��ר������ https://lilianweng.github.io/lil-log/2018/04/08/policy-gradient-algorithms.html ˳������ܽ� ��
����Ŀ¼
- ԭ������
-
- ���⽨ģ
- �㷨�ܹ�ͼ
- ѧϰ����
- ģ��ѵ�����
- ģ���ص�
- �㷨ʵ��
-
- ��������
- ����ʵ��
MADDPG\color{red}MADDPGMADDPG ��[ paper | code ]
ԭ������
�������������ĽǶ������������Ƿ�ƽ���ģ���Ϊ����������IJ����ںܿ�ظ��²���һֱ��δ֪�ġ�MADDPG��һ������������Ƶ���Ա���ۼ��㷨��ר�����ڴ������ֲ��ϱ仯�Ļ����Լ�������֮��Ļ�����
�㷨�� DDPG �㷨�ڶ�������ϵͳ�µ���Ȼ��չ���������Ļ�ѵ����ȥ���Ļ�ִ�����㷨��ܡ�
�Ľ�֮���� �� Qֵ�����Ľ�ģ�����У�ͨ�����������������������嵱ǰ���Բ������Ķ�����Ϊ������Ϣ��������������峡���µĻ�����ƽ��������
���⽨ģ
- ���� NNN ��������
- ������״̬�ռ�Ϊ SSS
- ÿ��������ӵ���Լ��Ķ����ռ� A1,��,ANA_1,��,A_NA1?,��,AN? �Լ��۲�ռ� O1,��,ONO_1,��,O_NO1?,��,ON?
- ״̬ת�ƺ����������е�״̬�������Լ��۲�ռ� T:S��A1����AN?ST:S��A1����AN?ST:S��A1����AN?S��
- ÿ���������Լ���������Խ����õ������Լ��Ĺ۲��Լ��������Ц�i:Oi��Ai?[0,1]��_{��i}:Oi��Ai?[0,1]����i?:Oi��Ai?[0,1] ��һ�������������۲��¹��ڶ����ĸ��ʷֲ�������һ��ȷ���Բ��ԣ��̦�i:Oi?Ai��_{��i}:Oi?Ai����i?:Oi?Ai ��
��o?=o1,��,oN,��?=��1,��,��N\vec{o}=o_{1}, \ldots, o_{N}, \vec{\mu}=\mu_{1}, \ldots, \mu_{N}o=o1?,��,oN?,��?=��1?,��,��N? ���Ҳ������� ��?=��1,��,��N\vec{\theta}=\theta_{1}, \dots, \theta_{N}��=��1?,��,��N? �������ġ�
MADDPG�е����ۼ�Ϊ�� iii �������壨ÿ�������壩ѧϰһ�����Ļ��Ķ���-ֵ���� Qi��?(o?,a1,��,aN)Q_{i}^{\vec{\mu}}\left(\vec{o}, a_{1}, \ldots, a_{N}\right)Qi��??(o,a1?,��,aN?)������ a1��A1,��,aN��ANa_{1} \in \mathcal{A}_{1}, \ldots, a_{N} \in \mathcal{A}_{N}a1?��A1?,��,aN?��AN? ������������Ķ�����ÿһ�� Qi��?,i=1,��,NQ_{i}^{\vec{\mu}},\;i=1, \dots, NQi��??,i=1,��,N ���Ƕ���ѧϰ�ģ����ÿ�����������ӵ��������ʽ�Ļر������������������������ͻ�Ļر�������ͬʱ��ÿ����������Ե���Ա��Ҳ�Ƕ���̽���Լ��������²��Բ��� ��i��_i��i?
��Ա���£�
?��iJ(��i)=Eo?,a?D[?aiQi��?(o?,a1,��,aN)?��i�̦�i(oi)�Oai=�̦�i(oi)]\nabla_{\theta_{i}} J\left(\theta_{i}\right)=\mathbb{E}_{\vec{o}, a \sim D}\left[\nabla_{a_{i}} Q_{i}^{\vec{\mu}}\left(\vec{o}, a_{1}, \ldots, a_{N}\right) \nabla_{\theta_{i}} \mu_{\theta_{i}}\left.\left(o_{i}\right)\right|_{a_{i}=\mu_{\theta_{i}}\left(o_{i}\right)}\right]?��i??J(��i?)=Eo,a?D?[?ai??Qi��??(o,a1?,��,aN?)?��i??����i??(oi?)�Oai?=����i??(oi?)?]
���� D ��ʾ����طŻ��壬���������켣���� (o?,a1,��,aN,r1,��,rN,o?��)\left(\vec{o}, a_{1}, \ldots, a_{N}, r_{1}, \ldots, r_{N}, \vec{o}^{\prime}\right)(o,a1?,��,aN?,r1?,��,rN?,o��) ���� ������ǰ���Ϲ۲� o?\vec{o}o��ÿ��������ֱ�ִ�ж��� a1,��,aNa_{1}, \dots, a_{N}a1?,��,aN? ���ȡ���ԵĻر� r1,��,rNr_{1}, \dots, r_{N}r1?,��,rN? , ��ת�Ƶ���һ�����Ϲ۲� o?��\vec{o}^{\prime}o��
���ۼҸ��£�
L(��i)=Eo?,a1,��,aN,r1,��,rN,o?��[(Qi��?(o?,a1,��,aN)?y)2]���� y=ri+��Qi��?��(o?��,a��1,��,a��N)�Oa��j=�̡���j; TDĿ��ֵ!\begin{aligned} \mathcal{L}(\theta_i) &= \mathbb{E}_{\vec{o}, a_1, \dots, a_N, r_1, \dots, r_N, \vec{o}��}[ (Q^{\vec{\mu}}_i(\vec{o}, a_1, \dots, a_N) - y)^2 ] & \\ \text{���� } y &= r_i + \gamma Q^{\vec{\mu}��}_i (\vec{o}��, a��_1, \dots, a��_N) \rvert_{a��_j = \mu��_{\theta_j}} & \scriptstyle{\text{; TDĿ��ֵ!}} \end{aligned}L(��i?)���� y?=Eo,a1?,��,aN?,r1?,��,rN?,o��?[(Qi��??(o,a1?,��,aN?)?y)2]=ri?+��Qi��?��?(o��,a��1?,��,a��N?)�Oa��j?=������j????; TDĿ��ֵ!?
���У� ��?��\vec{\mu}^{\prime}��?�� ���ӳ������²�����Ŀ����ԡ�
��ÿһ��Critic���²���ʱ����Ҫ֪������Actor�� (s,a=��(s),r,snext,a��=�̡�(s))(s, a=��(s), r, s_next, a'=��'(s))(s,a=��(s),r,sn?ext,a��=����(s)), ���� a��a'a�� ������Target Policy��
Ϊ�˻�����о�����Э����ϵ��������֮������������������ĸ߷��MADDPG���������һ�������������Լ�����
- Ϊ����������ѵ�� KKK �����ԣ�
- ���ѡȡһ���������Թ켣������
- ʹ�� KKK �����Եļ����ݶ������в������¡�
��֮��MADDPG��DDPG֮���������������ⲿ�֣�ʹ����Ӧ�������廷����
- ���Ļ����ۼ�+ȥ���Ļ���Ա��
- �������ܹ�ʹ�ù��Ƶ�����������IJ���������ѧϰ��
- ���Լ����ܹ��ܺõļ�С���
�㷨�ܹ�ͼ
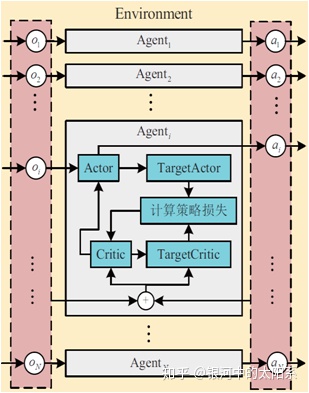
ģ�������DDPG������ɣ�ÿ������ѧϰpolicy �Ц��� (Actor) �� action value Q (Critic)��ͬʱ����target network������Q-learning��off-policyѧϰ��

ѧϰ����

- ������ͼ�������ռ����ݼ�ִ�в����Ƿֱ���еģ�ѵ��ѧϰ��ͳһ���еġ�
- ����Actor�ռ����� (s,a=��(s),r,snext,a��=�̡�(s))(s, a=��(s), r, s_next, a'=��'(s))(s,a=��(s),r,sn?ext,a��=����(s))��������Replay Buffer�����������������Ԥ����ֵʱ����ʼѧϰ��
- ÿ��Actor�ֱ����policy �Ц��� ��������DDPGһ����ֻ��Ҫ��ǰ (s,a=��(s))(s, a=��(s))(s,a=��(s))��
- ÿ��Critic�ֱ����action value Q������ע��ÿ��Critic���ܿ������е�Actor�ռ������ݣ����²���ʱ�ῼ������Actor���ɵ����ݣ����Ż�����ÿ��Critic��ȫ�ֵĹ������
- �ظ�2��3��4��ֱ��������
ģ��ѵ�����
ѵ�����̲�ȡ����ѵ������ɢִ�еķ�ʽ����ÿ������������������Եõ���ǰ״ִ̬�еĶ��������뻷�������õ�������������ľ��黺��ء��������������뻷��������ÿ��������Ӿ�����������ȡ����ѵ�����Ե������硣
Ϊ�����������ѧϰ���̣�Critic ���������Ҫ��������������Ĺ۲�״̬�Ͳ�ȡ�Ķ�����ͨ����С����ʧ�Ը�Critic �������������ͨ���ݶ��½���������¶�������IJ�����
��������ǿ��ѧϰһ����̵�����������ÿ��������IJ��Զ��ڸ��µ������»������һ���ض����������Ƕ�̬���ȶ��ġ���������ھ����������������أ����������һ������������侺�����ֹ���ϳ�һ��ǿ���ԡ��������ǿ�����Ƿdz������ģ�Ҳ������ϣ���õ��ģ���Ϊ���ž������ֲ��Եĸ��¸ı䣬���ǿ���Ժ���ȥ��Ӧ�µĶ��ֲ��ԡ�

ģ���ص�
- ͨ������Actor-Critic��DDPG��Ϊ�����ṹ����������������⡣
- �����ز�����ͳһ��ѧϰ��
- ͨ������Actor����������Q��ֵ����ϵͳ�Ƚ�ƽ�����Ż���
- ���û�жԻ��������ƣ�ÿ��Agent�������Լ���Reward��������������������Э�����Ǿ�����
- ����ÿ��Agent������ʱֻ��Ҫ��ǰActor�����ݽ���Ԥ�⣻ѵ���Ͳ����������ݲ�һ�������Ǹ����µ㡣
�㷨ʵ��
��������
��
����ʵ��
���������https://github.com/xuehy/pytorch-maddpg
from model import Critic, Actor
import torch as th
from copy import deepcopy
from memory import ReplayMemory, Experience
from torch.optim import Adam
from randomProcess import OrnsteinUhlenbeckProcess
import torch.nn as nn
import numpy as np
from params import scale_rewarddef soft_update(target, source, t):for target_param, source_param in zip(target.parameters(),source.parameters()):target_param.data.copy_((1 - t) * target_param.data + t * source_param.data)def hard_update(target, source):for target_param, source_param in zip(target.parameters(),source.parameters()):target_param.data.copy_(source_param.data)class MADDPG:def __init__(self, n_agents, dim_obs, dim_act, batch_size,capacity, episodes_before_train):self.actors = [Actor(dim_obs, dim_act) for i in range(n_agents)]self.critics = [Critic(n_agents, dim_obs,dim_act) for i in range(n_agents)]self.actors_target = deepcopy(self.actors)self.critics_target = deepcopy(self.critics)self.n_agents = n_agentsself.n_states = dim_obsself.n_actions = dim_actself.memory = ReplayMemory(capacity)self.batch_size = batch_sizeself.use_cuda = th.cuda.is_available()self.episodes_before_train = episodes_before_trainself.GAMMA = 0.95self.tau = 0.01self.var = [1.0 for i in range(n_agents)]self.critic_optimizer = [Adam(x.parameters(),lr=0.001) for x in self.critics]self.actor_optimizer = [Adam(x.parameters(),lr=0.0001) for x in self.actors]if self.use_cuda:for x in self.actors:x.cuda()for x in self.critics:x.cuda()for x in self.actors_target:x.cuda()for x in self.critics_target:x.cuda()self.steps_done = 0self.episode_done = 0def update_policy(self):# do not train until exploration is enoughif self.episode_done <= self.episodes_before_train:return None, NoneByteTensor = th.cuda.ByteTensor if self.use_cuda else th.ByteTensorFloatTensor = th.cuda.FloatTensor if self.use_cuda else th.FloatTensorc_loss = []a_loss = []for agent in range(self.n_agents):transitions = self.memory.sample(self.batch_size)batch = Experience(*zip(*transitions))non_final_mask = ByteTensor(list(map(lambda s: s is not None,batch.next_states)))# state_batch: batch_size x n_agents x dim_obsstate_batch = th.stack(batch.states).type(FloatTensor)action_batch = th.stack(batch.actions).type(FloatTensor)reward_batch = th.stack(batch.rewards).type(FloatTensor)# : (batch_size_non_final) x n_agents x dim_obsnon_final_next_states = th.stack([s for s in batch.next_statesif s is not None]).type(FloatTensor)# for current agentwhole_state = state_batch.view(self.batch_size, -1)whole_action = action_batch.view(self.batch_size, -1)self.critic_optimizer[agent].zero_grad()current_Q = self.critics[agent](whole_state, whole_action)non_final_next_actions = [self.actors_target[i](non_final_next_states[:,i,:]) for i in range(self.n_agents)]non_final_next_actions = th.stack(non_final_next_actions)non_final_next_actions = (non_final_next_actions.transpose(0,1).contiguous())target_Q = th.zeros(self.batch_size).type(FloatTensor)target_Q[non_final_mask] = self.critics_target[agent](non_final_next_states.view(-1, self.n_agents * self.n_states),non_final_next_actions.view(-1,self.n_agents * self.n_actions)).squeeze()# scale_reward: to scale reward in Q functionstarget_Q = (target_Q.unsqueeze(1) * self.GAMMA) + (reward_batch[:, agent].unsqueeze(1) * scale_reward)loss_Q = nn.MSELoss()(current_Q, target_Q.detach())loss_Q.backward()self.critic_optimizer[agent].step()self.actor_optimizer[agent].zero_grad()state_i = state_batch[:, agent, :]action_i = self.actors[agent](state_i)ac = action_batch.clone()ac[:, agent, :] = action_iwhole_action = ac.view(self.batch_size, -1)actor_loss = -self.critics[agent](whole_state, whole_action)actor_loss = actor_loss.mean()actor_loss.backward()self.actor_optimizer[agent].step()c_loss.append(loss_Q)a_loss.append(actor_loss)if self.steps_done % 100 == 0 and self.steps_done > 0:for i in range(self.n_agents):soft_update(self.critics_target[i], self.critics[i], self.tau)soft_update(self.actors_target[i], self.actors[i], self.tau)return c_loss, a_lossdef select_action(self, state_batch):# state_batch: n_agents x state_dimactions = th.zeros(self.n_agents,self.n_actions)FloatTensor = th.cuda.FloatTensor if self.use_cuda else th.FloatTensorfor i in range(self.n_agents):sb = state_batch[i, :].detach()act = self.actors[i](sb.unsqueeze(0)).squeeze()act += th.from_numpy(np.random.randn(2) * self.var[i]).type(FloatTensor)if self.episode_done > self.episodes_before_train and\self.var[i] > 0.05:self.var[i] *= 0.999998act = th.clamp(act, -1.0, 1.0)actions[i, :] = actself.steps_done += 1return actions