本博客整理自慕课网实战《基于Spark2.x的个性化推荐系统》
目录
- 一.推荐系统的生态介绍
-
- 1.生态概述
- 2.常见问题
- 3.效果评测
- 二.协同过滤推荐算法原理
-
- 1.基于用户的协同过滤
- 2.基于物品的协同过滤
- 3.基于模型的协同过滤
- 4.缺失值填充
- 三.ALS算法原理
一.推荐系统的生态介绍

1.生态概述
数据

算法
- 基于关联的推荐算法:如购买鞋子的顾客,会有10%的顾客会买袜子。有Apriori算法和FP-Growth算法。
- 基于内容的推荐算法:打标签(效率不高),文本相似度(TF-IDF算法),分类算法(KNN,决策树,朴素贝叶斯)。
- 基于协同过滤的推荐算法
- 基于用户的协同过滤:兴趣相近的用户会对同样的物品感兴趣。
- 基于物品的协同过滤:推荐给用户内容相似的物品。

- 基于模型的推荐算法:深度学习(属于机器学习的范畴)。
- 基于混合的推荐算法:将以上的各种推荐算法加权或者分层,用户能得到更全面的推荐。
领域知识

UI

2.常见问题
冷启动
- 用户冷启动(一个新用户怎么推荐?)
- 根据用户注册信息(邮箱类别,电话类别)
- 推荐热门的排行榜(比较常用)
- 基于深度学习语义分析(分析用户名来判断男女)
- 引导用户将自己的爱好表达出来(注册账号时让用户勾选自己的爱好)
- 利用用户在社交媒体的信息(QQ登录)
- 物品冷启动(一个新物品怎么推荐?)
- 文本分析(分析标题等文本信息)
- 主题模型(预先训练一个模型,然后对新物品进行分类处理)
- 给物品打标签(自己手动写)
- 推荐排行榜单
数据稀疏
主要在协同过滤算法中,兴趣相近的用户会对同样的物品感兴趣。会构建用户-物品矩阵,但这个矩阵是稀疏矩阵。
- 降维(奇异值分解)
- 对感兴趣的相似物品也感兴趣(数据填充)
- 基于深度学习的语义理解模型(基于物品本身的信息)
不断变化的用户喜好
- 对用户行为的存储有实时性
- 算法要考虑到近期行为和长期行为
- 不断挖掘用户的新爱好(扩大推荐结果多样性)
3.效果评测
模型离线实验
在训练集上训练和在测试集上预测,评测预测的效果。
预测准确度:RMSE,MAE
TopN推荐:个性化推荐列表,预测准确度:准确率 / 召回率。

覆盖率:是不是能够将所有物品都推荐给用户,而不是只推送热门的商品。
多样性,新颖性,惊喜度,信任度,实时性,健壮性。
A/B Test在线实验

用户调研
二.协同过滤推荐算法原理
1.基于用户的协同过滤
基于用户的协同过滤有以下几个缺点:
1. 如果用户量很大,计算量就很大
2. 用户-物品打分矩阵是一个非常非常非常稀疏的矩阵,会面临大量的null值
很难得到两个用户的相似性
3. 会将整个用户-物品打分矩阵都载入到内存,而往往这个用户-物品打分矩阵是一个非常大的矩阵
所以通常不太建议使用基于用户的协同过滤。
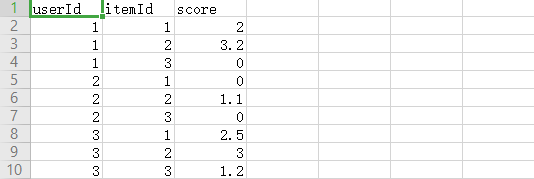
通过余弦相似度计算用户的相似度
余弦相似度的公式 : (A * B) / (|A| * |B|)
- |A|和|B|的求解(对于用户1和用户2):
22+3.22+022=3.77\sqrt[2]{2^2+3.2^2+0^2} = 3.77222+3.22+02?=3.77
02+1.12+022=1.1\sqrt[2]{0^2+1.1^2+0^2} = 1.1202+1.12+02?=1.1
val dfScoreMod = df.rdd.map(x=>(x(0).toString,x(2).toString)).groupByKey() //按照用户id进行分组.mapValues(score=>math.sqrt(score.toArray.map(itemScore=>math.pow(itemScore.toDouble,2)).reduce(_+_) // ((物品a的打分)**2 + (物品b的打分)**2 .. (物品n的打分)**2))** 1/2)).toDF("userId","mod")
- 不同用户对同一个物品的score情况表:
//这里目的是把两两用户都放到了同一张表里
val _df = df.join(_dfTmp,df("itemId") === _dfTmp("itemId")).where(df("userId") =!= _dfTmp("_userId")).select(df("itemId"),df("userId"),_dfTmp("_userId"),df("score"),_dfTmp("_score"))
- A * B的求解(用户1和2的维度乘积 ):
2×0+3.2×1.1+0×0=3.522\times 0 + 3.2\times1.1+0\times0 = 3.522×0+3.2×1.1+0×0=3.52
itemId userId _userId score _score
1 1 2 2 0
2 1 2 3.2 1.1
3 1 2 0 0// 两两向量的维度乘积并加总
import org.apache.spark.sql.functions._
val df_mol = _df.select(col("userId"),col("_userId"),(col("score") * col("_score")).as("score_mol") //用户a和用户b对各自对同一个物品打分的乘积
).groupBy(col("userId"),col("_userId"))
.agg(sum("score_mol")) //加总
.withColumnRenamed("sum(score_mol)","mol"
)
- 用户1和2的相似度:
3.52/(3.77×1.1)=0.843.52 / (3.77\times 1.1) = 0.843.52/(3.77×1.1)=0.84
// 分子 / 分母
val cos_sim = sim.select(col("userId"),col("_userId"),(col("mol") /(col("mod") * col("_mod"))).as("cos_sim")
)
2.基于物品的协同过滤
算法步骤:
-
计算用户物品打分矩阵

上方是原始表,通过将 itemId 这一列转成行,变成 用户-物品 的矩阵。 -
计算物品相似度矩阵(两个物品同时被买的次数越多,相似度越高)
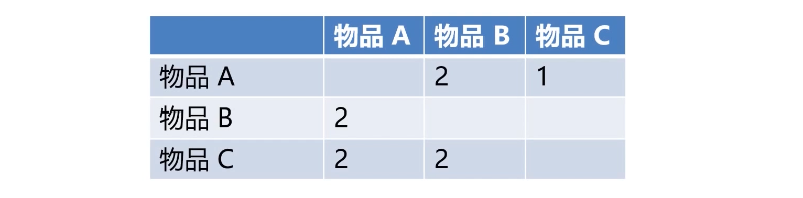
-
用户物品打分矩阵 * 物品相似度矩阵 = 推荐列表

原始表转化为 用户-物品 的矩阵:
val userItemTmp = userItemData.groupBy(col("userId")).pivot(col("itemId")).sum("vote")
物品相似度矩阵:
val rddTmp = userItemData.rdd.filter(x=>x.getFloat(2) > 0).map(x=>{
(x.getString(0),x.getString(1))})
3.基于模型的协同过滤
 SVD分解(分成3个矩阵):
SVD分解(分成3个矩阵):

U和V都是正交矩阵,中间的是奇异值的对角矩阵。
作用:
- 数据降维,解决数据稀疏(SVD的前提是基于稠密矩阵的,所以稀疏矩阵先进行缺值填充,再进行SVD分解)
- 减少特征空间,去除数据噪声。
PMF分解(分成2个矩阵):

4.缺失值填充
固定值,均值,中位数,众数填充。
import org.apache.spark.ml.feature.Imputerval imputer = new Imputer().setInputCols(Array("rating")).setOutputCols(Array("out_rating")).setMissingValue(Float.NaN).setStrategy("mean")
三.ALS算法原理
特征值分解只适用于方阵。
奇异值分解适用于其他矩阵,但是计算复杂度高。
ALS算法是PMF算法在数值计算方面的应用。

误差 = 观察的评分矩阵 - 预测的评分矩阵
问题就转化成了求最优解。
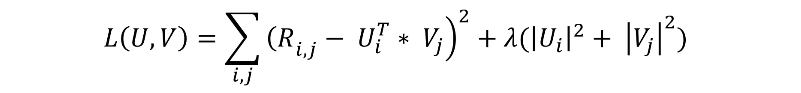
使误差最小,加入了正则项,避免过拟合。
在迭代过程中,交替优化U和V,最小交替二乘法。
ALS算法的缺点:
- 离线算法
- 不能解决冷启动