An Overview of Multi-Task Learning in Deep Neural Networks
����Ŀ¼
- An Overview of Multi-Task Learning in Deep Neural Networks
-
-
- ժҪ
- 1. ����
- 2. ����
- 3. �������ѧϰ������ѧϰ����
-
- 3.1. Ӳ��������
- 3.2. ����������
- 4. Ϊʲô������ѧϰ��Ч��
-
- 4.1. ������������ǿ
- 4.2. ע�����۽�
- 4.3. ����
- 4.4. ��ʾƫ��
- 4.5. ����
- 5. ��������ģ���еĶ�����ѧϰ
-
- 5.1. ��ϡ������
- 5.2. ѧϰ�����ϵ
- 6. ���ѧϰ������ѧϰ���������
-
- 6.1. ��ȹ�ϵ����
- 6.2. ��ȫ����Ӧ��������
- 6.3. ʮ��������
- 6.4. �Ͳ�ල
- 6.5. ���ϵĶ�����ģ��
- 6.6. ���ò�ȷ���Լ�Ȩ��ʧ
- 6.7. ������ʽ�ֽ������ѧϰ
- 6.8. ˮբ����
- 6.9. Ӧ����ģ���й���ʲô��
- 7. ��������
-
- 7.1. ��ص�����
- 7.2. �Կ�
- 7.3. ��ʾ
- 7.4. �۽�ע����
- 7.5. ����ƽ��
- 7.6. Ԥ������
- 7.7. ����δ��Ԥ�ǰ
- 7.8. ��ʾѧϰ
- 7.9. ʲô�����������а����ģ�
- 8. ����
-
ժҪ
������ѧϰ�Ѿ��ڻ���ѧϰ�ĺܶ�����ȡ�óɹ���������Ȼ���Դ���������ʶ�𡢼�����Ӿ���ҩ��֡�����ּ�ڸ���������ѧϰ�ĸ���������������������緽��Ķ�����ѧϰ�����Ľ��������ѧϰ��������õĶ�����ѧϰ�������������ⷽ��ĸ����������������½�չ���ر��ǣ���ͨ������������ѧϰ�Ĺ���ԭ�����ṩѡ���ʵ����������ָ������������ѧϰ��ҵ��Ӧ�ö�����ѧϰ��
1. ����
�ڻ���ѧϰ�У�����ͨ����ע�Ż�һ���ض��Ķ�����Ϊ��������㣬����ͨ��ѵ��һ��ģ�ͻ�����һЩģ����ʵ��������Ҫ������Ȼ����������Щģ��ֱ�����ܲ�������������ͨ�����ַ�������ͨ��Ҳ��ȡ�ÿ��Խ��ܵ����ܣ�����������רע�ڵ����������Ǻ�����һЩ�ܰ����������ø��õ���Ϣ��������˵����Щ��Ϣ������������ѵ���źš�ͨ�������������ı�ʾ��������ʹ��ģ�͵ķ����������á����ַ�ʽ��Ϊ������ѧϰ��
������ѧϰ�Ѿ��ڻ���ѧϰ�ĺܶ�����ȡ�óɹ���������Ȼ���Դ���������ʶ�𡢼�����Ӿ���ҩ��֡�������ѧϰ�кܶ���ʽ������ѧϰ��ѧ��ѧϰ�����ø�������ѧϰ��Щ�����Ѿ�������ָ��������ѧϰ��ͨ����ֻҪ�����Ż�����ʧ��������һ������������������ѧϰ������Щ����£�����������ȷ��˼�����ڸ��ݶ�����ѧϰ��ʲô�������õ���������
��ʹ��ijЩ���ͳ���ֻ��Ҫ�Ż�һ����ʧ��һ����������Ҳ�л������������������ܡ�Caruana��1998������ܽ��˶�����ѧϰ��Ŀ�ģ�������ѧϰͨ��������������ѵ���ź��а������ض�������Ϣ����߷���������
�ڱ����У����ǽ������ֽζ�����ѧϰ�ĸ������������������������Ķ�����ѧϰ���ڶ��ڴӲ�ͬ�Ƕȸ���������ѧϰ�Ķ����������ڽ����������ѧϰ����õĶ�����ѧϰ���������Ľ�������һЩ��������Щ������ͬ������Ϊʲô������ѧϰ��ʵ������Ч���ڹ�ע�Ƚ��Ļ���������Ķ�����ѧϰ����֮ǰ���ڵ���ڸ�����һЩ������ѧϰ��ص����ݡ������ڽ�����������������������Ķ�����ѧϰ����������ڵ��߽�������һЩ�㷺ʹ�õĸ�������������ʲô�Ƕ�����ѧϰ�кõĸ�������
2. ����
���ԴӲ�ͬ�ĽǶȿ�������ѧϰ�Ķ�����
- ������Ƕȿ���������ѧϰ���Կ�����������ѧϰ����������ѧϰ�µ�����ʱ�����Ǿ������ô�����������Ѿ�ѧϰ����֪ʶ��
- �ӽ�ѧ�Ƕȿ������Ǿ�������ѧϰһЩ�ṩ��Ҫ���ܵ�������Щ���ܿ��Ա��������ո����ӵļ������ٸ����ӣ����ֵ���ʦ�Ƚ�С��һЩ����ȥ�ص��������ĥ�ذ��������������������Щ��֤���Ǻ�ѧϰ���ֵ���ص��ۼ��ܡ�
- �ӻ���ѧϰ�ĽǶȿ���������ѧϰ���Կ�����һ�ֹ���Ǩ�ơ�����Ǩ��ͨ������һ������ƫ������ģ��������������ƫ��ʹ��ģ��ƫ��һЩ���衣���磬һ�ֹ���ƫ��ij�����ʽ��L1������ʹ��ģ��ƫ��ϡ��⡣�ڶ�����ѧϰ�У�����ƫ��ͨ�����������ṩ������������ʹ��ģ��ƫ����Щ�ܽ��Ͷ������ļ��衣���Ǻܿ���ܿ�������ͨ�����¸��õķ������ܡ�
3. �������ѧϰ������ѧϰ����
��ĿǰΪֹ�������Ѿ��۽��˶�����ѧϰ�����۶�����Ϊ��ʹ������ѧϰ�Ĺ۵�����壬�������ڽ������������������ʵ�ֶ�����ѧϰ��������õķ����������ѧϰ�����£�������ѧϰͨ��ͨ�����ز��Ӳ��������������������ʵ�֡�
3.1. Ӳ��������
Ӳ������������������ʵ�ֶ�����ѧϰ��õķ�������������ݵ�1993�ꡣ��ͼ1��ʾ��Ӳ��������ͨ��ͨ������������������ز�ʵ�֣����ᱣ��һЩ��Ծ���������������
Ӳ������������ػ����˹���ϵķ��ա���ʵ�ϣ���1997������о���������Ϲ��������ķ���Ҫ�ȹ�����ض�������IJ�����������㣩��������СN��ֱ�۵ؿ���������壺ͬʱѧϰ������Խ�࣬ģ��Խ���ò�����һ���ܺ�����������ı��������ԭʼ������Խ�����������

3.2. ����������
�������������У�ÿ���������Լ���ģ�ͺͲ�����Ȼ��ͨ������ģ�Ͳ����ľ������������������������ͼ2��ʾ��Duong��2015��ʹ��L2��������������Yang��Hospedales��2017��ʹ�õ���trace norm��
���������������������������Լ���ܵ��˶�����ѧϰ���������ļ����������ü�����Ӧ����������ģ���С�

4. Ϊʲô������ѧϰ��Ч��
���ܴӶ�����ѧϰ�л�õĹ���ƫ������ȥ�Ǻ����ģ�Ϊ�˸��õ����������ѧϰ��������Ҫ��һ��������Ļ�����������Щ�Ĵ����������Caruana��1998������������������У����Ǽ���������ص�����A��B������������һ�����������ز��ʾF��
4.1. ������������ǿ
������ѧϰ��Ч��������ѵ�����ݵ�����������������������������һ���̶ȵ�����������ij������A����ѵ��ʱ�����ǵ�Ŀ����ѧϰһ����A��˵����ı�ʾ���ñ�ʾ�����������������������нϺõķ�������**����ͬ�������в�ͬ������ģʽ��һ��ͬʱѧϰ���������ģ����ѧ����ͨ�õı�ʾ**��ֻѧϰ����A���ж�A����ϵķ��գ�������ѧϰA��Bʹ��ģ���ܹ�ͨ����ͬ����ģʽ��ƽ�����һ�����õı�ʾF��
4.2. ע�����۽�
���һ������ʮ�����ӻ��������������Ҹ�ά�ģ�ģ�ͺ������ֳ���غ��ص�������������ѧϰ�ܰ���ģ�Ͱ�ע�����۽���������Ҫ������������Ϊ����������ṩ����������Ժ����ԵĶ���֤�ݡ�
4.3. ����
��Щ����G������B�к�����ѧϰ������������A�к���ѧϰ�������������ΪA��һ�ָ����ӵķ�ʽ��G��������������Ϊ��һЩ�����谭��ģ��ѧϰG��������������������ķ�����ͨ����ʾ����Abu-Mostafa��1990����о�����������ֱ��ѵ��ģ����Ԥ������Ҫ��������
4.4. ��ʾƫ��
������ѧϰƫ��ģ��ѧϰ��Щ��������Ҳƫ���ı�ʾ��Baxter��2000����о���������Ҳ��������ģ�ͽ�������������������Ϊ�����㹻���ѵ�����������õļ���ռ䣬����ѧϰȫ������Ҳ���������ã�ֻҪ��������ͬһ������
4.5. ����
�������ѧϰͨ���������ƫ��ʵ�������������������˹���ϵķ����Լ�ģ�͵�Rademacher���Ӷȣ�����������������������
5. ��������ģ���еĶ�����ѧϰ
Ϊ�˸��õ��������ѧϰ�еĶ�����ѧϰ���������ǽ��о��й�����ģ�͡��˷����Լ���Ҷ˹�㷨�����еĶ�����ѧϰ������ס�����أ����ǽ����������ڶ�����ѧϰ��ʷ��ʼ�մ��ڵ�˼·��1. ͨ����������ǿ�Ʋ�ͬ����֮���ϡ������2. �������ϵ���н�ģ��
ע��ܶ������еĶ�����ѧϰ�������Ǵ���ͬ���趨�ģ����Ǽ����������͵���������������磬ͨ����������mnist���ݼ�ת��Ϊ10�����������������о��������Ǹ���ʵ�ġ����ʵ��趨��ÿ������Ͷ�һ���������ء�
5.1. ��ϡ������
5.2. ѧϰ�����ϵ
6. ���ѧϰ������ѧϰ���������
���ܺܶ���������ѧϰ������ʹ���˶�����ѧϰ����������ʽ�ػ�����ʽ�ء�����Ϊģ�͵�һ���֣�������Ȼʹ�õ���ǰ���ᵽ�����ַ�����Ӳ����������������������ֻ��һЩ���Ĺ�ע�ڷ�չ���ѧϰ�и��õĶ�����ѧϰ���ơ�
6.1. ��ȹ�ϵ����
�ڼ�����Ӿ���ʹ�ö�����ѧϰʱ��ͨ�����������㣬��ȫ���Ӳ���Ϊ�������IJ����ѧϰ��Long��Wang��2015��ͨ�������ȹ�ϵ�����Ľ�����Щģ�͡����˹��������������Ľṹ��������ȫ���Ӳ���ʹ������������ʹ��ģ����ѧ����ͬ����֮��Ĺ�ϵ����ͼ3��ʾ����ǰ�������ı�Ҷ˹ģ�����ơ��������ַ�������������ǰ���干���Ľṹ������ܶ��ڳ���о��ļ�����Ӿ�����ʱ�㹻�ģ������������к����׳�����

6.2. ��ȫ����Ӧ��������
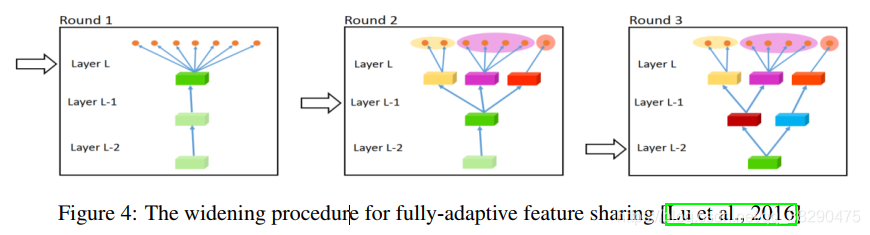
����һ�����˳�����Lu��2016�����һ�����¶��ϵ�ģ�ͣ���ģ�ʹ���С�������������ѵ��������ʹ��һ�ִٽ������������ı�̰���ض�̬�ӿ�����ṹ�����ּӿ����̣���̬�ش����˷�֧����ͼ4��ʾ����������̰�����Կ��ܲ��ܷ���ȫ�����Ž⣬ͬʱ��ÿ����֧����һ��ȷ�е�����Ҳ����ʹ��ģ��ѧϰ������֮�临�ӵ����ϵ��
6.3. ʮ��������
��������������������Misra������2016��������ֿ���ģ�ͽṹ������Ȼ������ʹ��һ��ʮ���嵥Ԫ������ģ��ͨ��ѧϰǰһ�������������ϣ���ȷ����������������Ժ��ַ�ʽ�������������֪ʶ����������Ľṹ��ͼ5��ʾ��ֻ�ڳػ���ȫ���Ӳ��ʹ��ʮ���嵥Ԫ��

6.4. �Ͳ�ල
�෴������Ȼ���Դ�����NLP���У�����Ĺ����ص���Ϊ������ѧϰ�ҵ����õ������νṹ��S��gaard��Goldberg��2016������ͼ�������NLP��ͨ����ΪԤ��������������Ա�Ǻ�����ʵ��ʶ��Ӧ�ñ��ڵͲ���Ϊ�������ල��
6.5. ���ϵĶ�����ģ��
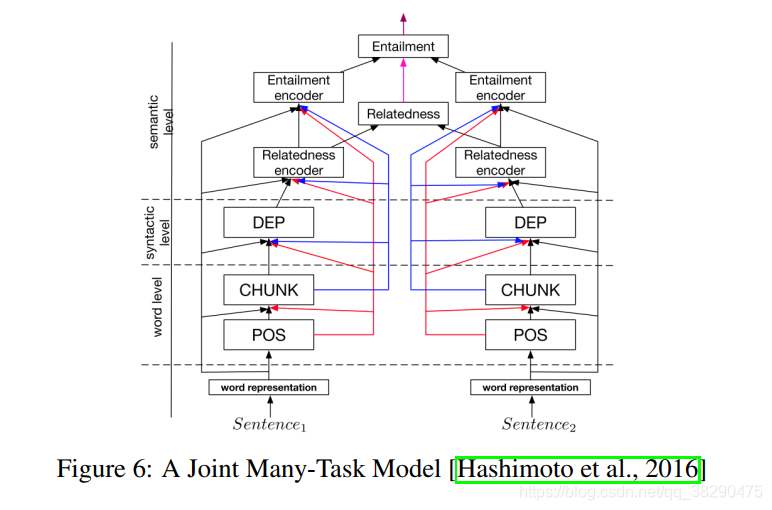
������һ���֣�Hashimoto������2016Ԥ�������ɶ��NLP������ɵķֲ���ϵ�ṹ�����Խ�����Ϊ������ѧϰ������ģ�ͣ���ͼ6��ʾ��
6.6. ���ò�ȷ���Լ�Ȩ��ʧ
������ζ�ſ��Ժ�ģ����ķ�����ϡ�
��֪��ȷ���ԣ�żȻ��ȷ���ԣ�żȻ��ȷ���Է�Ϊ�����������������������֡�
����ѧϰ�����ṹ��Kendall������2017�������һ�������ķ�����ͨ������ÿ������IJ�ȷ������Ȼ��������ۺ�����ÿ����������Ȩ�ء����Ȩ��ͨ���Ƶ�һ����������������ȷ�������˹��Ȼ�Ķ�������ۺ����õ���������ÿ��������Ȼع顢�����ʵ���ָ��������ģ����ͼ7��ʾ��

6.7. ������ʽ�ֽ������ѧϰ
����Ĺ�����ͼ�������ѧϰMTL�����з�����Yang��Hospedales��2017��ʹ��������ʽ�ֽ⽫ģ�Ͳ����ֽ�Ϊÿһ��Ĺ����������ض�������IJ������Ӷ�������һЩ��ǰ���۵ľ�����ʽ�ֽⷽ����
6.8. ˮբ����
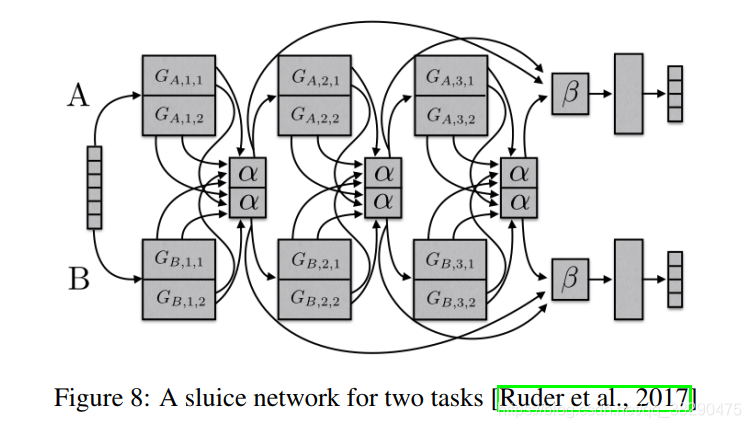
���Ruder������2017�����һ��ˮբ�����������纭����һЩ�������ѧϰ�Ķ�����ѧϰ����������Ӳ����������ʮ�������硢��ϡ���������Լ������NLP��ʹ�õ�����㼶������ģ�ͽṹ��ͼ8��ʾ����ģ���ܹ�ѧϰ����Щ����ӿռ�Ӧ�ñ��������Լ�����Щ�������Ѿ�ѧ�����������е����ű�ʾ��
6.9. Ӧ����ģ���й���ʲô��
�����ܽ��������һЩ������������ܽ�һ������ȶ�����ѧϰģ����Ӧ�ù���Щʲô����ʷ�Ϻܶ�Ķ�����ѧϰ�����۽����˲�ͬ���������ͬ�ֲ��ij�������Ȼ��������������ڹ����ģ�������������ˡ�Ϊ�˷�չ���Ƚ��Ķ�����ѧϰģ�ͣ����DZ����ܴ�����Щ�ػ�������ص�����
��Ȼ���ѧϰ������ѧϰ�����ڹ����Ѿ�Ԥ��ָ����ÿ������Ҫ�����IJ㣬�������ֲ�������չ�����һ�����Ӱ�������ѧϰ�Ľṹ��Ӳ����������������1993������ķ�������20�����Ȼ��һ�ַ�ʽ�������ںܶೡ�϶�����Ч�ģ������������������صĻ�����Ҫ�ڲ�ͬ�㼶�Ͻ���������Ӳ���������ͻ�ܿ��ʧЧ���������ķ���ת��ѧϰ��Ҫ���������ݣ�����ͨ������Ӳ�������������⣬����ģ��ѧϰ����㼶���������а����ģ���������Ҫ��ͬ���ȵij��ϡ�
������ᵽ��������ֻҪ�����Ż�����һ����ʧ���������Ǿ��ڽ��ж�����ѧϰ������ͨ��Լ��ģ�Ͳ��������������֪ʶѹ������ͬ�IJ����ռ䣬�����������Ѿ����۹��Ķ�����ѧϰ����ؽ�չ��ʹ���ǵ�ģ��ѧϰ����֮��Ľ�����ʽ���⽫���а����ġ�
7. ��������
�����ǵ�Ŀ����һ�λ�ö�������Ԥ��ֵʱ��������ѧϰʮ����Ȼ����������ܳ����������ڽ��ڻ�ѧԤ���У����ǿ���ϣ��Ԥ������������ָ��ļ�ֵ����������Ϣѧ�У����ǿ���ϣ��ͬʱԤ����ּ�����֢״����ҩ��ֵȳ����У�ӦԤ����ʮ�������ֻ��Ի���������������������ӣ�������ѧϰ��ȷ�Խ�������ߡ�
���ǣ��ڴ��������£�����ֻ����һ����������ܡ� ��ˣ��ڱ����У����ǽ��о�����ҵ����ʵĸ��������Ա����ܴӶ�����ѧϰ�����档
7.1. ��ص�����
�����ѡ����ʹ�����������Ϊ������ѧϰ�ĸ������� Ϊ��Ū������������ʲô�����ǽ��ṩһЩͻ����ʾ���� Caruanaʹ��Ԥ���·���Ե�������Ϊ����������Ԥ���Զ���ʻ������ת���� Zhang���˽�ͷ�����ƹ��ƺ��沿�����ƶ������沿�����ĸ������� Liu��������ѧϰ��ѯ�������ҳ������ Girshick����Ԥ��ͼ���ж�����������ꣻAr?k����Ԥ���������ϳɵ����س���ʱ���Ƶ�ʷֲ���
7.2. �Կ�
ͨ�����������ı�ǩ�����Dz����õġ� ���ǣ���ijЩ����£����ǿ��Ի��������Ҫʵ�ֵ������෴������ ���������ݿ���ͨ���Կ���ʧ�������ã��Կ�����ʧʹ���ݶ���ת�������ѵ���� �����������������������Ӧ����ܳɹ�������������£��Կ���������Ԥ����������� ͨ����ת�Կ�������ݶȣ��Կ��������ʧ����������Ҫ�����������ģ���Ϊ����ʹģ��ѧϰ������������ı�ʾ��ʽ��
7.3. ��ʾ
��ǰ����������ʹ�ö�����ѧϰ��ѧϰ��ʹ��ԭʼ������ܲ�����ѧϰ��������ʵ�ִ�Ŀ�ĵ���Ч������ʹ����ʾ����������Ԥ��Ϊ������������Ȼ���Դ��������ֲ��Ե�����������Yu��Jiang�ijɹ������ǽ�Ԥ��������Ӱ���������д���Ϊ��з����ĸ�������Cheng��������Ԥ��������Ƿ����������Ϊ���ƴ�����ĸ�������
7.4. �۽�ע����
ͬ����������������ڽ�ע��������������ͨ�����ܻ���Ե�ͼ���ϡ����磬����ѧϰת������ģ��ͨ�����ܻ���Գ�����ǣ���Ϊ��Щ��ռͼ���һС���֣����Ҳ����Ǵ��ڡ�Ȼ�������������Ԥ��Ϊ�����������ʹģ��ѧϰ��ʾ���ǣ�Ȼ����Щ֪ʶҲ����������Ҫ�������Ƶأ������沿ʶ�����ǿ��ܻ�ѧ��Ԥ���沿��־��λ����Ϊ����������Ϊ��Щ��־ͨ�������ڲ�ͬ�ġ�
7.5. ����ƽ��
������������ѵ��Ŀ���������ģ�����Ȼ�����Ķ������ܸ�����������ǩ������Ϊ��ɢ��ʹ�á���������Ҫ�˹��������ռ����ݵ�����£�����Ԥ�⼲�����գ����磬��/��/�ߣ�����������������/����/���ԣ�ʱ�����������������Щ����£�ʹ�������̶Ƚϵ͵ĸ���������ܻ�������������Ϊ���ǵ�Ŀ���ƽ������˸�����ѧϰ��
7.6. Ԥ������
��ijЩ����£���ijЩ������Ϊ�����Dz���ʵ�ʵģ���Ϊ���Ƕ�Ԥ������Ҫ��Ŀ��û�а��������ǣ���Щ����������Ȼ����ָ�������ѧϰ������Щ����£���Щ����������������������롣Caruana��de Sa�����˼�������ʹ�����ַ��������⡣
7.7. ����δ��Ԥ�ǰ
����������£�ijЩ����ֻ���ڽ���Ԥ��֮��ſ��á����磬�����Զ���ʻ������ֻ�����������ϰ���ͳ�����ǣ����ܶ����ǿ��Խ��и�ȷ�IJ�����Caruana�����˷���Ԥ������ӣ���Ԥ��֮������ҽѧ����Ľ�����ܵõ��� ������Щʾ�����������ݲ���������������Ϊ������ѵ��ʱ���������롣 ���ǣ����ǿ���Ϊ����������ѵ��������Ϊģ��������֪ʶ��
7.8. ��ʾѧϰ
������ѧϰ�У����������Ŀ����ʹģ���ܹ�ѧϰ����Ҫ�����������õı�ʾ��ʽ����ĿǰΪֹ���������۵ĸ�����������ʽִ�еģ���������Ҫ����������أ����ѧϰ���ǿ���ʹģ��ѧϰ���õı�ʾ��ʽ������ȷ�Ľ�ģ�ǿ��ܵģ���������һ����֪��ʹģ��ѧϰ����Ǩ�Ʊ�ʾ��ʽ������Cheng���˺�Rei�����õ����Խ�ģ����Ϳ�������һ���á� ͬ�����Զ�����������Ҳ����������������
7.9. ʲô�����������а����ģ�
���������������˲�ͬ�ĸ���������Щ�����������������ֻ��עһ����������������ʹ�ö�����ѧϰ��������Ȼ��֪����ʵ����ʲô������������Ч�ġ�ѡ��������ػ��������ļ��裺��������Ӧ�ú���������ijЩ��������������ĸ��������Ԥ�����������а����ġ�
���ǣ����ǻ��Dz������ʱӦ������������Ϊ���ƻ������Caruana��Ϊ�������������ʹ����ͬ�Ĺ��ܽ��о��ߣ���ô���������Ƶġ�Baxter����������Ϊ����ص�������һ����ͬ����Ѽ����࣬��������ͬ�Ĺ���ƫ�Ban��Schuller��������������������ݶ�����ʹ��һ��任F�ӹ̶��ĸ��ʷֲ������ɣ���������������F��ء�����������˿���ʹ�ò�ͬ�Ĵ�������ͬһ�����������ռ����ݣ���ʹ�ò�ͬ�ǶȺ��������������λĿ��ʶ���ռ����ݣ������ܽ��Ͳ�ͬ��������ͬ����������Xue��Ϊ�������������ķ���߽�ܽ��������������ܽӽ��������������Ƶġ�
������������������Է�������Щ�������۽�չ�������ⷽ��û��̫�����µĽ�չ�����������Բ��Ƕ����Ƶģ����Ƿֲ������ϡ������ǵ�ģ��ֱ��ѧϰÿ�������������ݿ���ʹ��������ʱ�����������ϵ�ȱ�������������������ʱҲ�ܺܺõ����ã������ǻ�����Ҫ��Զ�����ѧϰ����һ����ԭ���Ե����������Եĸ���������Dz�֪��Ӧ��ѡ����Щ����
���Alonso��Plank�Ĺ������־��н����Ҿ��ȱ�ǩ�ֲ��ĸ���������ڽ��NLP�е����б���������а����ģ�������ʵ�����Ѿ�֤ʵ����һ�㡣�����Ѿ����֣�������Ҫ������ԣ��ڷ�ƽ�ȸ���������Ѹ��ƽ�ȵ���Ҫ������п��ܻ�����档����ĿǰΪֹ����Щʵ��ķ�Χ�������ģ�����ķ��ֽ��ṩ�˸������˽��������ж�����ѧϰ�ij���������
8. ����
��ƪ�����ع��˶�����ѧϰ����ʷ�Լ���������ѧϰ�ж�����ѧϰ�ķ�չ�����ܶ�����ѧϰ���ڱ�����Ƶ��ʹ�ã�����20����ʷ��Ӳ��������������Ȼ�ڻ���������Ķ�����ѧϰ�������ڡ����������ѧϰʲô�ù������о��ǿ��еġ�ͬʱ�����ǹ�����������⡪�����������ԡ���ϵ���㼶���ͶԶ�����ѧϰ�ĺô�������Ȼ�����ޣ�������Ҫ�ⷽ�������о����Ա���õ����������ѧϰ����������緽��ķ���������