Implement strStr() ЃК https://leetcode.com/problems/implement-strstr/
Returns the index of the first occurrence of needle in haystack, or -1 if needle is not part of haystack.
ШчЃКhaystack = ЁАbcbcdaЁБ; needle = ЁАbcdЁБ дђ return 2
НтЮіЃКзжЗћДЎВщевКЏЪ§ЃЌstrstr()КЏЪ§гУРДМьЫїзгДЎдкзжЗћДЎжаЪзДЮГіЯжЕФЮЛжУЃЌЦфдаЭЮЊЃК
char *strstr( char *str, char * substr );
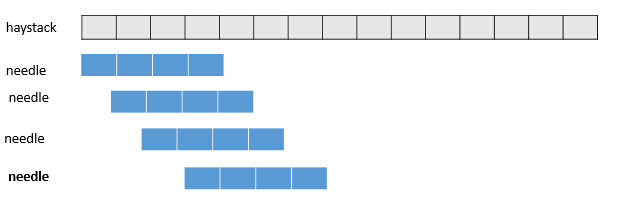
ЫМТЗвЛЃКШнвзЪЕЯжЃЌШЛВЂТбЃЈЪБМфИДдгЖШВЛТњзувЊЧѓЃЉ
СНИіжИеыЃЌi жИЯђhaystack ЕФЦ№ЪМЃЌj жИЯђ needle ЕФЦ№ЪМЃЛЪзЯШ i ЯђКѓзпЃЌжБжСhaystack[i] == needle [j]; ШЛКѓ j ЭљКѓзпЃЌШчЙћhaystack[i+j] != needle [j] ЬјГіЃЌШчЙћФмзп m ВНЃЌМДДцдкЯрЭЌ,ЗЕЛиiЃЛШчЙћДцдкВЛЦЅХфЃЌдђhaystack КѓвЦКѓЃЌДгneedle[0]жиаТБШНЯ
дРэОЭЪЧЃКФУзХ needle зжЗћДЎ ШЅ haystack ЩЯж№ИіБШНЯЃЛУПДЮзюЖрашвЊЖдБШmДЮЃЌзюЖржиИДnДЮЃЛ
ЙЪЪБМфИДдгЖШЮЊO(m*n),ВЛФмТњзуleetcodeЕФЪБМфвЊЧѓ
зЂЃКдкаДДњТыЧАРэЧхЫМТЗЃЌ
1. ШЗЖЈНтОіЮЪЬтЕФЫуЗЈ
2. ШЗЖЈЫуЗЈЕФЪБПеИДдгЖШЃЌПМТЧФмВЛФмгХЛЏЛђбЏЮЪУцЪдЙйЪЧЗёвЊЧѓЪБПеИДдгЖШЁЃ
3. гаФФаЉЬиЪтЧщПіашвЊДІРэ
БиаыБиаыБиаыЯШЧхЮњЫМТЗЃЌдйаДДњТыЁЃ
int strStr2(string haystack, string needle) {// ЪБМфИДдгЖШO(m*n),ВЛФмТњзуleetcodeЕФЪБМфвЊЧѓint m = needle.size();int n = haystack.size();if (m == 0) return 0;if (m > n) return -1;for (int i = 0; i < n; i++) {int j = 0;if (haystack[i] == needle[j]) {for (; j < m && i+j < n; j++) {if (needle[j] != haystack[i+j])break;}if (j == m)return i;}}return -1;}ЫМТЗЖў RabinЈCKarp algorithmЫуЗЈ - Hash Вщев
RabinЈCKarp algorithmЫуЗЈЃКЪЧМЦЫуЛњПЦбЇжаЭЈЙ§ hash ЕФЗНЗЈгУгкдквЛИіДѓСПЮФБОжаВщеввЛИіЙЬЖЈГЄЖШЕФзжЗћДЎЕФЫуЗЈЁЃЃЈФЃЪНВщевЃЉ
ДгЫМТЗвЛЮвУЧПЩжЊЃЌвЊЯыШЗЖЈhaystackжаДцдкneedleЃЌБиаыЭъШЋБШНЯneedleЕФЫљгазжЗћЁЃФЧУДгаУЛгаФмЙЛРћгУЩЯвЛДЮБШНЯЕФНсЙћЃЌНіЬэМгO(1)ЕФЪБМфЁЃ
ЛљБОЫМЯыЪЧЃКгУвЛИіhash code БэЪОвЛИізжЗћДЎЃЌЮЊСЫБЃжЄ hash ЕФЮЈвЛадЃЌЮвУЧгУБШзжЗћМЏДѓЕФЫиЪ§ЮЊЕзЃЌвдетИіЫиЪ§ЕФУнЮЊЛљЁЃ
Р§ШчЃКаЁаДзжФИМЏЃЌбЁдёЫиЪ§29ЮЊЕзЃЌШчзжЗћДЎЁБabcdЁБЕФhash codeЮЊ
ФЧУДЯТвЛВНМЦЫузжЗћДЎЁБbcdeЁБЕФ hash code ЮЊ
<зЂ>Р§згжаЪЧе§ађМЦЫуЕФhash codeЃЌвдЯТГЬађжаЪЙгУЪЧЕЙађМЦЫуЕФ hash code, МД
hash("abcd")=4?290+3?291+2?292+1?293 ,РрЫЦгкНјжЦзЊЛЛ
hash("bcde")=(hash("abcd")?1?293)?29+5
int charToInt(char c) {return (int)(c-'a'+1);}// ЪБМфИДдгЖШ O(m+(n-m)) = O(n)int strStr(string haystack, string needle) {int m = needle.size();int n = haystack.size();if (m == 0) return 0;if (m > n) return -1;const int base = 29;long long max_base = 1;long long needle_code = 0;long long haystack_code = 0;for (int j = m - 1; j >= 0; j--) {needle_code += charToInt(needle[j])*max_base;haystack_code += charToInt(haystack[j])*max_base;max_base *= base;}max_base /= base; // згДЎЕФзюДѓЛљif (haystack_code == needle_code)return 0;for (int i = m; i < n; i++) {haystack_code = (haystack_code - charToInt(haystack[i-m]) * max_base) * base + charToInt(haystack[i]);if (haystack_code == needle_code)return i - m + 1;}return -1;}ДцдкЕФШБЕуЪЧЃЌЫиЪ§ЕФУнПЩФмЛсКмДѓЃЌвђДЫМЦЫуНсЙћвЊЪЙгУ long long ЕФРраЭ ЃЌЩѕжСвЊЧѓИќДѓЕФbig intЃЛСэЭтЃЌПЩвдЭЈЙ§ШЁгрЕФЗНЪНЫѕаЁЃЌЕЋЪЧгааЁИХТЪЮѓХаЁЃ
ЫуЗЈВЮПМЃКhttp://blog.csdn.net/linhuanmars/article/details/20276833
ИќЖрЫМТЗ
KMPзжЗћДЎЫбЫїЫуЗЈЃК
http://www.ruanyifeng.com/blog/2013/05/Knuth%E2%80%93Morris%E2%80%93Pratt_algorithm.html
https://en.wikipedia.org/wiki/Knuth%E2%80%93Morris%E2%80%93Pratt_algorithm
Boyer-MooreзжЗћДЎЫбЫїЫуЗЈ
http://www.ruanyifeng.com/blog/2013/05/boyer-moore_string_search_algorithm.html
https://zh.wikipedia.org/wiki/Boyer-Moore%E5%AD%97%E7%AC%A6%E4%B8%B2%E6%90%9C%E7%B4%A2%E7%AE%97%E6%B3%95