Paper: Generative Adversarial Nets
Author: Ian J. Goodfellow et al.
Publication: 2014, NIPS
文章目录
- 1 背景
- 2 创新点
- 3 核心方法
- 4 理论推导
-
- 4.1 训练算法
- 4.2 全局优化的结束:$p_g=p_{data}$
-
-
-
- 命题1: 当G是确定的时候,最优的判别器是:
- 定理1: 当且仅当 $p_g=p_{data}$ 时,对抗游戏达到全局最小值,为 -log4 。
-
-
- 4.3 算法一的收敛性
-
-
-
- 命题2:如果G和D的容量足够大,且在算法一的每一轮迭代中,基于给定的生成器分布,判别器都能达到最优的判别,那么生成器最终会达到 $p_g=p_{data}$ 。
-
-
- 5 实验
- 6 评价
1 背景
深度学习通过学习复杂的数据分布来生成高层次的模型,在自然图像、语音识别和自然语言中都获得了很多的应用。
但是目前来说,较为成功的还是判别模型。
生成模型由于概率计算等困难,未获得较大的成功。
2 创新点
3 核心方法
训练一个生成器,将噪音引入到原始数据中,期待生成能使得判别器错误分类的样本。
同时训练一个判别器,尽力学习原始数据的分布,而不是被生成器扰乱的数据分布。
生成器类似于一个造价者,企图造出迷惑警察的假币;而判别器类似于警察,不能使得自己被假币迷惑。
通过两者不断地对抗,使得判别器和生成器都能达到很强大的性能。
具体来说:
- 通过把噪音 pz(z)p_z(z)pz?(z) 加入生成器 G(z;θg)G(z;\theta_g)G(z;θg?) 从原始数据分布中生成新的数据分布 pgp_gpg? 。
- 判别器 D(x)D(x)D(x) 尽力表征原始数据分布,而不是生成器生成的分布 pgp_gpg? 。
- 优化目标就是下式:
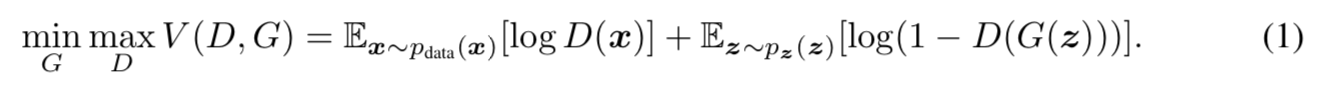
其计算的过程是先计算k步D,再计算一步G。
这样可以使得G缓慢改变,由此D就可以跟上步伐一直保持在最优解附近。
图解见下图:
- 蓝色为判别器的数据分布,黑色为原始数据的分布,绿色为生成器的分布。
- 蓝色的判别器每次去寻找到黑色的原始数据分布和绿色的生成器分布的最大区分界面,将它们分开。
- 绿色的生成器每次去逼近黑色的原始分布,以迷惑蓝色的判别器。
- 随着多次的迭代,绿色的生成器分布最终与黑色的原始数据分布重合,生成的样本再也无法被蓝色的判别器给区分开来。
- 迭代停止,此时的生成器已经具有很高的迷惑性。

4 理论推导
4.1 训练算法
其计算的过程如算法一所示:

即:
- 在判别器的每一轮迭代中,生成器采样一个minibatach的噪音和一个minibatch的样本数据,然后通过梯度下降来更新判别器的权重。
- 重复第一步k次。
- 在生成器的每一轮迭代中,采样一个minibatach的噪音,然后通过梯度下降更新生成器的权重。
- 不断重复1、2、3步,直到最大迭代次数或权重的更小已小于停止迭代的阈值。
4.2 全局优化的结束:pg=pdatap_g=p_{data}pg?=pdata?
命题1: 当G是确定的时候,最优的判别器是:
DG?(x)=pdata(x)pdata(x)+pg(x)D_G^*(x)=\frac{p_{data}(x)}{p_{data}(x)+p_g(x)}DG??(x)=pdata?(x)+pg?(x)pdata?(x)?
证明过程:

定理1: 当且仅当 pg=pdatap_g=p_{data}pg?=pdata? 时,对抗游戏达到全局最小值,为 -log4 。

4.3 算法一的收敛性
命题2:如果G和D的容量足够大,且在算法一的每一轮迭代中,基于给定的生成器分布,判别器都能达到最优的判别,那么生成器最终会达到 pg=pdatap_g=p_{data}pg?=pdata? 。
证明:

5 实验
在MNIST、多伦多人脸数据集和CIFAR-10上都做了实验。
生成器网络混合使用了ReLU和sigmoid激活函数,判别器使用了maxout激活函数。
判别器中还使用了dropout。
生成器网络的底层是特定的噪音,中间层使用了dropout和其他噪音。
使用 Guassian Parzen window 来生成pgp_gpg?,其参数由交叉验证确定。
结果如下:

下图是模型生成样本的可视化:


6 评价
缺点:
G不能频繁更新,需要保证D能跟上脚步。
优点:
不需要马尔科夫链和推断,只需要梯度下降。
未来的工作:
- 条件生成模型p(x|c)可以把条件c作为输入导入到G和D中。
- 通过训练一个附加的网络对给定的x来预测z可以实现 学习近似推理 。
- 可以训练一批共享参数的条件模型来近似被很多条件约束的模型。
- 可实现半监督学习。
- 通过对抗获得的G和D来提升原来的训练效率。