ФПТМ
- ШыУХЦЊЃКЭМЯёЩюЖШЙРМЦЯрЙизмНс
- гІгУЦЊЃКLearning to be a Depth Camera
- ГпЖШЦЊЃКMake3D
- ЧЈвЦЦЊЃКDepth Extraction from Video Using Non-parametric Sampling
- ЩюЖШЦЊЃКDavid Eigen
- ЮоМрЖНЦЊЃКLeft-Right Consistency & Ego Motion
- ЯрЖдЩюЖШЦЊЃКDepth in the Wild & Size to Depth
- SLAMИЈжњЦЊЃКMegaDepth
- ЗНЗЈБШНЯЦЊЃКEvaluation of CNN-based Methods
ЕЅФПЭМЯёЩюЖШЙРМЦ - ЮоМрЖНЦЊЃКLeft-Right Consistency & Ego Motion
НќМИФъгаЙиЕЅФПЭМЯёЩюЖШЪЖБ№ЕФЫуЗЈвдCNNЮЊжїСїЃЌИќЯИЕФЫЕЪЧвдЮоМрЖНЕФЭЌЪБЖдЩюЖШЁЂМЦЫуЛњНЧЖШЁЂЙтСїЕШЭЌЪБМЦЫуЕФЖЫЕНЖЫЩюЖШЭјТчЮЊжїСїЁЃ
ЫљЮНЮоМрЖНЦфЪЕЪЧжИдкбЕСЗЙ§ГЬжаВЛашвЊЪфШыецЪЕЕФЩюЖШжЕЃЌетбљзігавЛИіКУДІОЭЪЧФПЧАФмЙЛВтСПЕНЩюЖШаХЯЂЕФДЋИаЦїЛЙВЛЙЛОЋШЗЃЌвђДЫгЩВЛЙЛОЋШЗЕФlabelбЕСЗГіЕФmodelЕУЕНЕФдЄВтНсЙћБиШЛВЛЛсЬиБ№СюШЫТњвтЃЛ
ЫљЮНЭЌЪБМЦЫуФиЃЌдкЮвРэНтЪЧжИдкбЕСЗЙ§ГЬжаЃЌгУвЛИіФмЙЛБэеїЪБМфађСаЩЯгаЧАКѓЙиЯЕЕФжЁжЎМфЕФВюБ№ЕФlossЭЌЪБбЕСЗЖрИіЭјТчЃЌЖјдкЕУЕНmodelКѓУПИіЭјТчПЩвдЕЅЖРЪЙгУЁЃ
КмДЯУїЃЌВЛЭЌзїгУЕФЭјТчЯрЕБгкШЫЮЊЕФЬиеїЬсШЁЙ§ГЬЃЌзюКѓЕФдЄВтЛљгкетИіШЫЮЊЕФЬиеїЬсШЁНсЙћЃЌЕЋетжжЗНЗЈвВгаЦфШБЕуЃЌЮвФмЯыЕНЕФОЭЪЧВЮЪ§ЕФдіМгЃЌЭјТчНсЙЙЕФИДдгЛЏКЭШЫЮЊЬиеїЖдзюжедЄВтНсЙћгаУЛгаЦ№в§ЕМзїгУжЛФмгУЪЕбщШЅжЄУїЁЃ
ЯъЯИЫЕФиЃЌЪзЯШЃЌЫљЮНЕФЁАЮоМрЖНЁБЫфШЛВЛашвЊЪфШыецЪЕЩюЖШаХЯЂЃЌЕЋашвЊЪфШыЫЋФПЩуЯёЭЗЛёШЁЕНЕФЭЌвЛЪБПЬВЛЭЌНЧЖШЕФЭМЯёЛђепЧАКѓжЁЭМЯёЃЌжЛЪЧетбљОЭНазіЮоМрЖНдкЮвПДРДТдЯдЧЃЧПЁЃ
ЦфДЮЃЌЙигкЖрЭјТчЙВЭЌбЕСЗЃЌБОРДЩюЖШЭјТчОЭКмФбНтЪЭЃЌИДдгЛЏЭјТчЕФНсЙЙЕУЕНЖрИіПДЫЦПЩвдНтЪЭЕФзгЭјТчЃЌЪЧЗёКЭЩюЖШЭјТчЕФЖЫЕНЖЫКкКаЬиадгаЫљГхЭЛЃПНЯжиЕФШЫЮЊИЩЩцЪЧВЛЪЧЗДЖјгАЯьЩюЖШЭјТчЖдЪ§ОнвўКЌжЊЪЖЕФРэНтКЭГщШЁЃП
вдЩЯжЛЪЧЮвИіШЫЕФвЛаЉЫМПМЃЌЯЃЭћдкЮДРДЕФбЇЯАЙ§ГЬжаФмЕУЕНвЛаЉД№АИЁЃ
1. UnSupervised Learning of Depth and Ego-Motion from VideoЃЌCVPRЃЌ2017
НгЯТРДаДвЛЯТGoogleЗЂБэгкCVPR2017ЕФетЦЊЮФеТЃЌДгЬтФППЩвдПДГіетЦЊЮФеТЬсГіСЫвЛжжЗЧМрЖНЕФЖрЙІФмЭјТчЃЌжївЊЫМЯыОЭЯёжЎЧАЬсЕНЙ§ЕФгУвЛИіlossЭЌЪБбЕСЗСНИіЭјТчЁЃЭјТчЕФНсЙћШчFig.2,ЦфжаЕквЛИіЭјТчПЩНгЪмвЛЗљЭМЦЌзїЮЊЪфШыЃЌЪфГіЦфЖдгІЕФЩюЖШЭМЦЌЃЛЕкЖўИіЭјТчЮЊзЫЬЌЭјТчЃЌНгЪмtЃЌt+1КЭt-1Ш§ИіЪБПЬШ§ЗљЭМЦЌзїЮЊЪфШыЃЌЪфГіДгtЕНt+1КЭДгtЕНt-1ЕФЯрЛњзЫЬЌБфЛЏОиеѓЁЃ
ЙигкPoseЕФВПЗжЮвВЛКмСЫНтЃЌЫљвджївЊЫЕУївЛЯТDepth CNNЭјТчКЭLossЕФНсЙЙЁЃ
Depth CNN

ЛљБОНсЙЙМћЩЯЭМЃЌЪфШыЮЊЧАжаКѓШ§жЁСЌајЕФЭМЦЌЃЌЭЌЪБбЕСЗСНИіЭјТчЃЌвЛИіЕУЕНЩюЖШдЄВтНсЙћЃЌвЛИіЕУЕНЪгВюОиеѓНсЙћЁЃ

ЦфжаЪгВюЭјТчгУЕНСЫЩюЖШдЄВтЭјТчЕФдЄВтНсЙћЁЃгІгУНсЙЙгыDisNetЯрЭЌЕФЭјТчзїЮЊЩюЖШЙРМЦЕФЭјТчЃЌDispNetгЕгажїСїЕФencoder-decoderНсЙЙЃЌЯТвЛВНДђЫуПДвЛЯТDispNetЕФЯрЙиPaperЃЌвђДЫдкетВЛЖрНщЩмЁЃзїепЬсЕНЪЙгУЖрЪгНЧЕФЭМЦЌбЕСЗЩюЖШдЄВтЭјТчНсЙћКЭЕЅеХЭМЦЌаЇЙћУЛгаКмДѓВювьЃЌЫЕУїЙтСїдМЪјашвЊдкЖдЖрЪгНЧЭМЦЌНјаагааЇРћгУЕФЧАЬсЯТЪЙгУЁЃ
Loss
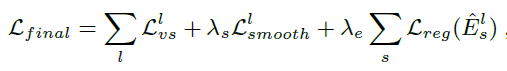
гЩEq.4ПЩМћЃЌLossЗжЮЊШ§ИіВПЗжЁЃЦфжаЕквЛВПЗжЮЊsampleКЭtargetЕФВюБ№ЃЌЕкЖўВПЗжЮЊЖрГпЖШЦНЛЌВЮЪ§ЃЌЕкШ§ВПЕФФПЕФЪЧЮЊСЫБмУтEsЧїгк0ЁЃ
2. UnSupervised Monocular Depth Estimation with Left-Right Consistency, CVPR, 2017
етЦЊPaperжївЊЫМЯыЮЊЪЙгУЫЋФПЩуЯёЭЗЕУЕНЕФЭЌвЛЪБПЬЕФСНЗљЭМЦЌ(leftЃЌright)НјаабЕСЗЃЌЕУЕНгЩleftЩњГЩrightЃЈЛђrightЩњГЩleftЃЉЕФЭјТчЃЌШЛКѓИљОнЩњГЩЕФЫЋФПЭМЦЌЕУЕНdepthЁЃФЧЫљЮНЕФЮоМрЖНЪЧжИВЛашвЊground truth depthЃЌжЛашвЊЫЋФПЭМЦЌЁЃетжжЗНЗЈЕФКУДІЪЧБмУтСЫЩюЖШВтСПгВМўБОЩэЕФЮѓВюЃЌзїепЬсГіЯжгаЕФЩюЖШВтСПгВМўБШШчРзДяЁЂКьЭтЯрЛњЁЂTOFЯрЛњЕШБОЩэОЭгаЮѓВюЃЌЖјЧвОпгагааЇЗЖЮЇЕФЯожЦЃЌЖдБШПДРДЩуЯёЭЗЛђЫЋФПЩуЯёЭЗгВМўММЪѕИќЮЊГЩЪьЃЌЮѓВювВЛсИќаЁЃЌвђДЫдкДЫЛљДЁЩЯбЕСЗГіРДЕФЭјТчгІИУгаИќКУЕФОЋЖШЁЃ
ФПЧАвВгаРрЫЦЕФгЩзѓЭМЩњГЩгвЭМЕФЗНЗЈЃЌЕЋБОЮЛЗНЗЈЕФИФНјОЭдкгкЬсГіСЫвЛжжleft-right consistencyЃЌдкбЕСЗЙ§ГЬжаВЛНіЯожЦгЩзѓЭМЕНгвЭМЕФСЌајадЃЌЭЌЪБвВЯожЦгвЭМЕНзѓЭМЕФСЌајадЁЃ
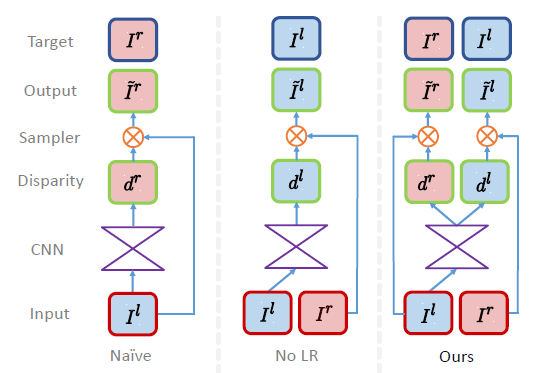
ЩЯЭМЮЊМИжжЗНЗЈЕФБШНЯЃЌПЩвдПДГіNaiveЗНЗЈЕФЪфГіжЛЪмtargetгАЯьЃЌЖјNoLRЗНЗЈЕФЪфГіЪмзѓгвЭМЭЌЪБЕФгАЯьЃЌБОЮФЗНЗЈдђдкNoLRЕФЛљДЁЩЯдіМгСЫзѓгвСЌајадЯожЦЁЃ

ЩЯЭМЮЊЮФеТЕФжївЊДДаТЕуЃКзѓгввЛжТадLossЁЃетИіLossПЩвдЭЌЪБПМТЧЕНзѓгвЪгВювЛжТадЁЂЦНЛЌадЁЂжиНЈаЇЙћЁЃ

LossЙЋЪНБэЪОШчЩЯЭМЃЌПЩМћLossЗжЮЊШ§ВПЗжЃК
- ЕквЛВПЗжЮЊгыinputЕФЯрЫЦад
- ЕкЖўВПЗжЮЊЦНЛЌаддМЪј
- ЕкШ§ВПЗжЮЊзѓгввЛжТаддМЪј
CNNЭјТчЕФНсЙЙвЙЪгЛљгкDispNetдкДЫВЛдйЫЕУїЁЃ
3. змНс
етСНЦЊЮФеТЖМЪЧЛљгкЮоМрЖНЕФЗНЗЈЃЌЕЋЫЕЪЧЮоМрЖНгжгаЕуЧЃЧПЃЌЕЋЮвШЯЮЊЮоТлдкФЧИібаОПСьгђЃЌЮоМрЖНЖМЪЧзюжеЕФФПБъЃЌБЯОЙlabelзмгаВЛПЩППЕФИХТЪЃЌздЮвбЇЯАКЭОРе§ФмСІВХЪЧШЫЙЄжЧФмОпгажЧФмЕФеце§БъжОЁЃ
СНжжЗНЗЈЖМгУЕНСЫDispNetЃЌЪЧВЛЪЧПЩвдЫЕУїЯжгаЕФCNNФЃаЭНсЙЙЭъШЋПЩвдЪЄШЮДѓВПЗжМЦЫуЛњЪгОѕШЮЮёФиЃП
КмЖрCVЯрЙиЕФPaperжаЕФЭјТчНсЙЙзмНсЦ№РДгавдЯТМИжжЧщПіЃК
- ЪЙгУвбгаЭјТчбЕСЗКУЕФВЮЪ§ГѕЪМЛЏ
- ЪЙгУвбгаЭјТчЕФНсЙЙ
- ЪЙгУвбгаЭјТчжаЕФвЛВПЗж
ЦфжавбгаЭјТчжИVGG,ResNet,DispNet,LeNetЕШЕШЁЃ