»щ±ѕµШ±ЈґжФЪdЦРЎЈ
- <ThAddBackward>µДbackwardєЇКэЅУКХґУЗ°Ігґ«ИлµДМЭ¶ИЧчОЄЛьµДКдИлЎЈХвёцѕНКЗґУLµЅdСШЧЕ±ЯµДЦчТЄµД??/??ЎЈХвёцМЭ¶ИТІКЗLПа¶ФУЪdµДМЭ¶ИЈ¬¶шЗТЛь±ЈґжФЪdµДgradКфРФЦРЎЈїЙТФК№УГd.gradАґµГµЅЎЈЈЁГїёцЅбµгЦР±ЈґжЧЕЛьПа¶ФУЪLµДМЭ¶ИЈ¬їЙТФК№УГd.gradАґ»сµГµ±З°µДМЭ¶ИЦµЈ©
- ЛьУлѕЦІїМЭ¶И?? / (??4?)єН?? / (??3?)ЅшРРПаіЛЎЈ
- И»єуЈ¬·ґПтґ«ІҐ·Ц±рУГѕЦІїјЖЛгµДМЭ¶ИіЛТФКдИлМЭ¶ИЈ¬И»єуНЁ№эј¤»оКдИлµДgrad_fnµД·ґПтґ«ІҐ·Ѕ·ЁЈ¬°СМЭ¶ИЎ°ЛНЎ±µЅЛьµДКдИлЎЈ
- ѕЩёцАэЧУАґЛµЈ¬єНdПа№ШµД·ґПтґ«ІҐєЇКэµД<ThAddBackward>w4*cµДgrad_fnµД·ґПтґ«ІҐєЇКэЈЁХвАпЈ¬w4*cКЗЦРјдTensorЈ¬ЛьµДgrad_fnКЗ<ThMulBackward>Ј©ЎЈФЪµчУГbackwardєЇКэµДН¬К±Ј¬МЭ¶И(?? / ??)?(?? / ??4?)ЧчОЄКдИлґ«µЭЎЈ
- ПЦФЪЈ¬¶ФУЪ±дБїw4?c,(?? / ??)?(?? / ??4?)±дОЄБЛґ«ИлµДМЭ¶ИЈ¬ѕНПсІЅЦи3ЦР????ґ«ёшdДЗСщЈ¬И»єуС»·Хыёц№эіМЎЈ
ФЪЛг·ЁЙПЈ¬ХвАпКЗ·ґПтґ«ІҐФЪјЖЛгНјЦРКЗФхСщЅшРРјЖЛгµДЎЈ
def backward (incoming_gradients):self.Tensor.grad = incoming_gradientsfor inp in self.inputs:if inp.grad_fn is not None:new_incoming_gradients = //incoming_gradient * local_grad(self.Tensor, inp)inp.grad_fn.backward(new_incoming_gradients)else:passХвАпЈ¬self.TensorКЗУЙAutograd.FunctionґґЅЁµД»щ±ѕµДTensorЈ¬ФЪОТГЗµДАэЧУЦРКЗdЎЈ
КдИлМЭ¶ИєНѕЦІїМЭ¶ИФЪЙПГж¶јТСѕ¶ЁТеБЛЎЈ
ОЄБЛФЪОТГЗµДЙсѕНшВзЦРјЖЛгОў·ЦЈ¬ОТГЗТ»°г»б¶Ф±нКѕОТГЗЛрК§µДTensorЈ¬µчУГbackwardєЇКэЎЈИ»єуЈ¬ОТГЗґУґъ±нОТГЗЛрК§µДgrad_fnµДЅбµгїЄКјЈ¬·ґПтґ«ІҐХыёцНјЎЈ
ѕНПсЙПГжЛщГиКцµДДЗСщЈ¬µ«ОТГЗ»ШЛЭµДК±єтЈ¬ХвёцbackwardєЇКэѕН»бґ©№эХыёцНјµЭ№йµШµчУГЎЈТ»µ©ОТГЗµЅґпБЛТ¶ЧУЅбµгЈ¬ТтОЄgrad_fnКЗNoneЈ¬µ«КЗЈ¬ОТГЗЅцЅцФЭНЈХвёцВ·ѕ¶ЙПµД»ШЛЭЎЈ
ФЪХвАпРиТЄЧўТвµДТ»јюКВЈ¬Из№ыОТГЗФЪТ»ёцКёБїµДTensorЙПµчУГbackward()єЇКэЈ¬PyTorch»б±ЁґнЎЈХвТвО¶ЧЕДгЦ»ДЬ№»ФЪ±кБїTensorЙПµчУГbackwardєЇКэЎЈФЪОТГЗµДАэЧУЦРЈ¬Из№ыОТГЗјЩЙиaКЗТ»ёцКёБїTensorЈ¬И»єуОТГЗФЪLЙПµчУГbackwardєЇКэЈ¬ЛьЅ«»б±ЁґнЎЈ
import torch a = torch.randn((3,3), requires_grad = True)w1 = torch.randn((3,3), requires_grad = True)
w2 = torch.randn((3,3), requires_grad = True)
w3 = torch.randn((3,3), requires_grad = True)
w4 = torch.randn((3,3), requires_grad = True)b = w1*a
c = w2*ad = w3*b + w4*c L = (10 - d)L.backward()ФЛРРЙПГжµДґъВлЅ«»бµјЦВПВГжµДґнОуЈє
RuntimeError: grad can be implicitly created only for scalar outputsХвКЗТтОЄёщѕЭ¶ЁТеЈ¬МЭ¶ИїЙТФПа¶ФУЪ±кБїЦµјЖЛгµГµЅЎЈДгІ»ДЬИ·ЗРµШЗуТ»ёцПтБїПа¶ФУЪБнТ»ёцПтБїµДОў·ЦЎЈХвЦЦЗйїцµДКэС§ГыґКіЖЦ®ОЄСЕїЛ±ИѕШХ󣬵«КЗХві¬іцБЛХвЖЄОДХВµД·¶О§Ј¬ОТГЗФЭЗТІ»МЦВЫЎЈ
ХвАпУРБЅёц·Ѕ·ЁАґЅвѕцХвёцОКМвЎЈ
ЈЁ1Ј©µЪТ»ёц·Ѕ·ЁЈєИз№ыДгЦ»КЗПлЙФОўёД±дТ»ПВЙПГжµДґъВлЈ¬Ц»РиТЄЅ«ЙиЦГLОЄЛщУРОуІоµДєНЈ¬ОТГЗµДОКМвѕНЅвѕцБЛЎЈ
import torch a = torch.randn((3,3), requires_grad = True)w1 = torch.randn((3,3), requires_grad = True)
w2 = torch.randn((3,3), requires_grad = True)
w3 = torch.randn((3,3), requires_grad = True)
w4 = torch.randn((3,3), requires_grad = True)b = w1*a
c = w2*ad = w3*b + w4*c # Replace L = (10 - d) by
L = (10 -d).sum()L.backward()Т»µ©ХвСщЧцБЛЈ¬ДгїЙТФНЁ№эµчУГTensorµДКфРФgradАґ»сИЎМЭ¶ИЎЈ
ЈЁ2Ј© µЪ¶юёц·Ѕ·ЁЈєТтОЄДіР©ФТтЈ¬ДгІ»µГІ»ИҐФЪТ»ёцКёБїєЇКэЦРµчУГbackwardЈ¬ДгїЙТФґ«ИлПтДгХэФЪµчУГ·ґПтґ«ІҐµДХЕБїµДРОЧґґуРЎtorch.ones
# Replace L.backward() with
L.backward(torch.ones(L.shape))РиТЄЧўТвЈ¬backwardКЗИзєОК№УГКдИлМЭ¶ИЧчОЄЛьµДКдіцµДЎЈЙПГжХвР©ИГbackwardТФОЄКдИлМЭ¶ИµДіЯґзєНLµДіЯґзТ»СщЈ¬¶шЗТДЬ№»ЅшРР·ґПтґ«ІҐЎЈ
К№УГХвЦЦ·ЅКЅЈ¬ОТГЗїЙТФИГГїёцTensor¶јУРМЭ¶ИЈ¬ІўЗТОТГЗїЙТФК№УГОТГЗСЎФсµДУЕ»ЇЛг·ЁИҐёьРВЛьГЗЎЈ
w1 = w1 - learning_rate * w1.gradТФґЛАаНЖ
7 PyTorchµДНјєНTensorFlowµДНјУРКІГґІ»Н¬Јї
PyTorchґґЅЁТ»ёціЖЦ®ОЄ¶ЇМ¬јЖЛгНјµД¶«ОчЈ¬ЛьТвО¶ЧЕНјКЗ¶ЇМ¬ЙъіЙµДЎЈ
ФЪµчУГТ»ёц±дБїµДforwardєЇКэЦ®З°Ј¬ФЪНјЦРКЗІ»ґжФЪTensorЅбµгµДЎЈ
a = torch.randn((3,3), requires_grad = True) #No graph yet, as a is a leafw1 = torch.randn((3,3), requires_grad = True) #Same logic as aboveb = w1*a #Graph with node `mulBackward` is created.ХвёцНјКЗєЬ¶ај¤»оTensorsµчУГfowardєЇКэµДЅб№ыЎЈЦ»УРХвСщЈ¬·ЗТ¶ЧУЅЪµгµД»єґжЖчІЕ»бОЄНјєНЦРјдЦµЈЁЙФєуУГАґјЖЛгМЭ¶ИЈ©·ЦЕдїХјдЎЈµ±ДгµчУГbackwardєЇКэµДК±єтЈ¬МЭ¶ИТІјЖЛгіцАґБЛЈ¬ХвР©»єґжЖчЈЁ¶ФУЪ·ЗТ¶ЧУЅбµг±дБїЈ©±»КН·ЕЈ¬И»єуХвёцНј±»Й±ЛАБЛЈЁґУДіЦЦТвТеЙПАґЛµЈ¬ДгІ»ДЬУГЛьАґЅшРР·ґПтґ«ІҐЈ¬ТтОЄ±ЈґжКэЦµИҐјЖЛгМЭ¶ИµД»єґжЖчТСѕПыК§БЛЈ©Ј¬ФЪ PyTorch µДјЖЛгНјЦРЈ¬Ц»УРТ¶ЧУЅбµгµД±дБї»б±ЈБфМЭ¶ИЎЈ¶шЛщУРЦРјд±дБїµДМЭ¶ИЦ»±»УГУЪ·ґПтґ«ІҐЈ¬Т»µ©НкіЙ·ґПтґ«ІҐЈ¬ЦРјд±дБїµДМЭ¶ИѕНЅ«ЧФ¶ЇКН·ЕЈ¬ґУ¶шЅЪФјДЪґж(ІОїјЧФ)
ПВТ»ґОЈ¬Дг»бУГПаН¬µДТ»ЧйtensorsАґµчУГforwardєЇКэЈ¬ґУЗ°ГжФЛРеõЅµДТ¶ЧУЅбµг»єґжЖчѕН»б№ІПнЈ¬Н¬К±Ј¬·ЗТ¶ЧУЅЪµг»єґжЖчЅ«»бФЩґОґґЅЁЎЈ
Из№ыДгФЪТ»ёцНјЙПµД·ЗТ¶ЧУЅЪµгµчУГ¶аУЪТ»ґОµДbackwardєЇКэЈ¬ДгѕН»бУцµЅПВГжµДґнОуЈЁТтОЄНјТСѕПыК§БЛЈ©Јє
RuntimeError: Trying to backward through the graph a second time,
but the buffers have already been freed.
Specify retain_graph=True when calling backward the first time.ХвКЗТтОЄФЪµЪТ»ґОµчУГbackwardєЇКэµДК±єтЈ¬·ЗТ¶ЧУЅЪµг»єґжЖчѕН±»Й±ЛАБЛЈ¬ТтґЛµ±backwardєЇКэµЪ¶юґОµчУГµДК±єтЈ¬Г»УРВ·ѕ¶ИҐЦёТэЛьµЅТ¶ЧУЅбµгДЗАпЎЈДгїЙТФПтbackwardєЇКэЦРМнјУretain_graph = TrueµДЙщГчЈ¬Аґі·ПъЙ±ЛА·ЗТ¶ЧУ»єґжЖчЎЈ
loss.backward(retain_graph = True)Из№ыДгПсЙПГжДЗСщЧцБЛЈ¬ДгѕНДЬ№»ФЪН¬Т»ёцНјЙПФЩґО·ґПтґ«ІҐЈ¬ІўЗТТІ»бјЖЛгМЭ¶ИЈ¬ТІѕНКЗЛµПВТ»ґОДг·ґПтґ«ІҐµДК±єтЈ¬ХвёцМЭ¶И»бјУИлµЅЙПґО·ґПтґ«ІҐ±ЈґжµДМЭ¶ИЦРБЛЎЈ
єНTensorFlowК№УГµДѕІМ¬јЖЛгНјПа±ИЈ¬ЛьФЪФЛРРіМРтЦ®З°ѕНґґЅЁєГБЛНјЎЈЦ®єуЈ¬ХвёцНјНЁ№эПтТСѕ¶ЁТеєГµДНјЦРґ«ИлКэѕЭАґФЛРРЎЈ
Хвёц¶ЇМ¬НјДЈРНИГОТГЗДЬ№»ФЪФЛРРµДК±єтРЮёДОТГЗНшВзјЬ№№Ј¬ХвКЗТтОЄЦ»УРµ±Хв¶ОґъВлФЛРРµДК±єтЈ¬ХвёцНјІЕДЬ№»ґґЅЁЎЈ
ХвТвО¶ЧЕТ»ёцНјФЪґъВлФЛРРµДЖЪјдЈ¬ДЬ№»ФЩґО¶ЁТеЈ¬ТтОЄДгІ»ДЬ№»МбЗ°¶ЁТеЎЈµ«КЗЈ¬ХвёцФЪѕІМ¬НјЦРКЗІ»їЙДЬµДЈ¬ФЪґъВлФЛРРЦ®З°ТЄґґЅЁНјЈ¬И»єуЦ®єуЅцЅцЦґРРЎЈ¶ЇМ¬НјєЬ·Ѕ±гµчКФЈ¬ТтОЄєЬИЭТЧ¶ЁО»µЅДгґнОуµДµШ·ЅЎЈ
8 Т»Р©јјЗЙ
8.1 requires_grad
ЛьКЗTensorАаµДТ»ёцКфРФЎЈД¬ИПКЗFalseЎЈµ±ДгТЄИҐ¶іЅбТ»Р©ІгµДК±єт»б±дµГИЭТЧЈ¬ІўЗТФЪСµБ·µДК±єтЈ¬ФЭНЈЛыГЗИҐёьРВІОКэЎЈДгїЙТФјтµҐЙиЦГrequires_gradОЄFalseЈ¬ІўЗТХвР©TensorІ»»бІОУлµЅјЖЛгНјЦРЎЈ

ТтґЛЈ¬Г»УРМЭ¶ИПтЛьГЗґ«ІҐЈ¬»тХЯДЗР©ТААµУЪДЗР©МЭ¶ИБчrequires_gradµДІгЎЈµ±ЙиЦГОЄTrueµДК±єтЈ¬requires_gradКЗїЙґ«ИѕµДЈ¬ХвТвО¶ЧЕѕЎ№ЬТ»ёцІЩЧч·ыµДІЩЧчКэµДrequires_gradЦГОЄTrueЈ¬Ль»№КЗХвёцЅб№ыЎЈ
8.2 torch.no_grad()
ФЪОТГЗјЖЛгМЭ¶ИµДК±єтЈ¬ОТГЗРиТЄ±ЈґжКдИлЦµєНЦРјдМШХчЈ¬ТтОЄєуГжЛьГЗїЙДЬРиТЄИҐјЖЛгМЭ¶ИЎЈ
b = w1*aПа¶ФУЪКдИлw1єНaµДМЭ¶И·Ц±рКЗaєНw1ЎЈФЪ·ґПтґ«ІҐµД№эіМЦРЈ¬ОТГЗРиТЄОЄМЭ¶ИјЖЛг±ЈґжХвР©ЦµЎЈХв»бУ°ПмХвёцНшВзµДДЪґжµДХјУГЎЈ
ФЪОТГЗФЛРРНЖАнµДК±єтЈ¬ОТГЗІўІ»јЖЛгМЭ¶ИЈ¬ТтґЛОТГЗІ»РиТЄИҐ±ЈґжХвР©ЦµЎЈКВКµЙПЈ¬ФЪНЖАнµД№эіМЦРЈ¬І»РиТЄґґЅЁНјЈ¬ТтОЄХв»бµјЦВОЮУГµДДЪґжПыєДЎЈ
ОЄБЛХвёцТЄЗуЈ¬PyTorchМṩБЛТ»ёцЙППВОД№ЬАнЖчЈ¬ЅРЧцtorch.no_grad
with torch.no_grad:inference code goes here ФЪХвёцЙППВОД№ЬАнЖчПВЈ¬ЦґРРФЛЛгІ»»б¶ЁТеНјЎЈ
9 ЅбВЫ
ФЪ±ѕОДµДЧоєуІї·ЦЈ¬ОТјтµҐЧЬЅбТ»ПВХвЖЄОДХВµДЦчТЄДЪИЭЈє
- јЖЛгНјЈєјЖЛгНј±ѕЦКЙПѕНКЗТ»ёцКэѕЭЅб№№Ј¬УРБЛјЖЛгНјОТГЗїЙТФёьЦ±№ЫµД±нКѕБґКЅЗуµј·ЁФтЎЈ
- AutogradДЈїйЈєЛьКЗPyTorchЅшРРМЭ¶ИјЖЛгµДДЈїйЈ¬µ±ОТГЗПЈНыТ»ёцTensorїЙТФЅшРРМЭ¶ИјЖЛгµДК±єтЈ¬ОТГЗТЄЙиЦГХвёц TensorµДrequires_gradОЄTrueЎЈРиТЄЧўТвЈ¬јЖЛгНјЦРµД·ЗТ¶ЧУЅбµгґжФЪgrad_fnЈ¬µ«КЗЈ¬Т¶ЧУЅбµгЈЁУГУЪґґЅЁµД±дБїЈ© І»ґжФЪµДЎЈ
- no_gradЈєФЪОТГЗЅшРРНЖАнµДК±єтЈ¬ОТГЗКЗІ»РиТЄјЖЛгМЭ¶ИµДЈ¬ТтґЛїЙТФФЪno_grad»·ѕіПВЅшРРНЖАнЎЈ
АнЅвAutogradєНјЖЛгНјКЗИзєО№¤ЧчµДЈ¬їЙТФёьјтµҐµШК№УГPyTorchЎЈУРБЛјбКµµД»щґЎЈ¬ПВТ»ЖЄОДХВЦРЈ¬ОТГЗ»бПкПёЅйЙЬИз№ыґґЅЁ¶ЁЦЖµДёґФУµДјЬ№№Ј¬Из№ыИҐґґЅЁ¶ЁЦЖµДКэѕЭ№ЬµАєНёь¶аУРИ¤µД¶«ОчЎЈ