一、 Sequence to Sequence Learning with Neural Networks - 2014@NIPS
1、提出背景:
(1)虽然DNN可以解决现实生活中的很多问题,但是在解决机器翻译过程中,主要的问题是其输入和输出的长度一致。
也许你觉得可以通过padding等方式使得输入和输出长度变得不一样,比如输入是10,固定输出也是10,如果输出是5,则将剩下的5个输出使用null填充等,但是这样不太合适,而且对于很多翻译任务而言,并不能预先知道翻译结果的最大长度。
(2)另外,DNN不能充分考虑序列之间的前后关系,其翻译仅仅基于当前词。
2、提出的方法:
使用Encoder-Decoder架构,如下图所示:
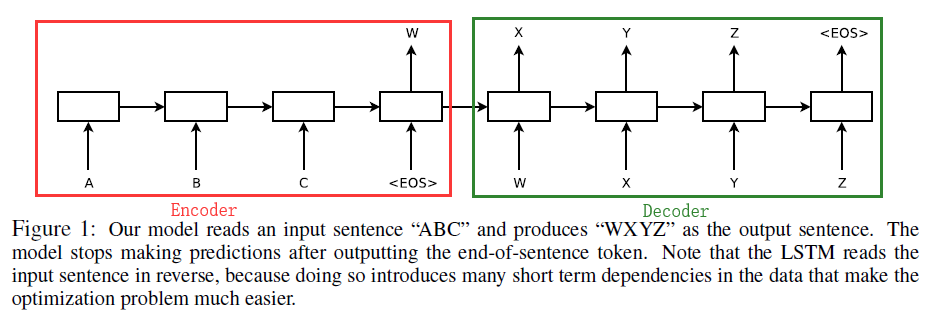
左侧是Encoder部分,其主要功能是将输入的序列处理成一个固定长度的语义特征向量W,W中含有输入序列的信息,Encoder Cell可以是RNN/GRU/LSTM。右侧是Decoder部分,主要任务是将语义特征W作为输入,首先生成target的第一个层词X,基于X和W再生成Y…,Decoder Cell可以是RNN/GRU/LSTM。(Encoder Cell和Decoder Cell的选取可以在RNN/RGU/LSTM中随便组合),文章中使用的是LSTM。
3、实验任务
English-French的翻译任务。
4、提到的小技巧
输入序列逆序的情况下,翻译效果刚好,可能是如下原因(作者好像也只是猜测):
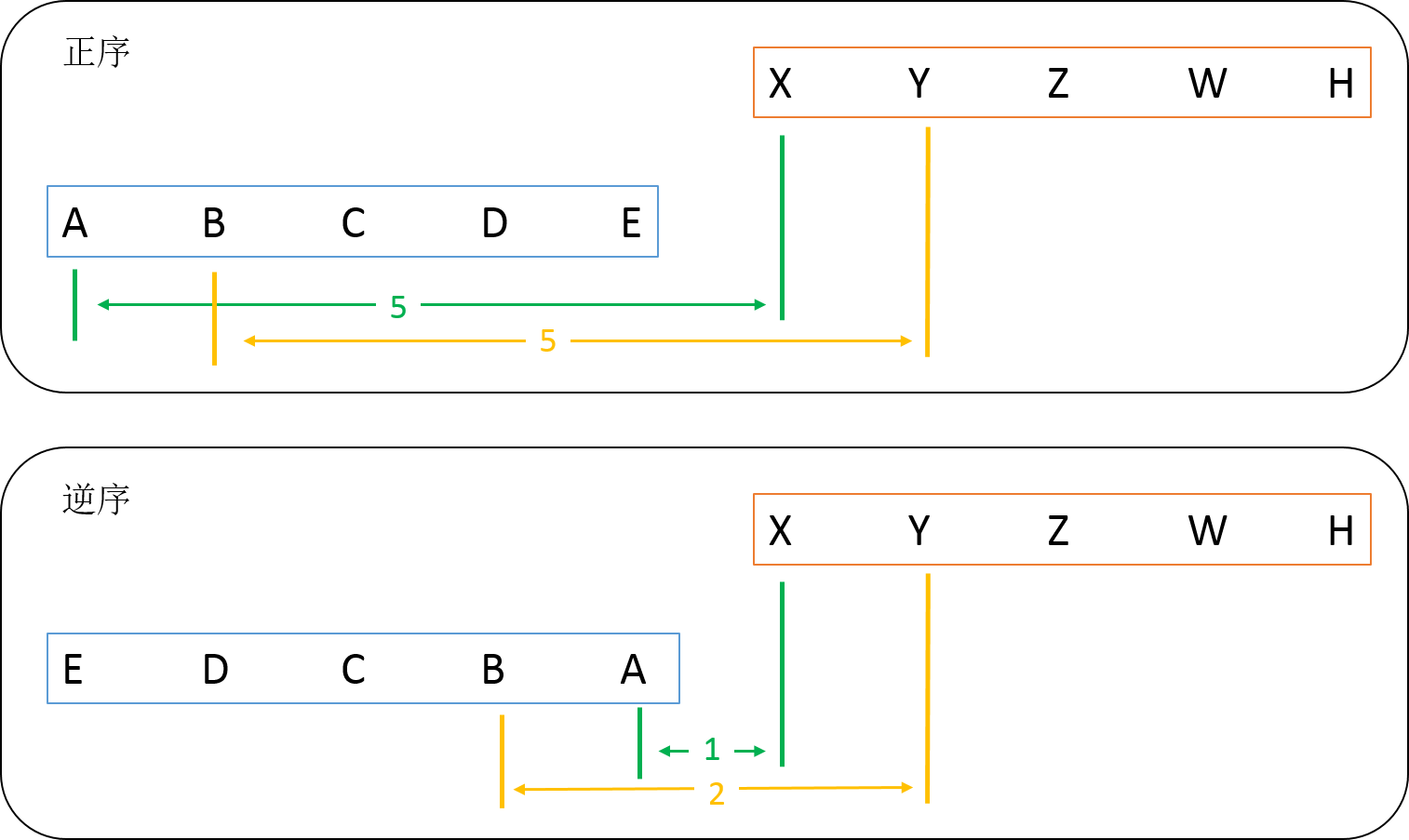
如图,在将“ABCDE”翻译成“XYZWH”任务中(假设翻译结果与次序一对一),分析如下:
对于正序的情况,A翻译成X,中间间隔距离为5;B翻译成Y也一样…。而在逆序的情况,A翻译成X,中间间隔距离为1;B翻译成Y,中间间隔距离为2,…也就是说再逆序的情况下,引入了很多短期依赖,这使得在翻译开始的词比较准确,这些准确的词会对后面的翻译带来正面影响,使得结果比正序输入更好。
二、 Neural Machine Translation by Jointly Learning to Align and Translate - 2015@ICLR
1、提出背景:
在普通的encoder-decoder模型中,将输入的整个句子encode成一个语义编码向量c,基于c再进行decoder的过程。但是语义编码向量c是性能的一个瓶颈,因为固定长度向量所包含的信息总归是有限的,而且若句子非常长,其存储的信息也非常受限。
2、提出的方法:
本文提出了一个Soft-Search的方法,也就是现在大家说的“Attention”机制,这种机制能够在翻译 y i y_i yi?的时候自动搜寻哪些输入words对当前的输出比较有用,并给这些有用的词更多的权重,使得其对输出的作用更大。
其架构如下:
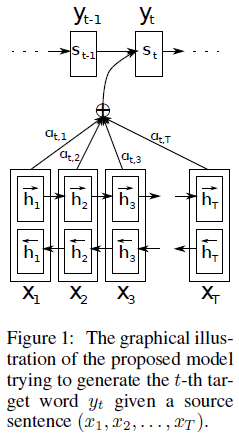
其和传统的Encoder-Decoder模型的不同在于:
(1)在传统的Encoder-Deocder模型中,直接接Encoder过程得到的语义编码向量c输入到每一个翻译的序列中,也就是说,在每个时间点输入的语义向量都是同一个c。
(2)而在含有Attetion机制的Encoder-Decoder中,语义编码向量会针对每一个时间的翻译任务有所侧重。就好像人在翻译的过程中,不是完全对一个句子进行翻译,而是几个单词几个单词一起翻译,在翻译某个单词的时候,他附近的几个词语对翻译结果的影响是最大的。
简单来说,在Decoder的过程中,传统模型每个Cell的输入都是同一个 c c c,而在Attention机制的模型中,每个Cell的输入都是不同的 c i c_i ci?。
c i c_i ci?的计算过程如下:
c i = ∑ j = 1 T x α i j h j c_i=\sum_{j=1}^{T_x}\alpha_{ij}h_j ci?=j=1∑Tx??αij?hj?
其中,
α i j = ∑ k = 1 T x e x p ( e i k ) e x p ( e i j ) , e i j = a ( s i ? 1 , h j ) \alpha_{ij} = \frac{\sum_{k=1}^{T_x}exp(e_{ik})}{exp(e_{ij})}, e_{ij}=a(s_{i-1}, h_j) αij?=exp(eij?)∑k=1Tx??exp(eik?)?,eij?=a(si?1?,hj?)
简单来说, c i c_i ci?是对所有Encoder Cell隐单元向量 h j h_j hj?的加权求和,这样就把对于当前翻译 i i i位置的任务重要的单词赋予更大的权重,使其发挥更大的作用。
那么我们如何得到权重系数呢?
文中求 e i j e_{ij} eij?又使用了一个简单的前馈神经网络,将其和整个Encoder-Decoder系统一起训练,从而得到 e i j e_{ij} eij?。
3、实验任务
English-to-French翻译任务。
注:
关于更多Seq2Seq和Attention机制的直观感受,请参见seq2seq model和Attention-based seq2seq Model(动图展示)
三、Towards Neural Phrase-based Machine Translation
1、提出背景:
(1)先前的NMT任务,Decoder部分大多数基于注意力机制。
(2)基于Phrase/Segment的翻译比基于Word的翻译效果好。
(3)SWAN使用Attention机制翻译,但是其基于的假设是原序列和目标翻译序列是单调的对应关系,这个假设性太强。
2、提出的方法:
(1)摒弃原序列和目标序列的对应关系,提出基于(soft) local reordering的思想。
(2)句子结构是自动训练的,不需要预定义。
(3)文章中的方法基于另一篇论文的模型SWAN(论文为:Sequence modeling via segmentations.),SWAN的模型如下:
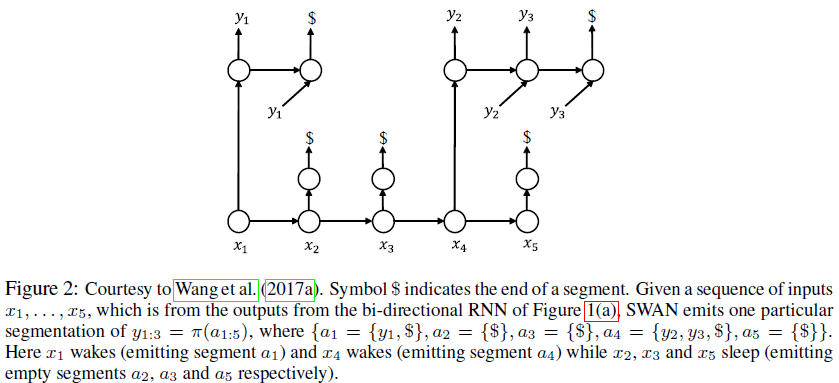
(4)本文提出的模型如下:
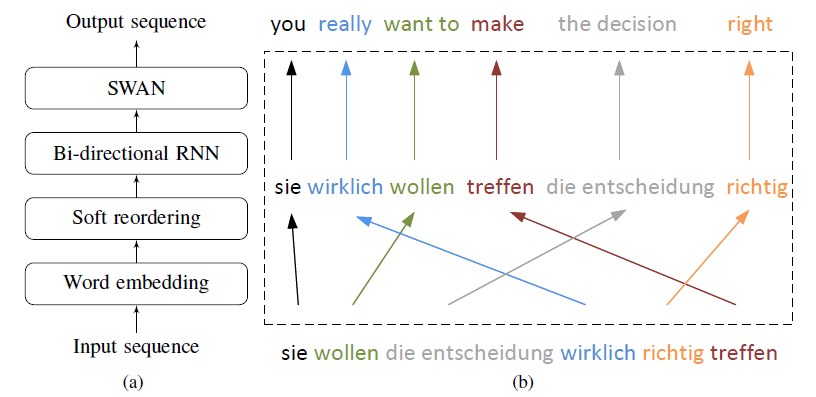
首先,对输入序列Embedding操作,其次基于Embedding的结果重新变换句子顺序,并将其输入到双向RNN中,最后,将输出的结果喂入SWAN中得到翻译结果。
(5)Reorder function.
Soft reordering第t个时间点的输出 h t h_t ht?表示如下:
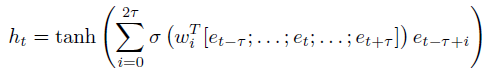
其中, σ ( ) \sigma() σ()表示sigmoid function, 2 τ + 1 2\tau +1 2τ+1表示local reordering window size, [ e t ? τ ; . . . . ; e t ; . . . . ; e t ? τ ] [e_{t-\tau};....;e_t;....;e_{t-\tau}] [et?τ?;....;et?;....;et?τ?]是向量 e t ? τ ; . . . . ; e t ; . . . . ; e t ? τ e_{t-\tau};....;e_t;....;e_{t-\tau} et?τ?;....;et?;....;et?τ?的拼接,给 w i T [ e t ? τ ; . . . . ; e t ; . . . . ; e t ? τ ] w_i^T[e_{t-\tau};....;e_t;....;e_{t-\tau}] wiT?[et?τ?;....;et?;....;et?τ?]加上一个sigmoid就当于给 e t ? τ + i e_{t-\tau+i} et?τ+i?加了一个门,最后 h t h_t ht?是所有的window中的 w i T [ e t ? τ ; . . . . ; e t ; . . . . ; e t ? τ ] w_i^T[e_{t-\tau};....;e_t;....;e_{t-\tau}] wiT?[et?τ?;....;et?;....;et?τ?]之和, e i e_i ei?表示embedding的结果。如下图所示:
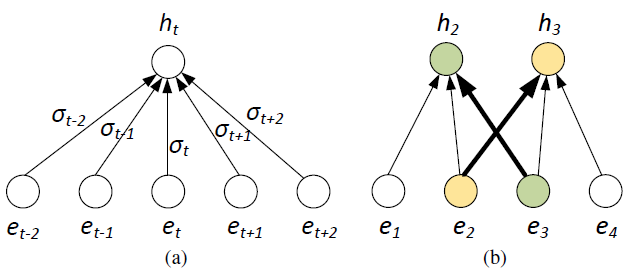
左图展示的便是上面公式的含义。比如,在右图中,如果发现 e 2 e_2 e2?在第二个窗口中比重较大, e 3 e_3 e3?在第一个窗口中比重较大,则将 e 2 e_2 e2?和 e 3 e_3 e3?交换顺序。
(6)reorder function中的 w i i = 0 2 τ {w_i}_{i=0}^{2\tau} wi?i=02τ?可以捕捉到position信息,但是attention机制并没有这个作用。
3、实验任务
(1)German-English和English-German
(2)English-Vietnamese
举例(Phrase-based):
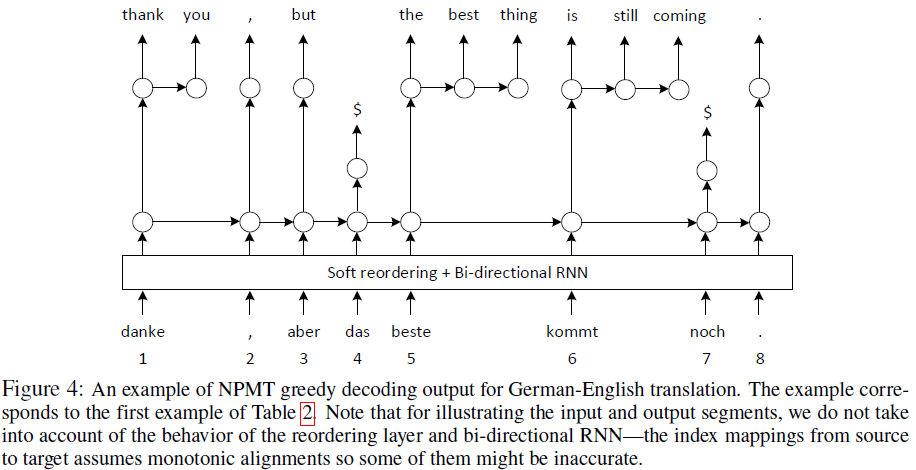
4、读后感悟
(1)主要增加了调节语序功能。
(2)实验非常丰富,但是实验主要基于小数据集。