Ŀ¼
- ǰ��
- 0��������Ҫ�İ�
- 1��gsutil_getsize
- 2��safe_download��attempt_download
-
- 2.1��safe_download
- 2.2��attempt_download
- 3��get_token��gdrive_download��ûʹ�ã�
-
- 3.1��get_token
- 3.2��gdrive_download
- 4������ע�͵ĺ���
- �ܽ�
ǰ��
Դ�룺 YOLOv5Դ��.
����: ��YOLOV5-5.x Դ�뽲�⡿������Ŀ�ļ�����.
ע�Ͱ�ȫ����Ŀ�ļ����ϴ���GitHub: yolov5-5.x-annotations.
����ļ���Ҫ�Ǹ����github/googleleaps/google drive ����վ�����Ʒ����������������һЩ�ļ�����һ�������࣬����Ƚϼ�����Ҳ�Ƚ��٣���Ҫ�ѵ㻹������һЩ�����ܴ�Ҳ��Ǻ���Ϥ������һ����ѧϰ�¡�
����ļ��Ƚ���Ҫ��������������safe_download��attempt_download����train.py����yolo.py���ļ��ж����õ���
0��������Ҫ�İ�
import os # �����ϵͳ���н�����ģ��
import platform # �ṩ��ȡ����ϵͳ�����Ϣ��ģ��
import subprocess # �ӽ��̶��弰������ģ��
import time
import urllib # ���ڲ�����ҳ URL��������ҳ�����ݽ���ץȡ���� ��urllib.parse: ����url
from pathlib import Path # Path��strת��ΪPath���� ʹ�ַ���·�����ڲ�����ģ��import requests # ͨ��urllib3ʵ���Զ�����HTTP/1.1����ĵ�����ģ��
import torch # pytorch���
1��gsutil_getsize
�������������������վ����url��Ӧ�ļ��Ĵ�С���õIJ��Ǻֻܶ࣬����google_utils.py��print_mutation�������� ����ij��url��Ӧ���ļ���С�磺

gsutil_getsize�������룺
def gsutil_getsize(url=''):"""����google_utils.py��print_mutation�������� ����ij��url��Ӧ���ļ���С���ڷ�����վ����url��Ӧ�ļ��Ĵ�Сgs://bucket/file size https://cloud.google.com/storage/docs/gsutil/commands/du"""# ����һ���ӽ�����������ִ�� gsutil du url ����(���� Cloud Storage) ����ִ�н��(�ļ�)s = subprocess.check_output(f'gsutil du {
url}', shell=True).decode('utf-8')# �����ļ���bytes��Сreturn eval(s.split(' ')[0]) if len(s) else 0
2��safe_download��attempt_download
������������Ҫ��������github����googleleaps�Ʒ������������ļ��ģ���Ҫ������Ȩ���ļ���attempt_download��������safe_download������
2.1��safe_download
����������������� url��github�� ���� url2��googleleaps�Ʒ������� ·����Ӧ����ҳ�ļ���ͨ��������Ȩ���ļ���������attempt_download�������磺
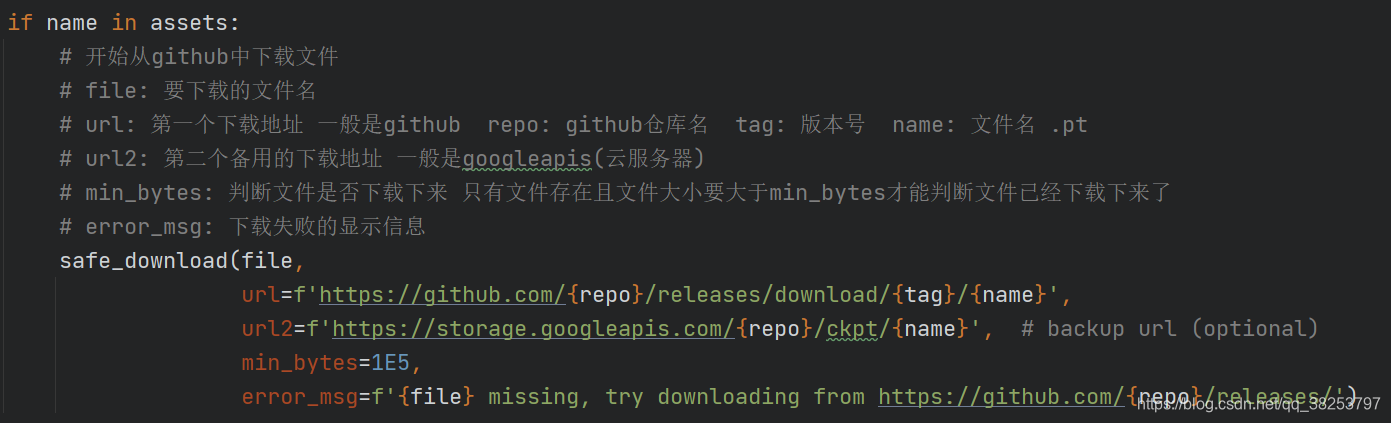
safe_download�������룺
def safe_download(file, url, url2=None, min_bytes=1E0, error_msg=''):"""����attempt_download���������� url/url2 ·����Ӧ����ҳ�ļ�Attempts to download file from url or url2, checks and removes incomplete downloads < min_bytes:params file: Ҫ���ص��ļ���:params url: ��һ�����ص�ַ һ����github:params url2: �ڶ������ص�ַ(��һ�����ص�ַ����ʧ�ܺ�ʹ��) һ����googleleaps���Ʒ�����:params min_bytes: �ж��ļ��Ƿ��������� ֻ���ļ��������ļ���СҪ����min_bytes�����ж��ļ��Ѿ�����������:params error_msg: �ļ�����ʧ�ܵ���ʾ��Ϣ ��ʼ��Ĭ�ϡ���"""file = Path(file)assert_msg = f"Downloaded file '{
file}' does not exist or size is < min_bytes={
min_bytes}"try: # ���Դ�url�������ļ� һ����githubprint(f'Downloading {
url} to {
file}...')# ��url�������ļ�torch.hub.download_url_to_file(url, str(file))# �ж��ļ��Ƿ�����������(�ļ��������ļ���СҪ����min_bytes)assert file.exists() and file.stat().st_size > min_bytes, assert_msg # checkexcept Exception as e: # ���оͳ��Դ�url2�������ļ� һ����googleleaps(�Ʒ�����)# �Ƴ�֮ǰ����ʧ�ܵ��ļ�file.unlink(missing_ok=True) # remove partial downloadsprint(f'ERROR: {
e}\nRe-attempting {
url2 or url} to {
file}...')os.system(f"curl -L '{
url2 or url}' -o '{
file}' --retry 3 -C -") # curl download, retry and resume on failfinally:# ����ļ��Ƿ�����������(�Ƿ����) �� �ļ���С�Ƿ�С��min_bytesif not file.exists() or file.stat().st_size < min_bytes: # check# ����ʧ�� �Ƴ�����ʧ�ܵ��ļ� remove partial downloadsfile.unlink(missing_ok=True)# ��ӡ������Ϣprint(f"ERROR: {
assert_msg}\n{
error_msg}")print('')
2.2��attempt_download
���������ʵ�ִӼ�����ƽ̨(github/googleleaps�Ʒ�����)�����ļ�(Ԥѵ��ģ��)������������ safe_download ������������experimental.py�е�attempt_load������train.py�У�������������Ԥѵ��Ȩ�� �磺
attempt_load������
train.py��
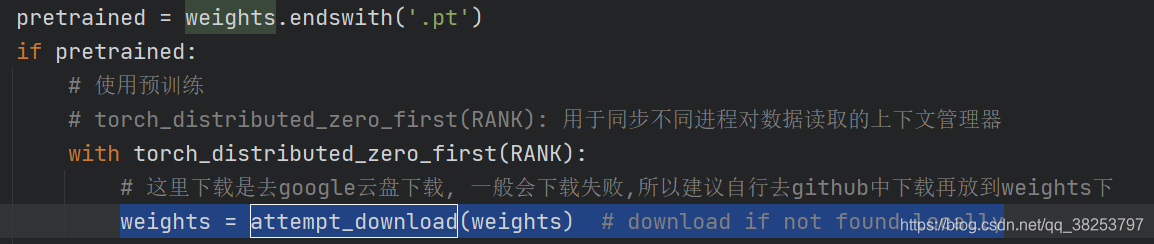
attempt_download�������룺
def attempt_download(file, repo='ultralytics/yolov5'):"""����experimental�е�attempt_load������train.py������Ԥѵ��Ȩ��ʵ�ִӼ�����ƽ̨(github/googleleaps�Ʒ�����)�����ļ�(Ԥѵ��ģ��):params file: ������ļ�·�� �����·���������ļ��ͳ��������ļ�����url��ַ ��ֱ�������ļ����ֻ��һ��Ҫ���ص��ļ���, �Ǿͻ�ȡ�汾�ſ�ʼ����(github/googleleaps):params repo: �����ļ���github�ֿ��� Ĭ����'ultralytics/yolov5'"""# .strip()ɾ���ַ���ǰ��ո� /n /t�� .replace�� ' �滻Ϊ�ո� Path��strת��ΪPath����file = Path(str(file).strip().replace("'", ''))# �������ļ�·���������ļ� �ͳ�������if not file.exists():# urllib.parse: ����url .unquote: ��url���н��� decode '%2F' to '/' etc.name = Path(urllib.parse.unquote(str(file))).name# ����������ļ�����http:/ �� https:/ ��ͷ��ֱ������if str(file).startswith(('http:/', 'https:/')): # download# url: ����·�� urlurl = str(file).replace(':/', '://') # Pathlib turns :// -> :/# name: Ҫ���ص��ļ���name = name.split('?')[0] # parse authentication https://url.com/file.txt?auth...# �����ļ�safe_download(file=name, url=url, min_bytes=1E5)return name# GitHub assetsfile.parent.mkdir(parents=True, exist_ok=True) # make parent dir (if required)try:# ����github api ��ȡ���µİ汾�����Ϣ �����response��һ�����ֵ�response = requests.get(f'https://api.github.com/repos/{
repo}/releases/latest').json() # github api# response['assets']�а�������ֵ���б� ���м�¼ÿһ��asset�������Ϣ# release assets, i.e. ['yolov5s.pt', 'yolov5m.pt', ...]assets = [x['name'] for x in response['assets']]# tag: ��ǰ���°汾�� ��'v5.0'tag = response['tag_name']except: # ��ȡʧ�� ���˶������ ֱ������git����ǿ�в���汾��Ϣassets = ['yolov5s.pt', 'yolov5m.pt', 'yolov5l.pt', 'yolov5x.pt','yolov5s6.pt', 'yolov5m6.pt', 'yolov5l6.pt', 'yolov5x6.pt']try:# ����һ���ӽ�����������ִ�� git tag ����(���ذ汾�� �汾����Ϣһ�����ֵ���� -1) ����ִ�н��(�汾��tag)tag = subprocess.check_output('git tag', shell=True, stderr=subprocess.STDOUT).decode().split()[-1]except:# �������ʧ�� ��ǿ���Լ���һ���汾�� tag='v5.0'tag = 'v5.0' # current releaseif name in assets:# ��ʼ��github�������ļ�# file: Ҫ���ص��ļ���# url: ��һ�����ص�ַ һ����github repo: github�ֿ��� tag: �汾�� name: �ļ��� .pt# url2: �ڶ������õ����ص�ַ һ����googleapis(�Ʒ�����)# min_bytes: �ж��ļ��Ƿ��������� ֻ���ļ��������ļ���СҪ����min_bytes�����ж��ļ��Ѿ�����������# error_msg: ����ʧ�ܵ���ʾ��Ϣsafe_download(file,url=f'https://github.com/{
repo}/releases/download/{
tag}/{
name}',url2=f'https://storage.googleapis.com/{
repo}/ckpt/{
name}', # backup url (optional)min_bytes=1E5,error_msg=f'{
file} missing, try downloading from https://github.com/{
repo}/releases/')return str(file)
3��get_token��gdrive_download��ûʹ�ã�
������������ʵ�ִ�google drive������ѹ���ļ��������ѹ, ��ɾ����ѹ���ļ������������û���ڴ�����ʹ�ã�����������������������˽��¾ͺã���Ҫ����Ҫ����������������غ����õıȽ϶ࡣ
3.1��get_token
�������ʵ�ִ�cookie�л�ȡ����token������gdrive_download�б����á�
get_token�������룺
def get_token(cookie="./cookie"):"""��gdrive_download��ʹ��ʵ�ִ�cookie�л�ȡ����token """with open(cookie) as f:for line in f:if "download" in line:return line.split()[-1]return ""
3.2��gdrive_download
�������ʵ�ִ�google drive������ѹ���ļ��������ѹ, ��ɾ����ѹ���ļ����������ò��û�õ�����㿴�¾ͺá�
gdrive_download�������룺
def gdrive_download(id='16TiPfZj7htmTyhntwcZyEEAejOUxuT6m', file='tmp.zip'):"""ʵ�ִ�google drive������ѹ���ļ��������ѹ, ��ɾ����ѹ���ļ�:params id: url ?�����id�����IJ���ֵ:params file: ��Ҫ���ص�ѹ���ļ���"""t = time.time() # ��ȡ��ǰʱ��file = Path(file) # Path��strת��ΪPath����cookie = Path('cookie') # gdrive cookieprint(f'Downloading https://drive.google.com/uc?export=download&id={
id} as {
file}... ', end='')file.unlink(missing_ok=True) # �Ƴ��Ѿ����ڵ��ļ�(����������ʧ��/���ز���ȫ)cookie.unlink(missing_ok=True) # �Ƴ��Ѿ����ڵ�cookie# ��������ѹ���ļ�out = "NUL" if platform.system() == "Windows" else "/dev/null"# ʹ��cmd�����google drive�������ļ�os.system(f'curl -c ./cookie -s -L "drive.google.com/uc?export=download&id={
id}" > {
out}')if os.path.exists('cookie'):# ����ļ��ϴ� ����Ҫ������get_token(����cookie��������)��ָ��s��������# get_token()���������涨���� ���ڻ�ȡ��ǰcookie������tokens = f'curl -Lb ./cookie "drive.google.com/uc?export=download&confirm={
get_token()}&id={
id}" -o {
file}'else:# С�ļ��Ͳ���Ҫ�����Ƶ�ָ��s ֱ�����ؾ���s = f'curl -s -L -o {
file} "drive.google.com/uc?export=download&id={
id}"'# ִ������ָ��s ����÷��� ���cmd����ִ�гɹ� ��os.system()����᷵��0r = os.system(s)cookie.unlink(missing_ok=True) # �ٴ��Ƴ��Ѿ����ڵ�cookie# ���ش����� ���r != 0 �����ش���if r != 0:file.unlink(missing_ok=True) # ���ش��� �Ƴ����ص��ļ�(���ܲ���ȫ��������ʧ��)print('Download error ') # raise Exception('Download error')return r# �����ѹ���ļ� �ͽ�ѹ file.suffix�������Ի�ȡfile�ļ��ĺ�if file.suffix == '.zip':print('unzipping... ', end='')os.system(f'unzip -q {
file}') # cmd����ִ�н�ѹ����file.unlink() # �Ƴ�.zipѹ���ļ�print(f'Done ({
time.time() - t:.1f}s)') # ��ӡ���� + ��ѹ��������Ҫ��ʱ��return r
4������ע�͵ĺ���
�������������ע�͵ĺ��������Ӳ���Ҫ�ˣ����Բ�����
# --------------------------------------- ������������ûʲô�� ���Բ��� ---------------------------------------------------
# def upload_blob(bucket_name, source_file_name, destination_blob_name):
# # Uploads a file to a bucket
# # https://cloud.google.com/storage/docs/uploading-objects#storage-upload-object-python
#
# storage_client = storage.Client()
# bucket = storage_client.get_bucket(bucket_name)
# blob = bucket.blob(destination_blob_name)
#
# blob.upload_from_filename(source_file_name)
#
# print('File {} uploaded to {}.'.format(
# source_file_name,
# destination_blob_name))
#
#
# def download_blob(bucket_name, source_blob_name, destination_file_name):
# # Uploads a blob from a bucket
# storage_client = storage.Client()
# bucket = storage_client.get_bucket(bucket_name)
# blob = bucket.blob(source_blob_name)
#
# blob.download_to_filename(destination_file_name)
#
# print('Blob {} downloaded to {}.'.format(
# source_blob_name,
# destination_file_name))
�ܽ�
����ļ��Ĵ���Ƚ��٣��������õĺ���Ҳ�Ƚ��٣�Ҳ����safe_download��attempt_download���������Ƚ���Ҫ������ص������������������ɡ�
�C2021.07.31 13��06