PatchScope: Memory Object Centric Patch Diffing
����
����Ŀ����Ϊ�˶�λ������ͨ���ḻ���������ΪʲôҪ���Ӳ��������������ĸ�Դ�����ⲹ��ϸ�ڡ�
�����
���������ּ��� [27, 34, 49]
[7, 25, 29] �þ�̬����������ͼ����̬��Ϊ��ϵͳ����[5, 64]
[16, 18, 21, 22, 71]�� �������ּ�����©����ⷽ���Ӧ��
[40, 60, 64] ������Ϯ�����Ӧ�á�
[5, 12, 44, 70]�������������������Ƚ�
��������
���������������ⲹ��ϸ��
���м�����̬
APEG [8]��ʶ��һ����ȫ������Ӧ�Ĵ����Ƿ��漰��ȫ�Լ�졣����λ���в��������йذ�ȫ�IJ���������
SPAIN [72] ʶ��ȫ��������һ�����裺��ȫ��������ı�������⣬ͨ������һ���µķ�֧�������Ч�����⡣
SID [68] ͨ���ܽ�ͨ������©���IJ�����ģʽ�ܽ���ȷ����ȫ©����Ӱ��
���м�����̬
execution comparison techniques [53, 75] ��ִ�бȽϼ�����
���ڹ۲쵽��crash�������Ƭ��differential slicing [30, 67]��Ϊ������������ؿ��ƺ���������
PatchScope����
��̬�������ּ���PatchScope����Եͼ��Ķ�����ָ��������������Ϊ���зḻ����ĸ������Դٽ���©����Դ�Ͳ���ϸ�ڵ��о���
�����ƶ�����Ҫ���������棺1.����������ķ�ʽ��¶���м�ֵ��������Ϣ��2.�ܶలȫ�����������ڴ��ƻ�©��ּ�ڸ��õĵ�����������Ĵ����������߶�ȫ�������Ӱ������Ŀ����ǣ���ͨ��������������ݽṹ
���ַ�ʽΪ ����һ��POCͨ���Ƚϴ���δ����������ִ�е��ڴ����������ʶ�����졣
ʶ��ϸ�ڣ���̬���ھ��ڳ���ִ�й����л����ڴ����ģʽ���漰�����ڴ���� ͨ�����ǩ��Ⱦ��������һ��ʶ��������Ӧ�ڴ������ص������ֶΡ�Ȼ�������ڴ����ģ������ʾ�������ֶεIJ�����ͨ�����ַ�ʽ��������ִ̬���������Ϊ�ڴ������������������������Ϣѧ���ֲ����жԱ��㷨��ʶ��patch�IJ�ͬ
���ߵĹ���
- ��ȫ�����Ĵ��ģ�о����µļ��⣺ͨ����鲹��Դ����ĸ��Ľ�������Ϊ����
- ���ڴ����Ϊ���ĵļ���Ϊ�������֣�������µĽǶ���ʶ����ͬ�����ͨ����Ӧ�����ݽṹ��������
- ������PatchScope�ڲ��������и���Ч
����Ͷ���
Ҫ���������
����ͬpoc�ıȽϵõ���ִ��·���õ�
- 1.�����������
- 2.�÷ḻ�����������ʶ��IJ���ȥ���ⲹ���Լ�����©��
������POC���ã��о���Ҫ����Ϊ��̬�IJ������֣���ô�õ�POC�����о�����
��ȫ����ģʽ
���˶Բ����������о�[37, 41, 46, 65, 68] �ṩ�˲������ݿ⡣ [72] ��������
[45, 66]������ƪ���¶����˲���ģʽ�����߶�������иĽ�
[8, 50] 1day exp���ɼ���
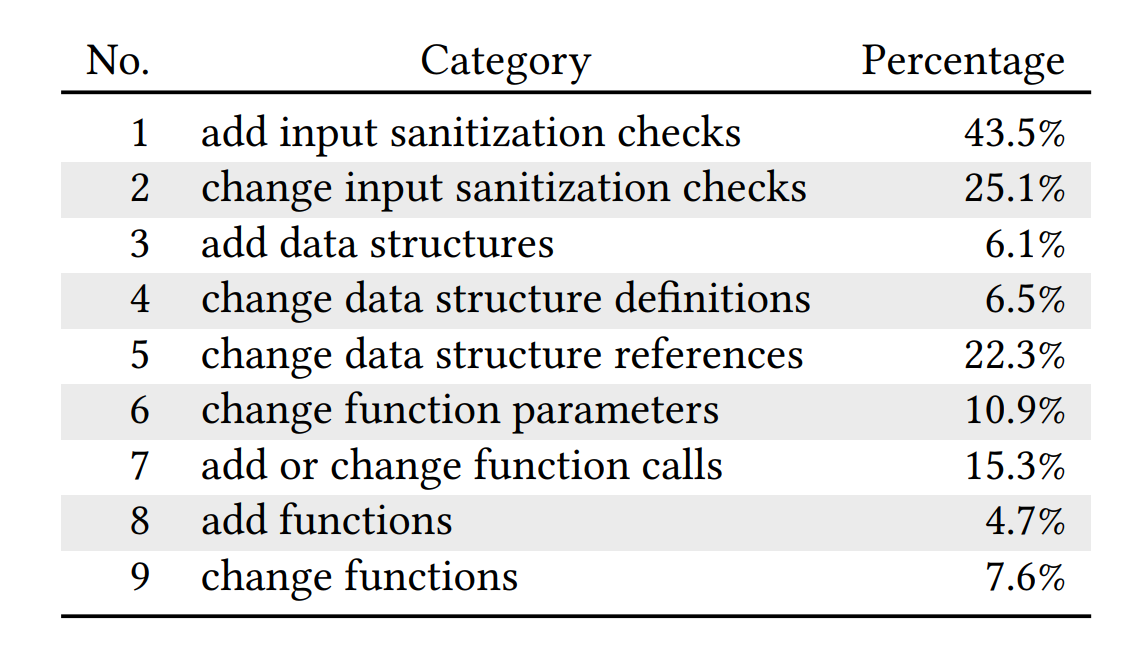
����ͼ���Կ���
- ʹ�����ķ�ʽ�����Ӷ�����İ�ȫ���
- 3��4��5�ı����ݽṹ�����ӱ������ı����������ͣ���ջ���ɶѣ�
- 6, 7, 8, and 9 �ĺ����Ͳ���
- ˵���ܶ�©������©������̫����ô�������ģ�
�����
syntactic � control flow/call graph [7, 25, 29]
semantics-aware features ���� dynamic behaviors [20] and system call sequences [5, 64]
�����˳ɹ��Ƚϣ�����һЩ���õĹ��ߣ�
BinDiff [27], Diaphora [34], and DarunGrim [49] ���ֹ�ҵ�ϳ��õĶ��������ֹ��ߣ��� [31, 47, 48, 55, 62]���汻Ӧ�á���Щ�����Ǿ�̬������
���⣺��Щ���߶Ժ�С�̶��ϵĴ���ı�ʶ��Ч���Ƚϲ�������������С��
����ִ�з�ʽ
code level [35, 51, 52] or the binary level [15, 25, 40, 70]. ʹ������ִ��Դ���뼶�Ͷ����Ƽ������÷���ִ�еõ��ļ���Ĵ���Ƭ�������ֶ����������ö���֤���������죩
DSE [51] and DiSE [52] leverage static analysis techniques to identify differences �þ�̬��ʽ��λ��������ȷ������ִ�е�����C���Ź�ʽ�ر���ָ�����ɵĹ�ʽ�������ⲹ����Ч����
At last, symbolic
execution is typically performed within a basic block [15, 25, 40]
or a loop body [70] at the binary level, which may not be scalable
to deal with complicated patches involving library function calls
(e.g., No. 6, 7, 8, and 9 in Table 1)
����ִ��һ���ǻ������ѭ�����ڲ����IJ���ȷ�����漰�⺯�����õĸ��Ӳ�������̫�ԣ�
�⺯����api���
clone detection [20, 64] and malware variant comparison [5, 23, 33, 44].��¡���Ͷ�����������Ƚϡ������ֳ����õıȽ϶�
BLEX [20]���Ѷ����ƴ��뵱�ɺںУ���̬��⣬�Ƚ����ǵ����ƶȡ�
����ai��ʶ��
[18, 19, 26, 38, 42, 43, 71, 76] ��С�Ĵ���仯������
���߶Է�����Ҫ��
- ��������Ӧ�öԻ�����֮��IJ������ж�λ
- Ӧ������ɽ��͵Ľ��
- Ӧ��Ϊ�������©���ṩ�ḻ������
memory object access sequence (MOAS)
Ϊ�˽����������Ҫ����������
MOA
�洢��������ݽṹû�����壬���ֳ�������ݽṹ�IJ�����ӳ�˷ḻ��������Ϣ�� �Ը��ֶ���ķ��ʾ���memory object access (MOA).
���ڴ�����ʾ����һ��ִ��·�����������ݽṹ��mobj=(alloc,size,type)
alloc��ʾ�����ڴ�������������Ϣ��size���ֽ�Ϊ��λ���ڴ�ռ��С��type��ʾ���Ͱ�����̬�������ڶ�������Ķ�̬�����Լ�ջ��ľֲ�����(type������̬�������ֲ�������ȫ�ֱ���)��Ϊ�ڴ��������Ķ��������Բ�ͬ���͵����ݽṹ�����Զ���allocҪ����������
alloc�ı�ʾ����
alloc�ı�ʾ������
- 1.��̬�����õ�ַ��ʾ
- 2.�ֲ�������ջָ֡���Լ�������ڵ��ú����������ġ��Ƚ�������ǼĴ����洢�ֲ��������üĴ�������ʾ��
- 3.�ѵĶ�̬������������ѵĵ�ַ�͵���malloc�ĵ�ַ��ʾ����hook mallocʵ�֣�

��ͼ�����������aͼ��temp��mobj��alloc��д�������õ������ģ�����Ҳû��˵�������main-serveconnection-Log��ջָ֡���ƫ�ơ�
Memory Object Access
A(mobj) = (mobj, cc, op, optype, ��)
-
mobj������˵����
-
cc��¼��ʹ��mobj�������ģ���Ϊmobj�ܹ�ͨ��ָ�뱻�����������ʣ�cc��������mobj�ĺ����Լ��ú�������mobj�������ġ�
-
op����mobj����������ز�������Ҫ��ע�������봫����ָ������ƶ�ָ�����ָ��Ϳ⺯��/ϵͳ���õĵ���ָ���op����ʾ��Щָ��IJ������Լ���Щָ��ĵ�ַ
-
optype �������ַ������ͣ�����д
-
�������������ֽڣ������ֶ��������ڼ��ı䡣
�ڴ���ʶ���ıȽ�
��ʱ�ڴ��������ִ��·���γ�һ���ڴ��������memory object access sequence (MOAS)
����ͬ��Poc���������ĺ�ԭʼ�ļ�����̬�ռ��ڴ���ʶ������бȽ����ǵIJ�ͬ
MOAS��洢�ڴ������䣬�ڴ����������ڴ�����������ֶεĹ�����ϵ��Ϣ
[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-SPkZjwi9-1619507620106)(./image/image-20210312165716598.png)]
��ͼ�Ƿ��������ֻ��6����ͬ�㣬��֮���bindiff��30��
a1��b2Ϊ������ڴ����a2��b2Ϊ�ڴ�����������ڼ䱻�������á�
a2��b2չʾ��������<main-serveconnection-Log> operations 0x804acd5: call sprintf operation types W/R correlated inputs��������룩 (��� [0x4, 0x15d]).
��ͼ�ıȽϽ�����Կ�����L2��R2��ͬԭ��������ռ䷽ʽ����ص��·���L3��R3��ͬ��
ͨ�������ͼ��b1��R3����������˶ѣ������۵�ִ��ȷ�������size�����볤���йأ�R2��Ȼ���ij��˶ѣ����dz��Ȳ�û�б�����ı�ͨ�������������heap��С�Ǹ�һ�������ַ�����صģ��㹻���������Ȼ�ܹ���������
�ص�����ͼ�д���IJ����������ݴ洢��stack���heap�������ݵĴ�С��������Ҳ��˵�����©����Ȼ���ܴ��ڡ�
PATCHSCOPEϵͳ���
����dynamic taint����̬�۵�ִ�У� and execution monitoring��ִ�м�أ�, memory object excavation���ڴ�����ھ�, memory object access construction���ڴ���ʶ�������MOAS alignment���ڴ���ʶ�����룩��
��̬�۵�ִ�к�ִ�й���
��**DECAF [28]**�Ļ��������ģ���һ������qemu������ϵͳ��̬����ƽ̨�� ���߽�����ʹ֧֮�ֶ��ǩ��Ⱦ�������Ҽ�¼�����������б�Ҫ������ʱ��Ϣ
ÿ�������ֽ���ΪΨһ�۵��ǩ�����һ��ָ��Ķ��Դ����������Ⱦ��������Ŀ�����������Ⱦ���Ϊ����Դ��������Ⱦ��ǵIJ�����
��Ȼ����Ҫ����һЩ����ʱָ��״̬��Ϣ��������Ҫ�ָ�ջ��ȡ��������ֽ�Ȳ�����Ϊ�˷����ȡ����Ŀռ仹��Ҫ�ٳ�ϵͳ���û��߿⺯���ĵ��á���Щ����DECAF����ʵ�֡�
��������ջʶ��
һ���Ǽ���call��ret�ԣ��ѵ��Dz������ܻᴥ����������һЩ�Ż�ѡ�����ʶ��
һ�����������tail call optimization [11] and��function inline.
- β�������Ż����Ὺ����תָ�����callָ�� GCC/Clang -O2�� -O3�����������Ż�����Apache-1.3.35���������������Ż��Ĵ���ռ�˴�Լ12%��
- ���������ǵ��õ�ʱ��ѱ��������Ĵ����������ú�����
�����
ʹ�� iCi [17]������jmp�ĵ��á���iCi�ļ��ԭ���Ǽ����ת��λ���Dz����ں����ڣ������ת���ĵط��Dz��Ǻ����Ŀ�ʼ����
�������������Ĵ�����ֱ�Ӳ��ܣ����ڲ���ʹ������ԭʼ�ļ�ûʹ�õ����������ڴ����������IJ��ֽ��ͬ��
�ھ����ݽṹ�������ֶ�
����Howard [57]��ʶ�𣬵������ߵ��ڴ����ֻ��ʶ��������ֶ���ص��ڴ������������С�
��ָ�����ȡ
[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-jfKmANo1-1619507620110)(./image/image-20210313102904140.png)]
����һ���ڴ����ͨ������һ��ָ�����Ƕ������ָ��Ϊ��ָ�롣�ڴ�����ָ����һ��һ��ϵ����ͨ����ָ����ȡ�ڴ����
- ����һ����̬��������ֱ��ʹ������ڴ��ַ��ʾ��ָ��
- ���ϵĶ�̬����hook�ڴ���亯����ȡ����ֵΪ��ָ��
- �ֲ������ĸ�ָ����ebp��ƫ������ʾ�� ��������ʱ��esp��ʾ�����ǽ����˹�һ��Ϊebp��ʾ��ִ���ڼ��¼��ִ��״̬���Լ�ָ���Ƿ��б���������ͼ�� mov $0x804b108,0x4(%esp) �к������ò�����ʱ��ʹ��esp�ķ�ʽ�����ڶ��������ǵ�����������
- fomit-frame-pointer������ʱ������ջ֡��ʱ����esp��ʾ�������û��ƽ��ջ֡�����Ϳ���ȷ���Ƿ��������Ż���
size����ȡ
- ������Ŀռ�����ɲ���ȷ����
- ���ھ�̬��������ʱ�����������߲�����������֮��ľ����ʾ��������ʱ���м���Щ�ڴ����û�б�ʹ�ã����߹�ע���ڴ��������Ǻ������йصģ�����ɴ���������Ϊ�������ڴ����֮��ıȽϿ��Ե������ֲ�ȷ���ԡ�ʶ��sizeȷ�Բ��㣬�д��Ľ��Ľ�����Խ��л����������ʶ��
��ָ�봫��
ʶ���ڴ�������ʶ���ڴ����Ķ���ͷ��䡣֮��������Щ�ڴ����
����Howard [57] ����������
- ʶ�����и�ָ�롣
- ���ͨ���ٸ�ָ��������ƶ���ʶ�����ָ��
- ��Ҫʶ��ָ���ϵ���������ָ��
- ���ͨ�����oad/store���ڴ��ַ�������Ի�ȡ��ָ�롣
���㷽ʽΪaddress = base + (index �� scale) + offset
���������ֶ�
ʹ�ö��ǩ��Ⱦ�����Ľ��ȥ�����ڴ����������ֶ�֮��Ĺ�����
��ÿ������Ⱦ�IJ�����
-
����ȷ����Ⱦ��ǩ������������ǼĴ�����˷ִ�л�ȡ������ڴ��������
-
�ڶ���ȡ��ָ��Ӹ�ָ�뵽�ڴ����������ַ��ƫ������
-
���������õ��ڴ����ʹ����۵��ǩ������֮�乹��������ϵ��
�����������ַ�����������ͨ������ѭ�������ַ�������������������heuristics������Ϊ����ʽ�㷨���������ڴ������顣
����һ����ǣ�
- ����ʶ���ڴ浥Ԫ����ͬһ�ڴ�������ڴ浥Ԫ������������ʹ�����Ը�ָ�������ƫ��������
- Ȼ������Ƿ���Ϊͬһ���ڴ����
����MOAS
����MOASȷ����mobj, cc, and ������ʣ��op and optype
-
���������ƶ�ָ�ͨ��ȷ������Ⱦ���洢��������ȷ��optype��
-
��������ָ����ȷ���Ƿ����ڴ�����һ������������ǣ�ȡ���������IJ�������Ϊop������ͨ���Ƿ���Ⱦ�Ĵ�����Դ����Ŀ�IJ�������Ϊoptype��
-
���ڵ��õĿ⺯����ʹ������ʱ����ժҪ�����Ż���Ȼ�����op��optype�������ߵ�������ģ����
MOAS����
���߳��Թ�������ִ��㷨�����ܽ�����⡣
����ѡ��ʹ�������㷨Smith-Waterman algorithm [58] ���õش������������ҵ����Ƶľֲ�������
��Ϊ��ͬ�ڴ��������в�ͬ�ĸ�ָ�룬ת��Ϊ������SMITH-WATERMAN ALGORITHM�㷨�Ƚ������ڴ���ʶ���֮������ƶȡ��ڸ�¼D��¼�˹���Ӧ������㷨��ϸ�ڡ�
ʷ��˹-�������㷨��Smith-Waterman algorithm����һ�ֽ��оֲ����бȶԣ������ȫ�ֱȶԣ����㷨�������ҳ��������������л�������֮������������㷨��Ŀ�IJ��ǽ���ȫ���еıȶԣ������ҳ����������о��и����ƶȵ�Ƭ�Ρ�������㷨�������ã�
����
����ڴ��������Ȼ��Ը�����Դ�����˲�ͬ�IJ�������ô�����ġ�