XGBoost
extreme gradient boosting, ЪЧgradient boosting machineЕФгХЛЏЪЕЯжЃЌПьЫйгааЇЁЃ
- xgboostМђНщ
- xgboostЬиЕу
- xgboostЛљБОЪЙгУжИФЯ
- xgboostРэТлЛљДЁ
- supervise learning
- CART
- boosting
- gradient boosting
- xgboost
- xgboostЪЕеН
- ЬиеїЙЄГЬ
- ВЮЪ§ЕїгХ
1 - ГѕЪЖxgboost
- МђНщ
- гХЪЦ
- ЪЕеН
1.1 - МђНщ
xgboostЪЧgradient boosting machineЕФC++гХЛЏЪЕЯжЃЌgradient boosting machineЕФКЌвхЃК
- machineЃКЛњЦїбЇЯАФЃаЭЃЌ ЖдЪ§ОнВњЩњЕФЙцТЩНјааНЈФЃ
- boosting machineЃКЪЧвЛжжШѕбЇЯАЦїзщКЯГЩЧПбЇЯАЦїЕФФЃаЭ
- gradient boosting machineЃКИљОнЬнЖШЯТНЕЕФЗНЪНзщКЯШѕбЇЯАЦї
1.1.1 - machine
ЖдЪ§ОнНјааВњЩњЙцТЩНјааНЈФЃЕФЮЪЬтЭЈГЃЛсаЮЪНЛЏЮЊвЛИізюаЁЛЏФПБъКЏЪ§ЕФЮЪЬтЃЌФПБъКЏЪ§ЭЈГЃгаСНИіВПЗжзщГЩЃК
ФПБъКЏЪ§ЃК
- Ы№ЪЇКЏЪ§ЃЈбЁдёгыбЕСЗЪ§ОнЦЅХфзюКУЕФФЃаЭЃЉ
- ЛиЙщЃК (y^?y)2 ( y ^ ? y ) 2
- ЗжРр: 0-1Ы№ЪЇЃЌlogisticЫ№ЪЇЃЌКЯвГЫ№ЪЇЃЌжИЪ§Ы№ЪЇ
- е§дђЯюЃЈбЁдёзюМђЕЅЕФФЃаЭЃЉ
- L2е§дђ
- L1е§дђ
1.1.2 - boosting machine
- boosting: НЋШѕбЇЯАЦїзщКЯГЩЧПбЇЯАЦї
- ШѕбЇЯАЦїЃКОіВпЪї/ЗжРрЛиЙщЪїЃЈxgboostЕФШѕбЇЯАЦїЃЉ
- ОіВпЪїЃКвЖзгНсЕуЖдгІОіВп
- ЗжРрЛиЙщЪїЃКвЖзгНкЕуЖдгІдЄВтЗжЪ§
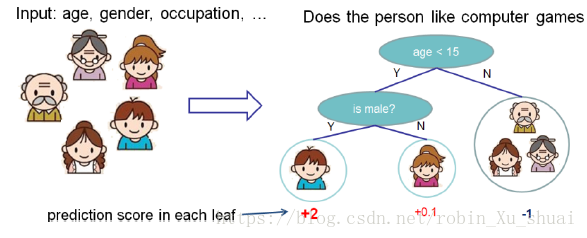
1.1.3 - gradient boosting machine
ОЕфЕФboosting machineЫуЗЈЪЧAdaboostЃЌadaboostЕФЫ№ЪЇКЏЪ§ЪЧжИЪ§Ы№ЪЇЃЌ friedmanНЋadaboostЭЦЙуЕНвЛАуЕФgradient boostingПђМмЃЌЕУЕНgradient boosting machineЃКНЋboostingЪгЮЊвЛИіЪ§жЕгХЛЏЕФЮЪЬтЃЌВЩгУРрЫЦгкЬнЖШЯТНЕЕФЗНЪНРДНјааЧѓНтЃЌетбљПЩвдЪЙгУШЮКЮПЩЮЂЕФЫ№ЪЇКЏЪ§ЃЌжЇГжЕФШЮЮёДгСНРрЗжРрРЉПэЕНЖрРрЗжРрЕШЁЃ
1.2 - xgboostгХЪЦ
ЬиЕуЃК
- е§дђЛЏЃКБъзМЕФGBMЃЈgradient boosting machineЃЉУЛгаЯдЪНЕФе§дђЛЏ
- ВЂаа
- здЖЈвхгХЛЏФПБъКЭЦРМлзМдђЃКашвЊЫ№ЪЇКЏЪ§ЕФвЛНзЕМЪ§КЭЖўНзЕМЪ§
- МєжІЃКЕБаТдіЗжСбДјРДЕФЪЧИКЪевцЕФЪБКђЃЌGBMЛсЭЃжЙЗжСбЃЌxgboostЛсвЛжБЗжСбЕНзюДѓЕФЩюЖШЃЌШЛКѓМєжІ
- жЇГждкЯпбЇЯА
- дкНсЙЙЛЏЪ§ОнЩЯБэЯжЭЛГіЃЌЩюЖШбЇЯАдкЗЧЛњЙЙЛЏЕФЪ§ОнЩЯБэЯжКУЁЃ
1.3 - ЪЕеНxgboost
1.3.1 - ДІРэЪ§ОнПЦбЇШЮЮёЕФвЛАуСїГЬ
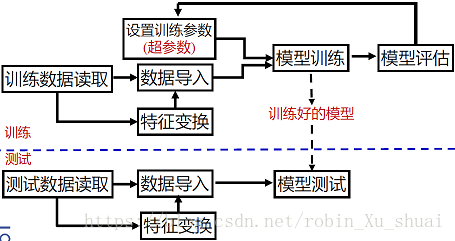
1.3.2 - ЛљгкsklearnПђМмЕФxgboostЪЙгУ
from sklearn.datasets import load_svmlight_file
from sklearn.metrics import accuracy_score
from xgboost import XGBClassifierЪ§ОнЖСШЁ
file_path = "./data/"
X_train, y_train = load_svmlight_file(file_path+"agaricus.txt.train")
X_test, y_test = load_svmlight_file(file_path+"agaricus.txt.test")print(X_train.shape, y_train.shape)(6513, 126) (6513,)
print(X_test.shape, y_test.shape)(1611, 126) (1611,)
ВЮЪ§НщЩмЃК
- max_depthЃК ЪїЕФзюДѓЩюЖШЁЃШБЪЁжЕЮЊ6
- learning_rateЃКЮЊСЫЗРжЙЙ§ФтКЯЃЌИќаТЙ§ГЬжагУЕНЕФЪеЫѕВНГЄЁЃдкУПДЮЬсЩ§МЦЫужЎКѓЃЌЫуЗЈЛсжБНгЛёЕУаТЬиеїЕФШЈжиЁЃ learning_rateЭЈЙ§ЫѕМѕЬиеїЕФШЈжиЪЙЬсЩ§МЦЫуЙ§ГЬИќМгБЃЪиЁЃШБЪЁжЕЮЊ0.3ЃЌШЁжЕЗЖЮЇЮЊЃК[0,1]
- slientЃКШЁ0ЪББэЪОДђгЁГідЫааЪБаХЯЂЃЌШЁ1ЪББэЪОвдМъФЌЗНЪНдЫааЃЌВЛДђгЁдЫааЪБаХЯЂЁЃШБЪЁжЕЮЊ0
- objectiveЃК ЖЈвхбЇЯАШЮЮёМАЯргІЕФбЇЯАФПБъЃЌЁАbinary:logisticЁБ БэЪОЖўЗжРрЕФТпМЛиЙщЮЪЬтЃЌЪфГіЮЊИХТЪ
ХфжУФЃаЭ
xgbc = XGBClassifier(max_depth=2, learning_rate=1, n_estimators=2, # number of iterations or number of treesslient=0,objective="binary:logistic")бЕСЗФЃаЭ
xgbc.fit(X_train, y_train)XGBClassifier(base_score=0.5, booster='gbtree', colsample_bylevel=1,colsample_bytree=1, gamma=0, learning_rate=1, max_delta_step=0,max_depth=2, min_child_weight=1, missing=None, n_estimators=2,n_jobs=1, nthread=None, objective='binary:logistic', random_state=0,reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=None,silent=True, slient=0, subsample=1)
бЕСЗЮѓВю
pred_train = xgbc.predict(X_train)
pred_train = [round(x) for x in pred_train]
train_score = accuracy_score(y_train, pred_train)
print("Train Accuracy: %.2f%%" % (train_score * 100))Train Accuracy: 97.77%
ВтЪдЮѓВю
pred_test = xgbc.predict(X_test)
pred_test = [1 if x >= 0.5 else 0 for x in pred_test]
print("Test Accuracy: %.2f%%" % (accuracy_score(y_test, pred_test) * 100))Test Accuracy: 97.83%
1.3.3 - бщжЄМЏ
НЋбЕСЗЪ§ОнЕФвЛВПЗжСєГіРДЃЌВЛВЮгыФЃаЭВЮЪ§бЕСЗЁЃСєГіРДЕФетВПЗж
Ъ§ОнГЦЮЊбщжЄМЏЃЈvalidation setЃЉ
- грЯТЕФЪ§ОнбЕСЗФЃаЭЃЌбЕСЗКУЕФФЃаЭдкбщжЄМЏЩЯВтЪд
- аЃбщМЏЩЯЕФадФмПЩЪгЮЊФЃаЭдкЮДжЊЪ§ОнЩЯадФмЕФЙРМЦ,бЁдёдкаЃбщМЏЩЯБэЯжзюКУЕФФЃаЭ
from sklearn.model_selection import train_test_splitЛЎЗжбЕСЗМЏКЭбщжЄМЏ
file_path = "./data/"
X_train, y_train = load_svmlight_file(file_path+"agaricus.txt.train")
X_test, y_test = load_svmlight_file(file_path+"agaricus.txt.test")X_train, X_validation, y_train, y_validation = train_test_split(X_train, y_train, test_size= 0.33, random_state=42)print(X_train.shape, y_train.shape)
print(X_validation.shape, y_validation.shape)(4363, 126) (4363,)
(2150, 126) (2150,)
xgbc = XGBClassifier(max_depth=2, learning_rate=1, n_estimators=2, slient=False, objective="binary:logistic")xgbc.fit(X_train, y_train, verbose=True)XGBClassifier(base_score=0.5, booster='gbtree', colsample_bylevel=1,colsample_bytree=1, gamma=0, learning_rate=1, max_delta_step=0,max_depth=2, min_child_weight=1, missing=None, n_estimators=2,n_jobs=1, nthread=None, objective='binary:logistic', random_state=0,reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=None,silent=True, slient=False, subsample=1)
# performance in validation set
pred_val = xgbc.predict(X_validation)
pred_val = [round(x) for x in pred_val]
print("Validation Accuracy: %2.f%%" % (accuracy_score(pred_val, y_validation) * 100))Validation Accuracy: 97%
# performance in train set
pred_train = xgbc.predict(X_train)
pred_train = [round(x) for x in pred_train]
print("Validation Accuracy: %2.f%%" % (accuracy_score(pred_train, y_train) * 100))Validation Accuracy: 98%
# performance in test set
pred_test = xgbc.predict(X_test)
pred_test = [round(x) for x in pred_test]
print("Validation Accuracy: %2.f%%" % (accuracy_score(pred_test, y_test) * 100))Validation Accuracy: 98%
1.3.4 - бЇЯАЧњЯп-ЙигкШѕЗжРрЦїЕФИіЪ§ЛђепЫЕЕќДњЕФДЮЪ§
import matplotlib.pyplot as pltn_iteration = 100xgbc = XGBClassifier(max_depth=2, learning_rate=0.1, n_estimators=n_iteration, objective="binary:logistic")
eval_set = [(X_train, y_train), (X_validation, y_validation)]
xgbc.fit(X_train, y_train, eval_set=eval_set, eval_metric=["error", "logloss"], verbose=True)[0] validation_0-error:0.044236 validation_0-logloss:0.614162 validation_1-error:0.051163 validation_1-logloss:0.615457
[1] validation_0-error:0.039193 validation_0-logloss:0.549179 validation_1-error:0.046512 validation_1-logloss:0.551203
[2] validation_0-error:0.044236 validation_0-logloss:0.494366 validation_1-error:0.051163 validation_1-logloss:0.497442
[3] validation_0-error:0.039193 validation_0-logloss:0.447845 validation_1-error:0.046512 validation_1-logloss:0.451486
[4] validation_0-error:0.039193 validation_0-logloss:0.407646 validation_1-error:0.046512 validation_1-logloss:0.411989
[5] validation_0-error:0.039193 validation_0-logloss:0.371941 validation_1-error:0.046512 validation_1-logloss:0.377037
[6] validation_0-error:0.022003 validation_0-logloss:0.341067 validation_1-error:0.026047 validation_1-logloss:0.346286
[7] validation_0-error:0.039193 validation_0-logloss:0.313232 validation_1-error:0.046512 validation_1-logloss:0.319077
[8] validation_0-error:0.039193 validation_0-logloss:0.288775 validation_1-error:0.046512 validation_1-logloss:0.294526
[9] validation_0-error:0.022003 validation_0-logloss:0.267046 validation_1-error:0.026047 validation_1-logloss:0.273228
[10] validation_0-error:0.004813 validation_0-logloss:0.247238 validation_1-error:0.008372 validation_1-logloss:0.253542
[11] validation_0-error:0.004813 validation_0-logloss:0.229689 validation_1-error:0.008372 validation_1-logloss:0.236248
[12] validation_0-error:0.010085 validation_0-logloss:0.210475 validation_1-error:0.015349 validation_1-logloss:0.216868
[13] validation_0-error:0.015586 validation_0-logloss:0.193727 validation_1-error:0.02093 validation_1-logloss:0.199968
[14] validation_0-error:0.015586 validation_0-logloss:0.179108 validation_1-error:0.02093 validation_1-logloss:0.185209
[15] validation_0-error:0.015586 validation_0-logloss:0.166333 validation_1-error:0.02093 validation_1-logloss:0.172308
[16] validation_0-error:0.015586 validation_0-logloss:0.15516 validation_1-error:0.02093 validation_1-logloss:0.16102
[17] validation_0-error:0.015586 validation_0-logloss:0.145382 validation_1-error:0.02093 validation_1-logloss:0.151137
[18] validation_0-error:0.015586 validation_0-logloss:0.13682 validation_1-error:0.02093 validation_1-logloss:0.142481
[19] validation_0-error:0.015586 validation_0-logloss:0.129854 validation_1-error:0.02093 validation_1-logloss:0.135452
[20] validation_0-error:0.015586 validation_0-logloss:0.122889 validation_1-error:0.02093 validation_1-logloss:0.128415
[21] validation_0-error:0.023608 validation_0-logloss:0.11724 validation_1-error:0.029302 validation_1-logloss:0.122718
[22] validation_0-error:0.023608 validation_0-logloss:0.111548 validation_1-error:0.029302 validation_1-logloss:0.116973
[23] validation_0-error:0.02017 validation_0-logloss:0.106935 validation_1-error:0.024186 validation_1-logloss:0.112492
[24] validation_0-error:0.02017 validation_0-logloss:0.102711 validation_1-error:0.024186 validation_1-logloss:0.108251
[25] validation_0-error:0.02017 validation_0-logloss:0.098366 validation_1-error:0.024186 validation_1-logloss:0.103854
[26] validation_0-error:0.02017 validation_0-logloss:0.094848 validation_1-error:0.024186 validation_1-logloss:0.100122
[27] validation_0-error:0.02017 validation_0-logloss:0.09125 validation_1-error:0.024186 validation_1-logloss:0.096787
[28] validation_0-error:0.02017 validation_0-logloss:0.087968 validation_1-error:0.024186 validation_1-logloss:0.093459
[29] validation_0-error:0.02017 validation_0-logloss:0.084816 validation_1-error:0.024186 validation_1-logloss:0.090229
[30] validation_0-error:0.02017 validation_0-logloss:0.081983 validation_1-error:0.024186 validation_1-logloss:0.087354
[31] validation_0-error:0.02017 validation_0-logloss:0.079313 validation_1-error:0.024186 validation_1-logloss:0.084619
[32] validation_0-error:0.012148 validation_0-logloss:0.074708 validation_1-error:0.015814 validation_1-logloss:0.080086
[33] validation_0-error:0.012148 validation_0-logloss:0.071661 validation_1-error:0.015814 validation_1-logloss:0.077247
[34] validation_0-error:0.02017 validation_0-logloss:0.069014 validation_1-error:0.024186 validation_1-logloss:0.074588
[35] validation_0-error:0.014669 validation_0-logloss:0.06648 validation_1-error:0.018605 validation_1-logloss:0.072239
[36] validation_0-error:0.009397 validation_0-logloss:0.064195 validation_1-error:0.011628 validation_1-logloss:0.069621
[37] validation_0-error:0.001375 validation_0-logloss:0.062203 validation_1-error:0.003256 validation_1-logloss:0.06757
[38] validation_0-error:0.001375 validation_0-logloss:0.060052 validation_1-error:0.003256 validation_1-logloss:0.065462
[39] validation_0-error:0.001375 validation_0-logloss:0.05799 validation_1-error:0.003256 validation_1-logloss:0.063569
[40] validation_0-error:0.001375 validation_0-logloss:0.056169 validation_1-error:0.003256 validation_1-logloss:0.061491
[41] validation_0-error:0.001375 validation_0-logloss:0.054376 validation_1-error:0.003256 validation_1-logloss:0.059743
[42] validation_0-error:0.009397 validation_0-logloss:0.052657 validation_1-error:0.011628 validation_1-logloss:0.058177
[43] validation_0-error:0.001375 validation_0-logloss:0.051002 validation_1-error:0.003256 validation_1-logloss:0.056733
[44] validation_0-error:0.001375 validation_0-logloss:0.049429 validation_1-error:0.003256 validation_1-logloss:0.054922
[45] validation_0-error:0.001375 validation_0-logloss:0.047924 validation_1-error:0.003256 validation_1-logloss:0.053362
[46] validation_0-error:0.001375 validation_0-logloss:0.046491 validation_1-error:0.003256 validation_1-logloss:0.051973
[47] validation_0-error:0.001375 validation_0-logloss:0.045115 validation_1-error:0.003256 validation_1-logloss:0.050731
[48] validation_0-error:0.001375 validation_0-logloss:0.04384 validation_1-error:0.003256 validation_1-logloss:0.049218
[49] validation_0-error:0.001375 validation_0-logloss:0.04261 validation_1-error:0.003256 validation_1-logloss:0.048026
[50] validation_0-error:0.001375 validation_0-logloss:0.041414 validation_1-error:0.003256 validation_1-logloss:0.046635
[51] validation_0-error:0.001375 validation_0-logloss:0.04024 validation_1-error:0.003256 validation_1-logloss:0.04559
[52] validation_0-error:0.001375 validation_0-logloss:0.039108 validation_1-error:0.003256 validation_1-logloss:0.044651
[53] validation_0-error:0.001375 validation_0-logloss:0.038046 validation_1-error:0.003256 validation_1-logloss:0.043404
[54] validation_0-error:0.001375 validation_0-logloss:0.036975 validation_1-error:0.003256 validation_1-logloss:0.042286
[55] validation_0-error:0.001375 validation_0-logloss:0.035982 validation_1-error:0.003256 validation_1-logloss:0.041341
[56] validation_0-error:0.001375 validation_0-logloss:0.035031 validation_1-error:0.003256 validation_1-logloss:0.040505
[57] validation_0-error:0.001375 validation_0-logloss:0.034135 validation_1-error:0.003256 validation_1-logloss:0.039399
[58] validation_0-error:0.001375 validation_0-logloss:0.033276 validation_1-error:0.003256 validation_1-logloss:0.038583
[59] validation_0-error:0.001375 validation_0-logloss:0.032452 validation_1-error:0.003256 validation_1-logloss:0.037861
[60] validation_0-error:0.001375 validation_0-logloss:0.031655 validation_1-error:0.003256 validation_1-logloss:0.036928
[61] validation_0-error:0.001375 validation_0-logloss:0.030869 validation_1-error:0.003256 validation_1-logloss:0.035987
[62] validation_0-error:0.001375 validation_0-logloss:0.030057 validation_1-error:0.003256 validation_1-logloss:0.035138
[63] validation_0-error:0.001375 validation_0-logloss:0.029379 validation_1-error:0.003256 validation_1-logloss:0.034418
[64] validation_0-error:0.001375 validation_0-logloss:0.028683 validation_1-error:0.003256 validation_1-logloss:0.033762
[65] validation_0-error:0.001375 validation_0-logloss:0.028014 validation_1-error:0.003256 validation_1-logloss:0.033187
[66] validation_0-error:0.001375 validation_0-logloss:0.027338 validation_1-error:0.003256 validation_1-logloss:0.032326
[67] validation_0-error:0.001375 validation_0-logloss:0.026727 validation_1-error:0.003256 validation_1-logloss:0.031581
[68] validation_0-error:0.001375 validation_0-logloss:0.026087 validation_1-error:0.003256 validation_1-logloss:0.031107
[69] validation_0-error:0.001375 validation_0-logloss:0.025474 validation_1-error:0.003256 validation_1-logloss:0.030427
[70] validation_0-error:0.001375 validation_0-logloss:0.024911 validation_1-error:0.003256 validation_1-logloss:0.029905
[71] validation_0-error:0.001375 validation_0-logloss:0.024368 validation_1-error:0.003256 validation_1-logloss:0.029239
[72] validation_0-error:0.001375 validation_0-logloss:0.023829 validation_1-error:0.003256 validation_1-logloss:0.028852
[73] validation_0-error:0.001375 validation_0-logloss:0.023316 validation_1-error:0.003256 validation_1-logloss:0.028419
[74] validation_0-error:0.001375 validation_0-logloss:0.02278 validation_1-error:0.003256 validation_1-logloss:0.027854
[75] validation_0-error:0.001375 validation_0-logloss:0.022305 validation_1-error:0.003256 validation_1-logloss:0.027263
[76] validation_0-error:0.001375 validation_0-logloss:0.021837 validation_1-error:0.003256 validation_1-logloss:0.026841
[77] validation_0-error:0.001375 validation_0-logloss:0.02139 validation_1-error:0.003256 validation_1-logloss:0.02647
[78] validation_0-error:0.001375 validation_0-logloss:0.020914 validation_1-error:0.003256 validation_1-logloss:0.02589
[79] validation_0-error:0.001375 validation_0-logloss:0.020452 validation_1-error:0.003256 validation_1-logloss:0.025369
[80] validation_0-error:0.001375 validation_0-logloss:0.020058 validation_1-error:0.003256 validation_1-logloss:0.024872
[81] validation_0-error:0.001375 validation_0-logloss:0.019648 validation_1-error:0.003256 validation_1-logloss:0.024367
[82] validation_0-error:0.001375 validation_0-logloss:0.019268 validation_1-error:0.003256 validation_1-logloss:0.023936
[83] validation_0-error:0.001375 validation_0-logloss:0.018878 validation_1-error:0.003256 validation_1-logloss:0.023496
[84] validation_0-error:0.001375 validation_0-logloss:0.018503 validation_1-error:0.003256 validation_1-logloss:0.023169
[85] validation_0-error:0.001375 validation_0-logloss:0.018148 validation_1-error:0.003256 validation_1-logloss:0.022877
[86] validation_0-error:0.001375 validation_0-logloss:0.017783 validation_1-error:0.003256 validation_1-logloss:0.022427
[87] validation_0-error:0.001375 validation_0-logloss:0.01746 validation_1-error:0.003256 validation_1-logloss:0.022145
[88] validation_0-error:0.001375 validation_0-logloss:0.017149 validation_1-error:0.003256 validation_1-logloss:0.021805
[89] validation_0-error:0.001375 validation_0-logloss:0.016832 validation_1-error:0.003256 validation_1-logloss:0.021546
[90] validation_0-error:0.001375 validation_0-logloss:0.016305 validation_1-error:0.003256 validation_1-logloss:0.020802
[91] validation_0-error:0.001375 validation_0-logloss:0.016013 validation_1-error:0.003256 validation_1-logloss:0.020549
[92] validation_0-error:0.001375 validation_0-logloss:0.015729 validation_1-error:0.003256 validation_1-logloss:0.02018
[93] validation_0-error:0.001375 validation_0-logloss:0.015467 validation_1-error:0.003256 validation_1-logloss:0.019926
[94] validation_0-error:0.001375 validation_0-logloss:0.015202 validation_1-error:0.003256 validation_1-logloss:0.019611
[95] validation_0-error:0.001375 validation_0-logloss:0.014931 validation_1-error:0.003256 validation_1-logloss:0.019267
[96] validation_0-error:0.001375 validation_0-logloss:0.014652 validation_1-error:0.003256 validation_1-logloss:0.018949
[97] validation_0-error:0.001375 validation_0-logloss:0.014399 validation_1-error:0.003256 validation_1-logloss:0.018651
[98] validation_0-error:0.001375 validation_0-logloss:0.014151 validation_1-error:0.003256 validation_1-logloss:0.018445
[99] validation_0-error:0.001375 validation_0-logloss:0.013908 validation_1-error:0.003256 validation_1-logloss:0.018252XGBClassifier(base_score=0.5, booster='gbtree', colsample_bylevel=1,colsample_bytree=1, gamma=0, learning_rate=0.1, max_delta_step=0,max_depth=2, min_child_weight=1, missing=None, n_estimators=100,n_jobs=1, nthread=None, objective='binary:logistic', random_state=0,reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=None,silent=True, subsample=1)
plt.rcParams["figure.figsize"] = (5., 3.)
result = xgbc.evals_result()epochs = len(result["validation_0"]["error"])fig, ax = plt.subplots()
ax.plot(list(range(epochs)), result["validation_0"]["error"], label="train")
ax.plot(list(range(epochs)), result["validation_1"]["error"], label="validation")
ax.legend()
plt.ylabel("error")
plt.xlabel("epoch")
plt.title("XGBoost error")
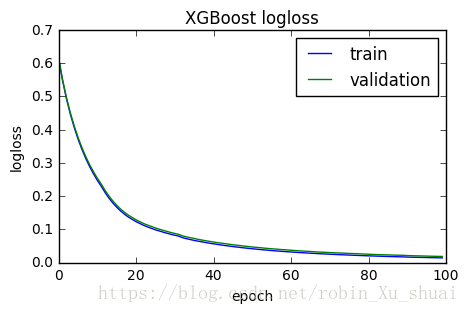
plt.show()fig, ax = plt.subplots()
ax.plot(list(range(epochs)), result["validation_0"]["logloss"], label="train")
ax.plot(list(range(epochs)), result["validation_1"]["logloss"], label="validation")
ax.legend()
plt.ylabel("logloss")
plt.xlabel("epoch")
plt.title("XGBoost logloss")
plt.show()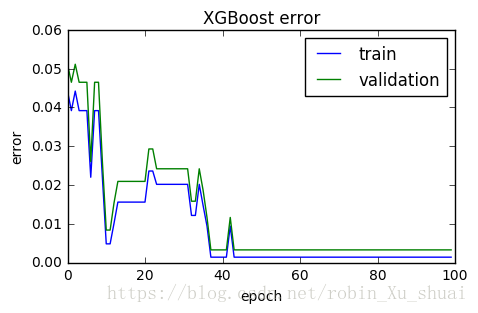
# performance in the test set
pred_test = xgbc.predict(X_test)
pred_test = [round(x) for x in pred_test]
print("Test Accuracy: %.2f%%" % (accuracy_score(y_test, pred_test) * 100))Test Accuracy: 99.81%
1.3.5 - early stop
вЛжжЗРжЙЙ§ФтКЯЕФЗНЗЈ
- МрПиФЃаЭдкаЃбщМЏЩЯЕФадФмЃКШчЙћдкОЙ§ЙЬЖЈДЮЪ§ЕФЕќДњЃЌаЃбщМЏЩЯЕФадФмВЛдйЬсИпЪБЃЌНсЪјбЕСЗЙ§ГЬ
eval_set = [(X_validation, y_validation)]
xgbc.fit(X_train, y_train, eval_set=eval_set, eval_metric="error", early_stopping_rounds=10, verbose=True)[0] validation_0-error:0.051163
Will train until validation_0-error hasn't improved in 10 rounds.
[1] validation_0-error:0.046512
[2] validation_0-error:0.051163
[3] validation_0-error:0.046512
[4] validation_0-error:0.046512
[5] validation_0-error:0.046512
[6] validation_0-error:0.026047
[7] validation_0-error:0.046512
[8] validation_0-error:0.046512
[9] validation_0-error:0.026047
[10] validation_0-error:0.008372
[11] validation_0-error:0.008372
[12] validation_0-error:0.015349
[13] validation_0-error:0.02093
[14] validation_0-error:0.02093
[15] validation_0-error:0.02093
[16] validation_0-error:0.02093
[17] validation_0-error:0.02093
[18] validation_0-error:0.02093
[19] validation_0-error:0.02093
[20] validation_0-error:0.02093
Stopping. Best iteration:
[10] validation_0-error:0.008372XGBClassifier(base_score=0.5, booster='gbtree', colsample_bylevel=1,colsample_bytree=1, gamma=0, learning_rate=0.1, max_delta_step=0,max_depth=2, min_child_weight=1, missing=None, n_estimators=100,n_jobs=1, nthread=None, objective='binary:logistic', random_state=0,reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=None,silent=True, subsample=1)
result = xgbc.evals_result()
plt.plot(list(range(len(result["validation_0"]["error"]))), result["validation_0"]["error"])
plt.ylabel("error")
plt.title("XGBoost error-early stop")
plt.show()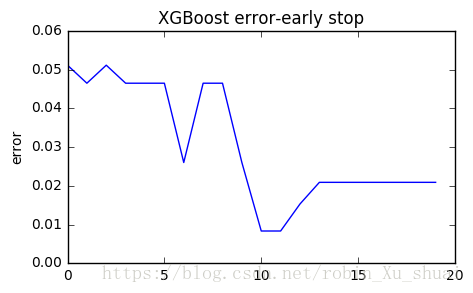
pred_test = xgbc.predict(X_test)
pred_test = [1 if x >= 0.5 else 0 for x in pred_test]
print("Train Accuracy: %.4f" % (accuracy_score(pred_test, y_test)))Train Accuracy: 0.9808
1.3.6 - НЛВцбщжЄcross validation
from sklearn.model_selection import StratifiedKFold
from sklearn.model_selection import cross_val_score
from sklearn import preprocessing
import warnings
warnings.filterwarnings(action='ignore', category=DeprecationWarning)kflods = StratifiedKFold(n_splits=10, random_state=42)
print(kflods)
results = cross_val_score(xgbc, X_train, y_train, cv=kflods)StratifiedKFold(n_splits=10, random_state=42, shuffle=False)
print(results)
print("%.2f%%, %.2f%%" % (results.mean() * 100, results.std() *100))[0.99771167 0.99771167 1. 1. 0.99542334 0.997706420.99770642 1. 1. 1. ]
99.86%, 0.15%
1.3.7 - GridSearchCV
from sklearn.grid_search import GridSearchCVxgbc = XGBClassifier(max_depth=2, objective="binary:logistic")
param_search = {"n_estimators":list(range(1, 10, 1)),"learning_rate":[x/10 for x in list(range(1, 11, 1))]
}
clf = GridSearchCV(estimator=xgbc, param_grid=param_search, cv=5)
clf.fit(X_train, y_train)GridSearchCV(cv=5, error_score='raise',estimator=XGBClassifier(base_score=0.5, booster='gbtree', colsample_bylevel=1,colsample_bytree=1, gamma=0, learning_rate=0.1, max_delta_step=0,max_depth=2, min_child_weight=1, missing=None, n_estimators=100,n_jobs=1, nthread=None, objective='binary:logistic', random_state=0,reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=None,silent=True, subsample=1),fit_params={}, iid=True, n_jobs=1,param_grid={'learning_rate': [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0], 'n_estimators': [1, 2, 3, 4, 5, 6, 7, 8, 9]},pre_dispatch='2*n_jobs', refit=True, scoring=None, verbose=0)
clf.grid_scores_[mean: 0.95576, std: 0.00954, params: {'learning_rate': 0.1, 'n_estimators': 1},mean: 0.95966, std: 0.01175, params: {'learning_rate': 0.1, 'n_estimators': 2},mean: 0.95576, std: 0.00954, params: {'learning_rate': 0.1, 'n_estimators': 3},mean: 0.95874, std: 0.01161, params: {'learning_rate': 0.1, 'n_estimators': 4},mean: 0.95966, std: 0.01175, params: {'learning_rate': 0.1, 'n_estimators': 5},mean: 0.95966, std: 0.01175, params: {'learning_rate': 0.1, 'n_estimators': 6},mean: 0.96997, std: 0.01554, params: {'learning_rate': 0.1, 'n_estimators': 7},mean: 0.96379, std: 0.01191, params: {'learning_rate': 0.1, 'n_estimators': 8},mean: 0.96402, std: 0.01220, params: {'learning_rate': 0.1, 'n_estimators': 9},mean: 0.95576, std: 0.00954, params: {'learning_rate': 0.2, 'n_estimators': 1},mean: 0.95920, std: 0.00824, params: {'learning_rate': 0.2, 'n_estimators': 2},mean: 0.97181, std: 0.01766, params: {'learning_rate': 0.2, 'n_estimators': 3},mean: 0.95966, std: 0.01175, params: {'learning_rate': 0.2, 'n_estimators': 4},mean: 0.97570, std: 0.01759, params: {'learning_rate': 0.2, 'n_estimators': 5},mean: 0.97937, std: 0.01934, params: {'learning_rate': 0.2, 'n_estimators': 6},mean: 0.98212, std: 0.00940, params: {'learning_rate': 0.2, 'n_estimators': 7},mean: 0.98441, std: 0.00484, params: {'learning_rate': 0.2, 'n_estimators': 8},mean: 0.97914, std: 0.00751, params: {'learning_rate': 0.2, 'n_estimators': 9},mean: 0.95576, std: 0.00954, params: {'learning_rate': 0.3, 'n_estimators': 1},mean: 0.95576, std: 0.00954, params: {'learning_rate': 0.3, 'n_estimators': 2},mean: 0.97800, std: 0.00585, params: {'learning_rate': 0.3, 'n_estimators': 3},mean: 0.96081, std: 0.00956, params: {'learning_rate': 0.3, 'n_estimators': 4},mean: 0.98441, std: 0.00320, params: {'learning_rate': 0.3, 'n_estimators': 5},mean: 0.97937, std: 0.00397, params: {'learning_rate': 0.3, 'n_estimators': 6},mean: 0.98556, std: 0.00426, params: {'learning_rate': 0.3, 'n_estimators': 7},mean: 0.97823, std: 0.00579, params: {'learning_rate': 0.3, 'n_estimators': 8},mean: 0.97983, std: 0.00604, params: {'learning_rate': 0.3, 'n_estimators': 9},mean: 0.95576, std: 0.00954, params: {'learning_rate': 0.4, 'n_estimators': 1},mean: 0.95576, std: 0.00954, params: {'learning_rate': 0.4, 'n_estimators': 2},mean: 0.97800, std: 0.00585, params: {'learning_rate': 0.4, 'n_estimators': 3},mean: 0.96768, std: 0.00711, params: {'learning_rate': 0.4, 'n_estimators': 4},mean: 0.97548, std: 0.00642, params: {'learning_rate': 0.4, 'n_estimators': 5},mean: 0.97479, std: 0.00660, params: {'learning_rate': 0.4, 'n_estimators': 6},mean: 0.98419, std: 0.00493, params: {'learning_rate': 0.4, 'n_estimators': 7},mean: 0.99083, std: 0.00576, params: {'learning_rate': 0.4, 'n_estimators': 8},mean: 0.99335, std: 0.00255, params: {'learning_rate': 0.4, 'n_estimators': 9},mean: 0.95576, std: 0.00954, params: {'learning_rate': 0.5, 'n_estimators': 1},mean: 0.95576, std: 0.00954, params: {'learning_rate': 0.5, 'n_estimators': 2},mean: 0.97593, std: 0.00416, params: {'learning_rate': 0.5, 'n_estimators': 3},mean: 0.97112, std: 0.00926, params: {'learning_rate': 0.5, 'n_estimators': 4},mean: 0.98694, std: 0.00395, params: {'learning_rate': 0.5, 'n_estimators': 5},mean: 0.98143, std: 0.00603, params: {'learning_rate': 0.5, 'n_estimators': 6},mean: 0.99198, std: 0.00507, params: {'learning_rate': 0.5, 'n_estimators': 7},mean: 0.99404, std: 0.00443, params: {'learning_rate': 0.5, 'n_estimators': 8},mean: 0.99862, std: 0.00134, params: {'learning_rate': 0.5, 'n_estimators': 9},mean: 0.95576, std: 0.00954, params: {'learning_rate': 0.6, 'n_estimators': 1},mean: 0.95554, std: 0.00936, params: {'learning_rate': 0.6, 'n_estimators': 2},mean: 0.97548, std: 0.00642, params: {'learning_rate': 0.6, 'n_estimators': 3},mean: 0.97410, std: 0.00751, params: {'learning_rate': 0.6, 'n_estimators': 4},mean: 0.98304, std: 0.00653, params: {'learning_rate': 0.6, 'n_estimators': 5},mean: 0.99244, std: 0.00792, params: {'learning_rate': 0.6, 'n_estimators': 6},mean: 0.99771, std: 0.00218, params: {'learning_rate': 0.6, 'n_estimators': 7},mean: 0.99794, std: 0.00222, params: {'learning_rate': 0.6, 'n_estimators': 8},mean: 0.99862, std: 0.00134, params: {'learning_rate': 0.6, 'n_estimators': 9},mean: 0.95576, std: 0.00954, params: {'learning_rate': 0.7, 'n_estimators': 1},mean: 0.97387, std: 0.01725, params: {'learning_rate': 0.7, 'n_estimators': 2},mean: 0.97823, std: 0.00610, params: {'learning_rate': 0.7, 'n_estimators': 3},mean: 0.97983, std: 0.00726, params: {'learning_rate': 0.7, 'n_estimators': 4},mean: 0.99060, std: 0.00275, params: {'learning_rate': 0.7, 'n_estimators': 5},mean: 0.99427, std: 0.00162, params: {'learning_rate': 0.7, 'n_estimators': 6},mean: 0.99679, std: 0.00183, params: {'learning_rate': 0.7, 'n_estimators': 7},mean: 0.99702, std: 0.00186, params: {'learning_rate': 0.7, 'n_estimators': 8},mean: 0.99702, std: 0.00186, params: {'learning_rate': 0.7, 'n_estimators': 9},mean: 0.95576, std: 0.00954, params: {'learning_rate': 0.8, 'n_estimators': 1},mean: 0.97227, std: 0.00856, params: {'learning_rate': 0.8, 'n_estimators': 2},mean: 0.98075, std: 0.00708, params: {'learning_rate': 0.8, 'n_estimators': 3},mean: 0.98579, std: 0.00674, params: {'learning_rate': 0.8, 'n_estimators': 4},mean: 0.99404, std: 0.00577, params: {'learning_rate': 0.8, 'n_estimators': 5},mean: 0.99794, std: 0.00255, params: {'learning_rate': 0.8, 'n_estimators': 6},mean: 0.99885, std: 0.00102, params: {'learning_rate': 0.8, 'n_estimators': 7},mean: 0.99908, std: 0.00086, params: {'learning_rate': 0.8, 'n_estimators': 8},mean: 0.99862, std: 0.00134, params: {'learning_rate': 0.8, 'n_estimators': 9},mean: 0.95576, std: 0.00954, params: {'learning_rate': 0.9, 'n_estimators': 1},mean: 0.97937, std: 0.00397, params: {'learning_rate': 0.9, 'n_estimators': 2},mean: 0.98900, std: 0.00809, params: {'learning_rate': 0.9, 'n_estimators': 3},mean: 0.98487, std: 0.00689, params: {'learning_rate': 0.9, 'n_estimators': 4},mean: 0.99496, std: 0.00438, params: {'learning_rate': 0.9, 'n_estimators': 5},mean: 0.99565, std: 0.00302, params: {'learning_rate': 0.9, 'n_estimators': 6},mean: 0.99931, std: 0.00056, params: {'learning_rate': 0.9, 'n_estimators': 7},mean: 0.99817, std: 0.00200, params: {'learning_rate': 0.9, 'n_estimators': 8},mean: 0.99817, std: 0.00200, params: {'learning_rate': 0.9, 'n_estimators': 9},mean: 0.95576, std: 0.00954, params: {'learning_rate': 1.0, 'n_estimators': 1},mean: 0.97937, std: 0.00397, params: {'learning_rate': 1.0, 'n_estimators': 2},mean: 0.98969, std: 0.00763, params: {'learning_rate': 1.0, 'n_estimators': 3},mean: 0.98648, std: 0.00519, params: {'learning_rate': 1.0, 'n_estimators': 4},mean: 0.99450, std: 0.00197, params: {'learning_rate': 1.0, 'n_estimators': 5},mean: 0.99633, std: 0.00152, params: {'learning_rate': 1.0, 'n_estimators': 6},mean: 0.99817, std: 0.00200, params: {'learning_rate': 1.0, 'n_estimators': 7},mean: 0.99931, std: 0.00056, params: {'learning_rate': 1.0, 'n_estimators': 8},mean: 0.99931, std: 0.00056, params: {'learning_rate': 1.0, 'n_estimators': 9}]
clf.best_score_0.9993123997249599
clf.best_params_{'learning_rate': 0.9, 'n_estimators': 7}
pred_val = clf.predict(X_validation)
print("Validation Accuracy: %.2f%%" % (accuracy_score(y_validation, [round(x) for x in pred_val])))Validation Accuracy: 1.00%
pred_test = clf.predict(X_test)
print("Test Accuracy: %.2f%%" % (accuracy_score(y_test, [round(x) for x in pred_test])))