
目录
- 前言
- 一、框架总览
- 二、生成Ground Truth
- 三、网络结构
- 四、损失函数
- 五、平衡采样
- 六、利用关键点精炼(Refine with Landmark Localization)
- 七、论文实验
- Reference
前言
论文地址: https://arxiv.org/pdf/1509.04874.pdf.
PyTorch实现: https://github.com/CaptainEven/DenseBox.
论文贡献:
- 在FCN的基础上提出DenseBox直接检测目标,不依赖候选框。
- 在多任务学习过程中结合了关键点检测技术,进一步提高了目标检测的精度。
\qquad看这篇论文的初衷是因为从去年开始anchor free开始火热起来,并且这个方向似乎大有可为,不少大佬都在研究这个方向。在今年7月份旷世更是将anchor free引入到了YOLO,发表基于anchor free的YOLOX,所以想系统的学习下anchor free技术。今天先来讲一下CVPR 2015的DenseBox,算是Anchor free的思想起源,虽然已经过去6年了,但是这篇论文还是非常有创新点的。
一、框架总览
整体框架如下图所示:

- 首先一张原图经过图像金字塔(Image Pyramid)生成多个尺度的图片;
- 经过FCN(Fully Convolutional Networks)得到最终的输出feature map;
- 将输出feature map转为bounding box,再用NMS处理。
\qquad整体网络架构是一个FCN结构,也就是说这是一个end-to-end的one-stage结构(除了NMS),所以不需要第一步先生成region proposal。
二、生成Ground Truth
\qquad没有必要将整张图片送入网络进行训练,这样会造成不必要的计算资源消耗。一种有效的方式是对输入图片进行裁剪出包含人脸和丰富背景的 patches 进行训练。在训练阶段,将这些裁剪过后的 patches 进行 resize 到 240 x 240,其中人脸区域大约占 50 像素。最终输出feature map的维度为 60 x 60 x 5,下采样率为 4。5表示输出feature map的channel数,第一个channel为置信度,后四个channel为中心距bounding box四条边的距离(左上右下),所以每个像素都可以确定一个框。
\qquad正样本区域(positive labeled region)是一个以人脸框的中心为圆心且半径为 0.3 倍人脸框尺寸的原形区域。对于 patch 中存在多张人脸的情况,如果它们落在patch的中心一定范围内 (论文取0.8-1.25) 那么这些人脸就是正样本,其余的均为负样本。正样本第一个channel的像素值为1,负样本的第一个channel值为0。如下图所示:

\qquad利用我们标记的正样本区域可以得到我们的target值,再将预测得到的pred值与正样本target值做损失函数,就可以开始训练了。
三、网络结构
\qquad网络结构如下图所示,是基于 VGG19 进行改进,整个网络包含了 16 个卷积层,前面 12 层由 VGG 的预训练权重初始化,输出conv4_4后接了 4 个1×1 卷积,前面两个卷积产生通道数为1的分数score特征图,后面两个卷积产生4通道的位置预测特征图。

\qquad低层次特征关注目标的局部细节,而高层次的特征通过一个较大的感受野来对目标进行识别,感受野越大,语义信息越丰富,越有利于提高准确率。从上图可以看到,论文将 conv3_4和 conv4_4 做了concat处理。而conv3_4的感受野大小为 48 x 48,和本文的训练目标尺寸大小类似,而 conv4_4 的感受野大小为 118 x 118,可以有效的利用全局语义信息用于目标检测。同时conv4_4的特征图尺寸是conv3_4的一半,因此需要将其上采样到和conv3_4相同的分辨率再做融合。
四、损失函数
\qquad上面提到,网络的前12层用预训练的 VGG19 权重来初始化,其余卷积层用xavier初始化。 和 Faster-RCNN 类似,这个网络也有两个输出分支,第一个是输出目标类别分数 y^\hat{y}y^?,也即是输出特征图的第一个通道的每个像素值。真实标签 y?y^*y? = {0, 1},所以分类损失定义:
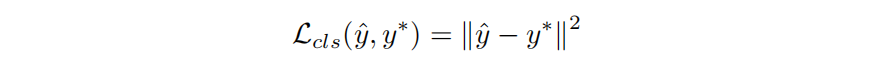
第二个损失是边界框回归损失,定义为最小化目标偏移(target)及预测偏移(predict)之间的 L2 损失:
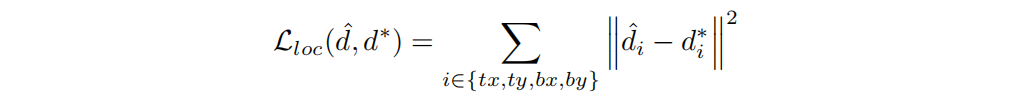
\qquad其中 d^=(d^tx,d^ty,d^tx,d^ty)\hat{d} = (\hat{d}_{tx},\hat{d}_{ty},\hat{d}_{tx},\hat{d}_{ty})d^=(d^tx?,d^ty?,d^tx?,d^ty?),d?=(dtx?,dty?,dtx?,dty?)d^* = (d^*_{tx},d^*_{ty},d^*_{tx},d^*_{ty})d?=(dtx??,dty??,dtx??,dty??),四个预测参数分别代表:左侧边距中心点的距离,上边据中心点的距离,右侧边距中心点的距离,下边距中心点的距离。
五、平衡采样
\qquad在训练过程中,负样本的挑选是很关键的。如果简单的把一个批次中所有的负样本都进行处理,会让模型更倾向于负样本。此外,检测器在处理正负样本边界上的样本时会出现模型 “坍塌”。论文提出使用一个二值mask图来决定像素是否为训练样本。注意!!!负样本指的是像素哦,不是指没有人脸的图片哦, 没有人脸的图片根本不会送到网络。
- 忽略灰度区域(Gray zone): 将正负区域之间区域定义为忽略区域,该区域的样本既不是正样本也不是负样本,其损失函数的权重为 0。在输出坐标空间中,对于每一个非正标记的像素,只要半径为2 的范围内出现任何一个带有正标记的像素,就将fign 设为1。
- Hard Negative Mining:通过寻找预测困难的样本来提高学习效率。具体方法为在训练过程的前向传播时,按照分类损失将像素降序排列,将top1% 定义为困难样本 (hard negtive)。在实验中,将positive和negative的比例设置在1:1。在negative samples中,一半来自于hard-negative,剩余的从非hard-negative中随机采样。为了方便,将被挑选的像素设置标记fsel=1。
- Loss with Mask:为每个样本ti^=(yi^,di^)\hat{t_i}=(\hat{y_i},\hat{d_i})ti?^?=(yi?^?,di?^?)(像素)定义mask值如下:
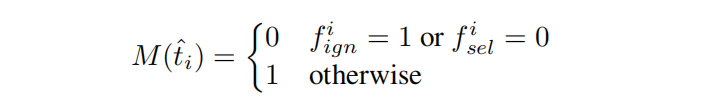
回归损失只对正样本起作用论文中还将目标框坐标 d?d^?d? 进行了归一化,即把坐标除以50/4,最后还对回归损失设置了一个惩罚系数λlocλ_{loc}λloc?=3.
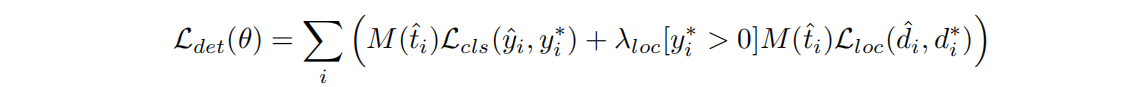
其他训练细节
\qquad将特定尺度图片中心处包含目标中心的输入patch称为 “postive patches”(因为目标中心是一个小圆,所以有包含这一说),这些patches在正样本的周围只包含负样本。论文将输入图片进行随机裁剪并resize到相同大小送入到网络中,这类patch叫 “random patches”,“positive patch” 与 “random patch” 的比例为1:1,另外,为了提升网络的鲁棒性,对每个patch进行了jitter操作,left-right flip,translation shift(25个像素),尺寸变形 ([0.8,1.25])。使用随机梯度下降算法进行训练,batch_size=10。初始学习率为0.001,每100K迭代,学习率衰减10倍。momentum设置为0.9,权重衰减为0.0005。
六、利用关键点精炼(Refine with Landmark Localization)
关键点技术我这里就写了,涉及到关键点检测的内容,感兴趣的可以自己阅读原论文。
七、论文实验




Reference
链接: link1.
链接: link2.
链接: link3.