问题描述:1: ‘charmap’ codec can’t encode characters in position 12-18:
问题2: with 方法写入 txt 换行 \r\n \n 无效
# -*- coding=utf-8 -*-
import urllib.request
import reclass Funny():def __init__(self):self.working = True # 一直采集开关# 1: 下载页面def download_page(self, url):user_header = {
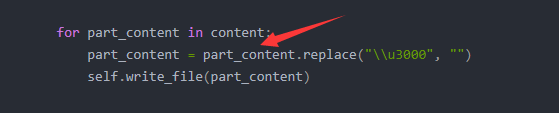
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36","cookie": "UM_distinctid=178d59b2235917-019291f17fc203-3f356b-1fa400-178d59b2236840;"}req = urllib.request.Request(url, headers=user_header)resp = urllib.request.urlopen(req)print("状态码是: " + str(resp.getcode()))print("测探的URL地址是 : " + resp.geturl())content = resp.read().decode('GBK')pattern = re.compile('<h2>([\s\S]*)<hr />', re.S)match_content = pattern.findall(content) # 这里不能把匹配到的内容,传入写入方法,会写成一行,不会把 \n , \r\n 进行编译,不知道为什么。self.deal_page(match_content)# 2: 处理每页的段子 [ 取第一个<h2> 到 <hr /> 之间的内容 ]def deal_page(self, content):print("传过来的是内容是: " + str(content))# match_content = re.finditer(r'<h2>.*?</h2>', content)# print("匹配到的内容是: " + str(match_content))# match_content = re.search('<h2>([\s\S]*)<hr />', content) # 不能贪婪匹配# match_content = re.findall('<h2>([\s\S]*)<hr />', content)for part_content in content:part_content = part_content.replace("\\u3000", "")self.write_file(part_content)# 3: 把段子写入文件里面def write_file(self, content):print("开始写入内容")with open("b.txt", "a", encoding="utf-8") as f: # 没有加 encoding="utf-8" ,报错: 'charmap' codec can't encode characters in position 12-18: character maps tof.write(content)print("内容写入完成")# 启动位置def main_entry(self, url):while self.working:self.download_page(url)continue_or_not = input("输入'no'进行中止: ") # 如果有变化的 url ,让它在 else 里面进行,并且自增(我写的时候内涵段子好像已经挂了。)if continue_or_not == "no":print("已经终止操作")self.working = Falseif __name__ == '__main__':base_url = "https://www.xuexila.com/duanzi/jingdianduanzi/1151197.html"funny_story = Funny()funny_story.main_entry(base_url)问题解决: 如上代码,with open(filename, method, encoding) 加入第三个参数,解决第一个问题,
不能把匹配的内容直接当 string 传入,把它分段传入, 解决第2个不换行的问题。