论文:Deep Multi-Patch Matching Network for Visible Thermal Person Re-Identification
出处:IEEE TMM 2020
1.创新点
本文的创新点在于,将特征图水平分割成不同数量的水平条纹,学习粗粒度和细粒度的特征。对每个水平条纹计算三元组损失、模态对齐损失、多个条纹之间的关系损失。最后,根据每个条纹的三元组三重误差,对每个条纹损失进行加权求和,优先优化困难的条纹。在计算模态对齐损失时,加入FC层当作模态对准器,寻找模态差异最大的子空间,在子空间内减小模态差异,通过最小最大策略优化主干网络和模态对准器。在条纹关系损失中,考虑到相同图像对在不同条纹中差异度相似、相同ID图像对比不同ID图像对的差异度小两个关系,很好的对各条纹进行了互补。
2.网络框架
本文提出了一个多补丁匹配网络(MPMN),来学习跨模态图像的粗粒度和细粒度的视觉语义信息。网络主要包括两个学习模块,resnet50的一些残差块、多补丁平均池化(MPAP)。MPAP通过将特征图分成不同数量的水平条纹,来学习多粒度的补丁特性。
首先,由于可见图像和热图像有不同的颜色通道,我们将它们都转换为具有单一通道的灰色图像。由于预训练模型是在三通道上训练的,所以把灰色图像的通道复制为三个通道。
将图像经过resnet50提取特征,将提取出的特征F划分为g个水平条纹,g从1到G变换,可以挖掘粗粒度和细粒度的视觉语义。
然后用传统的全局平均池(GAP)分别映射为g个局部特征向量,那么会得到N=G(G+1)/2个特征向量。所有的特征向量都通过一个FC层和BN层,将特征维度D降维为D/N,最后将所有特征向量连接起来得到最终向量(维度为D)。

3.损失函数
训练的时候需要设置损失函数来更新网络权重参数。对于每一个补丁(N=G(G+1)/2),要求三个损失函数,最后加权求和。
(1)三元组损失
假设每个特征图总共被切成了N块,经过GAP、FC、BN之后生成N个特征向量。对对每个特征向量分别求一个三元组损失,最后加权作为总三元组损失。(由PAPA提供加权参数,j表示第几个补丁patch)
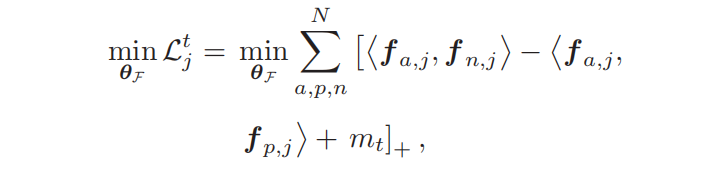
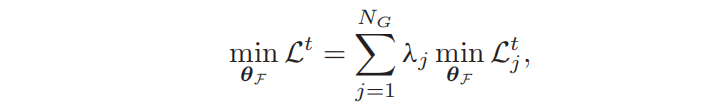
(2)多补丁模态对齐(MPMA)
VTReID的一个主要挑战是,两种模式的特征分布可能非常不同,导致模型泛化性差,收敛速度慢。具体地说,在输出特征后直接添加模态对齐约束可能是有害的,因为很难知道哪个维数包含最大的模态差异。
因此,它将需要选择性的对齐行为,只关注某些最容易减少当前分布差异的维或子空间。另外,以往的VTReID工作只考虑全局特征的模态差异,不考虑局部模态间隙,因此局部特征的模态分布可能不能很好地对齐,从而导致一个劣质的跨模态性能。
为解决上述问题,本文呢提出了多补丁模态对齐损失,同时平衡和减少多个补丁之间的模态差异。具体地,构造了一个由MPMA损失训练的轻量级模态对准器,挖掘一个具有大模态差异的特征子空间,然后在这个子空间内对齐模态分布。
Maximize Subspace Discrepancy(训练模态对准器):本文使用一个FC层(维度P = C/4)来当作模态对准器,为了探索模态差异较大的特征子空间,一种简单而有效的方法就是,学习最大限度地提高子空间模态差异的最优模态对准器。请注意,等式中的梯度只被反向传播到θA,主干网络θF是固定的。通过最大化下列等式,可以使不同模式的子空间特征分布更加明显。k和l表示不同的ID。

Minimize Subspace Discrepancy(训练主干网络):在获得了最优的模态对准器后,就需要在子空间内最小化模态差异。等式中的梯度只被反向传播到主干网络θF,θA是固定的。只训练主干网络,从而获得模态不相关的特征。
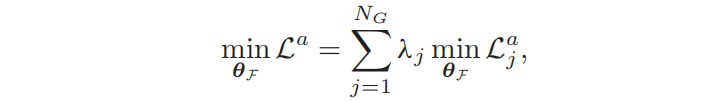
Adversarial Subspace Learning(对抗子空间学习):我们联合优化上述两个等式,由于这两个目标函数的优化目标是相反的,这个过程作为一个极大极小博弈运行,导致了一个对抗性的学习问题。
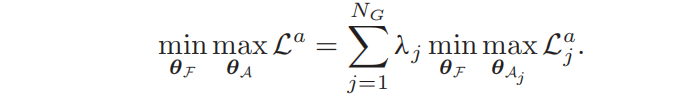
(3) 跨补丁相关性蒸馏(CPCD)
一般来说,粗粒度特征具有鲁棒性,但鉴别性较差,而细粒度特征具有鉴别性,但鲁棒性较差。因此,如果跨补丁的相关性被有效地利用,这两种特征可以很好的互补。受知识蒸馏的影响,本文提出了一种跨补丁的相关性蒸馏损失,将一个补丁的语义知识转移到另一个补丁。根据不同补丁的两个特征对的相似度,我们组成了两种类型的相关性。
Positive Cross-Patch Correlation:假设我们在第k个补丁上获得补丁对(fak、fbk),在第j个补丁上获得补丁对(faj、fbj),a=b,因为它们都来自相同的图像对(xa、xb),两个图像在不同的补丁中的差异性应该相似 。因此,这两个补丁对之间的相关性是正的。我们期望来自同一图像对的两个补丁特征相似性差异应该小于一个margin。k和j表示第几个补丁。
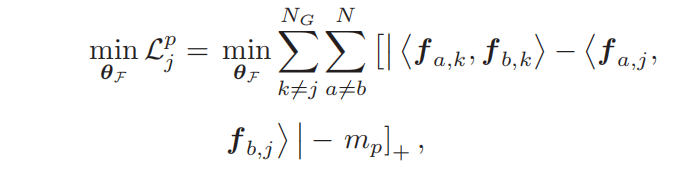
Negative Cross-Patch Correlation:假设我们有两个不同的补丁对(fak、fpk)和(faj、fnj),图像a和p是同一ID,a和n是不同ID。那么不同ID的补丁对应该大于相同ID补丁对一个margin。
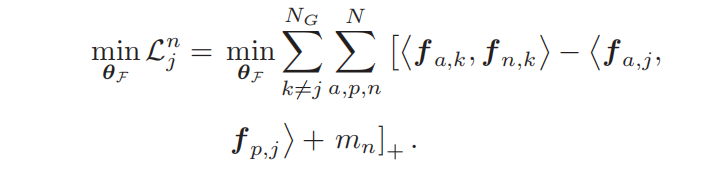
将正负跨补丁相关性联合起来,一起优化
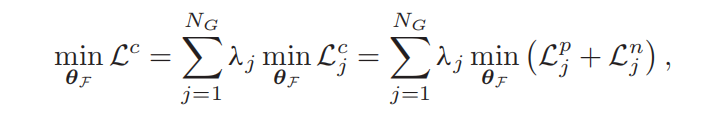
(4)补丁注意力权重(PAPA)
对每个补丁的总损失加权。通过自适应地为更困难的补丁分配更多的权重,对困难的补丁任务设定优先级。对于每个补丁,λj应该是一个有意义的度量,所以我们使用三重损失Ltj的三重误差Ej=Ne/Nt来表示任务难度。Nt是所有输入三元组的数量,而Ne是违反margin边缘约束的三元组的数量。
使用标准化的三重误差,Nn是训练总epoch,n是当前epoch。一开始σ(n)比较小,对所有的补丁平等对待,随着网络的训练,比较困难的补丁会赋予更高的权重。
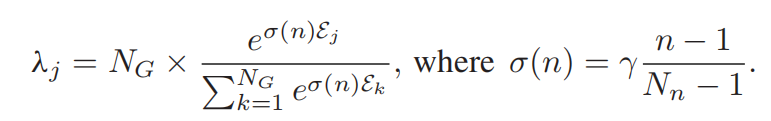
(5)总损失

4.实验指标

