一、梯度下降法
1、算法原理
关于梯度的优化优化方法主要包括梯度上升和梯度下降,如果想要求最大值,则使用梯度上升法,如果想要去最小值,则使用梯度下降法。本文主要讲梯度下降法,梯度下降法是指参数不断沿着负梯度方向不断更新,直到最小值,其形象化表示如下图:

如上图所示,在A处找到其梯度下降最快的方向,沿着此方向走到A1点,接着在A1点沿着下降最快的方向走到A2点,直到最终走到AEnd点。
那为什么会沿着负梯度更新,而不是沿着其他方向更新呢?对于深度学习模型,目标函数 J ( θ ) J(\theta) J(θ)关于参数 θ \theta θ的负梯度将是目标函数下降最快的方向。原因请参考:为什么梯度反方向是函数值局部下降最快的方向?
这里以线性回归为例,讲述梯度下降法的过程。
对于线性回归,假设函数为 h θ ( x ) = θ 0 + θ 1 x 1 + . . . + θ n x n h_\theta(x)=\theta_0 + \theta_1x_1 + ... + \theta_nx_n hθ?(x)=θ0?+θ1?x1?+...+θn?xn?, θ i ( 0 , 1 , . . . , n ) \theta_i(0, 1, ..., n) θi?(0,1,...,n)为参数, x i x_i xi?表示第 i i i个特征, ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x m , y n m ) {(x^1, y_1), (x^2, y_2), ..., (x^m, y_nm)} (x1,y1?),(x2,y2?),...,(xm,yn?m)为训练样本,为方便表示,我们引入 x 0 = 1 x_0=1 x0?=1,则 h θ ( x ) = ∑ i = 0 n θ i x i h_\theta(x)=\sum_{i=0}^n\theta_ix_i hθ?(x)=∑i=0n?θi?xi?,其对应的损失函数是:
J ( Θ ) = 1 2 m ∑ j = 1 m ( h θ ( x j ) ? y j ) 2 \begin{aligned} J(\Theta) = \frac{1}{2m}\sum_{j=1}^m(h_\theta(x^j)-y_j)^2 \end{aligned} J(Θ)=2m1?j=1∑m?(hθ?(xj)?yj?)2?
算法过程如下:
①算法参数初始化,初始化 θ = ( θ 0 , θ 1 , . . . , θ n ) T \theta=(\theta_0, \theta_1,..., \theta_n)^T θ=(θ0?,θ1?,...,θn?)T,更新步长 η \eta η
②确定当前位置的损失函数的梯度, ? ? θ i J ( θ 0 , θ 1 , . . . , θ n ) \frac{\partial}{\partial \theta_i}J(\theta_0, \theta_1,...,\theta_n) ?θi???J(θ0?,θ1?,...,θn?)
③看是否达到终止条件,若达到终止条件,则算法停止,否则执行参数更新: θ i : = θ i ? η ? ? θ i J ( θ 0 , θ 1 , . . . , θ n ) \theta_i := \theta_i - \eta \frac{\partial}{\partial \theta_i}J(\theta_0, \theta_1,...,\theta_n) θi?:=θi??η?θi???J(θ0?,θ1?,...,θn?)
套入到上述线性回归的例子:
? ? θ i J ( θ 0 , θ 1 , . . . , θ n ) = 1 m ∑ j = 1 m ( h θ ( x j ) ? y j ) x i j θ i : = θ i ? η 1 m ∑ j = 1 m ( h θ ( x j ) ? y j ) x i j \begin{aligned} & \frac{\partial}{\partial \theta_i}J(\theta_0, \theta_1,...,\theta_n) = \frac{1}{m}\sum_{j=1}^m( h_\theta(x^j)-y_j)x_i^j \\ & \theta_i := \theta_i - \eta \frac{1}{m}\sum_{j=1}^m( h_\theta(x^j)-y_j)x_i^j \end{aligned} ??θi???J(θ0?,θ1?,...,θn?)=m1?j=1∑m?(hθ?(xj)?yj?)xij?θi?:=θi??ηm1?j=1∑m?(hθ?(xj)?yj?)xij??
从上面的公式可以看到,因为有求和,参数的更新是基于所有的样本,其能得到全局最优解,求解的参数满足风险函数最小化。但是这种参数更新存在的问题是如果样本数量很大,会导致性能很差,这种更新方式叫做批量梯度下降法,后面会提到随机梯度下降和min-batch梯度下降。
对于批量梯度下降,样本数目为 m m m,特征数目为 n n n,一次迭代需要将 m m m个样本全部带入计算,迭代一次计算量为 m ? n 2 m*n^2 m?n2
2、批量梯度下降、随机梯度下降、小批量梯度下降
上次提到的便是批量梯度下降,参数的每次更新都需要计算全部样本。这种方法可以得到全局最优解,但是其存在的主要问题是需要大量内存,每次学习时间较长(全样本要迭代至少几次才可以收敛)。批量梯度下降易于并行化实现,且整体迭代次数较少。
随机梯度下降是指每个样本迭代更新一次参数,如果数据量很大,可能使用其中一部分样本就已经将参数更新完毕,这时,我们可以只对样本扫描一遍,而对于批量梯度下降,需要扫描多遍全样本,所以随机梯度下降的训练速度更快。但是随机梯度下降很难达到全局最优解,其得到的局部最优解。随机梯度下降一次只使用一个样本,迭代一次计算量为 n 2 n^2 n2。不易于并行实现,收敛波动较大。但是需要较小的内存空间。
小批量梯度下降是对批量梯度下降和随机梯度下降的折中,其在每次迭代时使用batch_size个样本对参数进行更新。其优点如下:
- 通过矩阵运算,每次在一个batch_size上优化神经网络参数并不会比单个数据慢太多
- 每次一个batch_size会使得迭代次数减小,相对于随即梯度下降,也更接近于批量梯度下降的效果。
- 可实现并行化,并且batch_size个样本不需要太大的内存空间,是批梯度下降和随机梯度下降的折中。
批量梯度下降、随机梯度下降和小批量梯度下降的更新过程对比如下:
①批量梯度下降
J t r a i n ( θ ) = 1 2 m ∑ j = 1 m ( h θ ( x j ) ? y j ) 2 J_{train}(\theta)=\frac{1}{2m}\sum_{j=1}^{m}(h_\theta(x^j)-y_j)^2 Jtrain?(θ)=2m1?∑j=1m?(hθ?(xj)?yj?)2
Repeat{
θ i : = θ i ? η 1 m ∑ j = 1 m ( h θ ( x j ) ? y j ) x i j \theta_i := \theta_i-\eta\frac{1}{m}\sum_{j=1}^m( h_\theta(x^j)-y_j)x_i^j θi?:=θi??ηm1?∑j=1m?(hθ?(xj)?yj?)xij? (for every i = 0 , . . . , n i=0,...,n i=0,...,n)
}
②随机梯度下降
c o s t ( θ , ( x i , y i ) ) = 1 2 ( h θ ( x i ) ? y i ) 2 cost(\theta, (x^i, y_i)) = \frac{1}{2}(h_\theta(x^i)-y_i)^2 cost(θ,(xi,yi?))=21?(hθ?(xi)?yi?)2
J t r a i n ( θ ) = 1 m ∑ j = 1 m c o s t ( θ , ( x i , y i ) ) J_{train}(\theta)=\frac{1}{m}\sum_{j=1}^{m} cost(\theta, (x^i, y_i)) Jtrain?(θ)=m1?∑j=1m?cost(θ,(xi,yi?))
将 m m m个样本随机打乱顺序,即将 m m m个样本重新排列,这可以让算法收敛速度更快。
Repeat{
f o r for for j = 1 , 2 , . . . m j = 1, 2, ... m j=1,2,...m:
θ i : = θ i ? η ( h θ ( x j ) ? y j ) x i j \theta_i:= \theta_i-\eta( h_\theta(x^j)-y_j)x_i^j θi?:=θi??η(hθ?(xj)?yj?)xij? (for every i = 0 , . . . , n i=0,...,n i=0,...,n)
}
}
③小批量梯度下降
假设batch_size = 10,我们记为 b b b,则其算法更新过程如下:
取10个样本 ( x j , y j ) , . . . , ( x ( j + 9 ) , y ( j + 9 ) ) (x^j, y_j), ..., (x^{(j+9)}, y_{(j+9)}) (xj,yj?),...,(x(j+9),y(j+9)?):
θ i : = θ i ? η 1 10 ∑ k = j j + 9 ( h θ ( x k ) ? y k ) x i k \theta_i := \theta_i-\eta\frac{1}{10}\sum_{k=j}^{j+9}( h_\theta(x^k)-y_k)x_i^k θi?:=θi??η101?∑k=jj+9?(hθ?(xk)?yk?)xik? (for every i = 0 , . . . , n i=0,...,n i=0,...,n)
j:=j+10
即详细过程如下:
Say b = 10 , m = 1000 b = 10, m = 1000 b=10,m=1000.
Repeat{
f o r for for j = 1 , 11 , 21 , . . . , 991 j = 1,11,21,...,991 j=1,11,21,...,991:
θ i : = θ i ? η 1 10 ∑ k = j j + 9 ( h θ ( x k ) ? y k ) x i k \theta_i:= \theta_i-\eta\frac{1}{10}\sum_{k=j}^{j+9}( h_\theta(x^k)-y_k)x_i^k θi?:=θi??η101?∑k=jj+9?(hθ?(xk)?yk?)xik? (for every i = 0 , . . . , n i=0,...,n i=0,...,n)
}
二、最小二乘法
1、原理
最小二乘法,又叫做最小平方法,它通过最小化误差的平方和寻找数据的最佳函数匹配,思想比较简单,最小二乘法可以求出参数的解析解。下面仍然以线性回归为例说明最小二乘法的计算过程。
假设函数 h θ ( x ) = ∑ i = 0 n x i θ i h_\theta(x)=\sum_{i=0}^nx_i\theta_i hθ?(x)=∑i=0n?xi?θi?,目标函数为 J ( Θ ) = 1 2 m ∑ j = 1 m ( h θ ( x j ) ? y j ) 2 J(\Theta) = \frac{1}{2m}\sum_{j=1}^m(h_\theta(x^j)-y_j)^2 J(Θ)=2m1?∑j=1m?(hθ?(xj)?yj?)2,将其使用向量化表示如下:
X = ( 1 x 1 1 x 2 1 . . . x n 1 1 x 1 2 x 2 2 . . . x n 2 1 . . . . . . . . . . . . 1 x 1 m x 2 m . . . x n m ) = ( 1 ( x 1 ) T 1 ( x 2 ) T . . . . . . 1 ( x m ) T ) \begin{aligned} X=\begin{pmatrix} 1 & x_1^1 &x_2^1 & ... &x_n^1 \\ 1 &x_1^2 & x_2^2 & ... & x_n^2\\ 1 & ... & ... & ... & ... \\ 1 & x_1^m& x_2^m&... & x_n^m \end{pmatrix}=\begin{pmatrix} 1 &(x^1)^T \\ 1& (x^2)^T \\ ...&...\\ 1 & (x^m)^T \end{pmatrix} \end{aligned} X=?????1111?x11?x12?...x1m??x21?x22?...x2m??............?xn1?xn2?...xnm???????=?????11...1?(x1)T(x2)T...(xm)T???????
标签值 y = ( y 1 , y 2 , . . . , y m ) T y=(y_1, y_2, ..., y_m)^T y=(y1?,y2?,...,ym?)T,参数 θ = ( θ 0 , θ 1 , . . . , θ n ) T \theta=(\theta_0, \theta_1,..., \theta_n)^T θ=(θ0?,θ1?,...,θn?)T,则最小化目标函数转化如下:
arg ? min ? θ J ( θ ) = 1 2 m ∑ j = 1 m ( h θ ( x j ) ? y j ) 2 = > arg ? min ? θ ∑ j = 1 m ( h θ ( x j ) ? y j ) 2 = > arg ? min ? θ ∑ j = 1 m ( ∑ i = 0 n x i θ i ? y j ) 2 = > arg ? min ? θ ( X θ ? y ) T ( X θ ? y ) \begin{aligned} &\mathop{\arg\min}_{\theta}J(\theta) = \frac{1}{2m}\sum_{j=1}^m(h_\theta(x^j)-y_j)^2 \\ &=> \mathop{\arg\min}_{\theta}\sum_{j=1}^m(h_\theta(x^j)-y_j)^2 \\ &=>\mathop{\arg\min}_{\theta}\sum_{j=1}^m(\sum_{i=0}^nx_i\theta_i-y_j)^2 \\ &=>\mathop{\arg\min}_{\theta}(X\theta-y)^T(X\theta-y) \end{aligned} ?argminθ?J(θ)=2m1?j=1∑m?(hθ?(xj)?yj?)2=>argminθ?j=1∑m?(hθ?(xj)?yj?)2=>argminθ?j=1∑m?(i=0∑n?xi?θi??yj?)2=>argminθ?(Xθ?y)T(Xθ?y)?
令 E w = ( X θ ? y ) T ( X θ ? y ) E_w=(X\theta-y)^T(X\theta-y) Ew?=(Xθ?y)T(Xθ?y),对 θ \theta θ求导,得:
? E w ? θ = 2 X T ( X θ ? y ) \begin{aligned} \frac{\partial E_w}{\partial \theta} = 2X^T(X\theta-y) \end{aligned} ?θ?Ew??=2XT(Xθ?y)?
令 ? E w ? θ = 0 \frac{\partial E_w}{\partial \theta}=0 ?θ?Ew??=0,则参数 θ \theta θ为:
θ ^ = ( X T X ) ? 1 X T y \begin{aligned} \hat{\theta} = (X^TX)^{-1}X^Ty \end{aligned} θ^=(XTX)?1XTy?
将其带入假设方程 h θ ( x ) h_\theta(x) hθ?(x)即可以得到线性回归的假设函数。
2、优缺点
- 相比较于梯度下降,不需要选择步长。
- 如果样本量不大,且存在解析解,则最小二乘法是更好的选择。但是如果样本量很大,则求逆矩阵复杂度比较高,此时选择梯度下降更好。
- 计算速度很快
三、牛顿法
牛顿法一般有两个用途,一种是用于求方程的根,一种是用来求最值。下面将就这两个问题分开讨论。
1、牛顿法求方程的根
牛顿法解方程的根的思想是利用泰勒公式的前几项来不断逼近 f ( x ) = 0 f(x)=0 f(x)=0的根。 f ( x ) f(x) f(x)泰勒公式的一阶展开式为:
f ( x ) = f ( x 0 ) + f ′ ( x 0 ) ( x ? x 0 ) \begin{aligned} f(x) = f(x_0) + f'(x_0)(x-x_0) \end{aligned} f(x)=f(x0?)+f′(x0?)(x?x0?)?
现在想求 f ( x ) = 0 f(x)=0 f(x)=0的根,则另泰勒公式 f ( x ) = 0 f(x)=0 f(x)=0可得:
0 = f ( x 0 ) + f ′ ( x 0 ) ( x ? x 0 ) = > x = x 0 ? f ( x 0 ) f ′ ( x 0 ) \begin{aligned} &0=f(x_0)+f'(x_0)(x-x_0) \\ &=>x = x_0 - \frac{f(x_0)} {f'(x_0)} \end{aligned} ?0=f(x0?)+f′(x0?)(x?x0?)=>x=x0??f′(x0?)f(x0?)??
我们将新求得的点的x坐标命名为 x 1 x_1 x1?,通常 x 1 x_1 x1?会比 x 0 x_0 x0?更接近于方程 f ( x ) = 0 f(x)=0 f(x)=0的解,因此可以利用下面的公式不断迭代:
x n + 1 = x n ? f ( x n ) f ′ ( x n ) \begin{aligned} x_{n+1} = x_n - \frac{f(x_n)} {f'(x_n)} \end{aligned} xn+1?=xn??f′(xn?)f(xn?)??
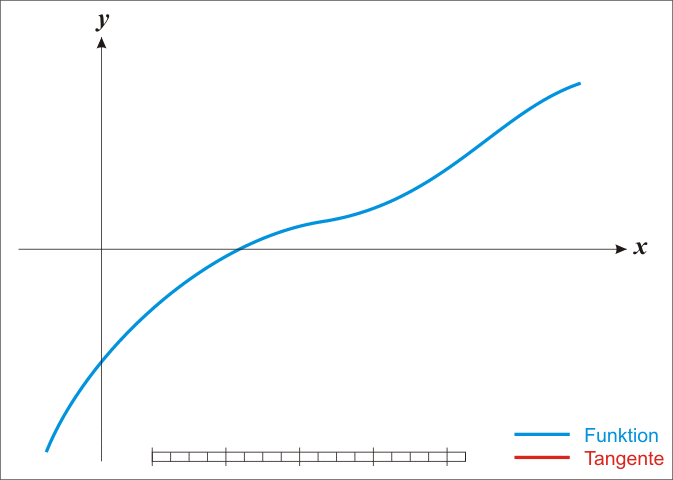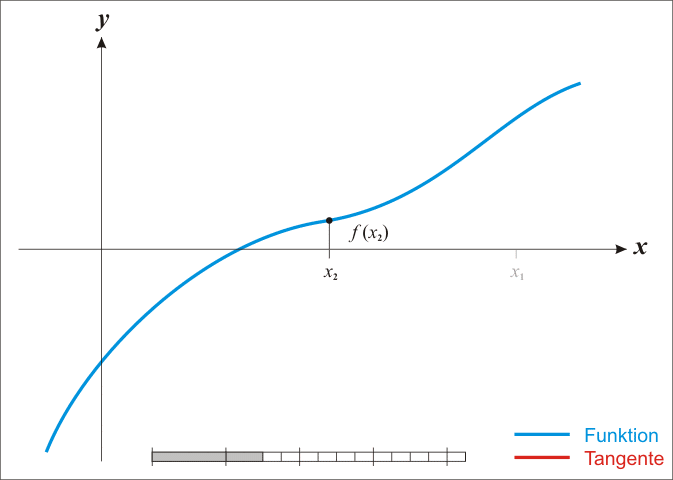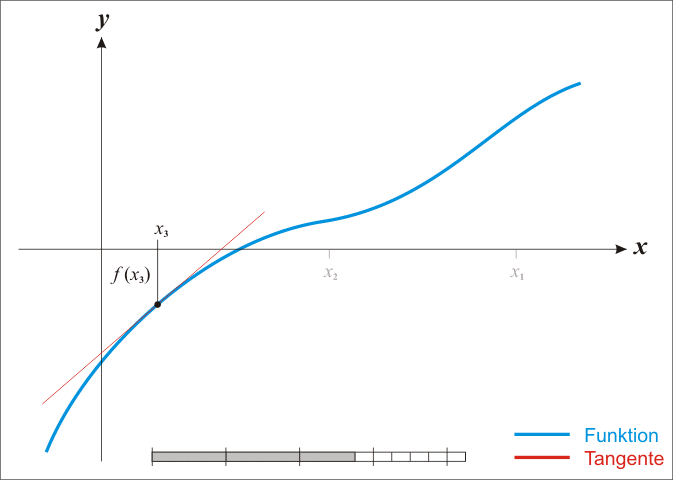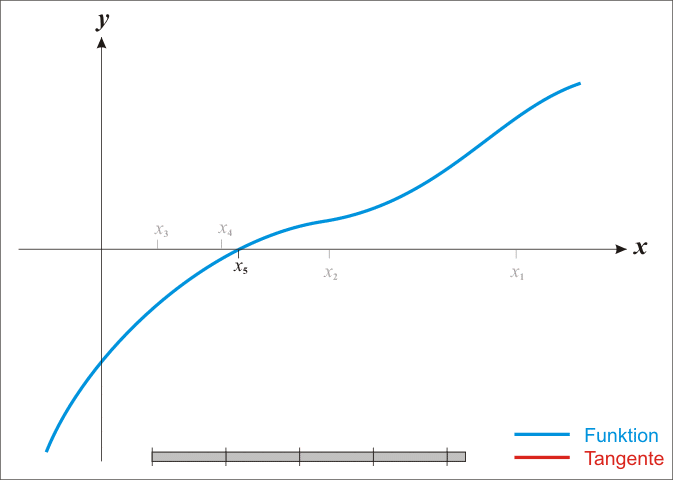
上图是使用牛顿法求解 f ( x ) = 0 f(x)=0 f(x)=0的解的例子,可以看出, x n x_n xn?的值不断逼近方程的根。
2、牛顿法求最值
上述使用牛顿法求解 f ( x ) = 0 f(x)=0 f(x)=0的时候,我们将等式左边 f ( x ) f(x) f(x)置0,现在如果我们想使用牛顿法求最值,则根据极大似然估计的思想,当 f ( x ) f(x) f(x)取得极值时, f ′ ( x ) = 0 f'(x)=0 f′(x)=0。假设 f ( x ( k ) ) f(x^{(k)}) f(x(k))为第 k k k次的迭代值,则 f ( x ) f(x) f(x)在 f ( x ( k ) ) f(x^{(k)}) f(x(k))的泰勒公式的二阶展开式为:
f ( x ) = f ( x ( k ) ) + f ′ ( x ( k ) ) ( x ? x ( k ) ) + 1 2 ( x ? x ( k ) ) T f ′ ′ ( x ( k ) ) ( x ? x ( k ) ) \begin{aligned} f(x) = f(x^{(k)}) + f'(x^{(k)})(x-x^{(k)}) + \frac{1}{2}(x-x^{(k)})^Tf''(x^{(k)})(x-x^{(k)}) \end{aligned} f(x)=f(x(k))+f′(x(k))(x?x(k))+21?(x?x(k))Tf′′(x(k))(x?x(k))?
现在令 f ′ ( x ) = 0 f'(x)=0 f′(x)=0,等式左右两边求一阶导数得:
0 = f ′ ( x ) = f ′ ( x ( k ) ) + f ′ ′ ( x ( k ) ) ( x ? x ( k ) ) = > x = x ( k ) ? f ′ ( x ( k ) ) f ′ ′ ( x ( k ) ) \begin{aligned} &0=f'(x)= f'(x^{(k)}) + f''(x^{(k)})(x-x^{(k)}) \\ &=>x = x^{(k)} - \frac{ f'(x^{(k)})}{f''(x^{(k)})} \end{aligned} ?0=f′(x)=f′(x(k))+f′′(x(k))(x?x(k))=>x=x(k)?f′′(x(k))f′(x(k))??
因此,牛顿法求最值的迭代公式为:
x ( k + 1 ) = x ( k ) ? f ′ ( x ( k ) ) f ′ ′ ( x ( k ) ) \begin{aligned} x^{(k+1)} = x^{(k)} - \frac{ f'(x^{(k)})}{f''(x^{(k)})} \end{aligned} x(k+1)=x(k)?f′′(x(k))f′(x(k))??
从上述更新公式可知,在使用牛顿法求最值的时候需要计算一阶导数矩阵和二阶导数矩阵(海瑟矩阵,当 f ( x ) 取 极 小 值 时 , 海 瑟 矩 阵 正 定 f(x)取极小值时,海瑟矩阵正定 f(x)取极小值时,海瑟矩阵正定),但是海瑟矩阵的逆计算起来还是比较耗时的,所以后续引入了拟牛顿法。
3、优缺点
- 相比较于梯度下降法,梯度下降法只引入了一阶导数信息,而牛顿法引入了二阶导数信息。
- 收敛速度快,但是需要计算海瑟矩阵的逆矩阵,计算较复杂
四、拟牛顿法
在牛顿法中,海瑟矩阵的逆需要计算,这一过程非常耗时,所以我们考虑使用一个 n n n阶 G k = G ( x ( k ) ) G_k=G(x^{(k)}) Gk?=G(x(k))来踢近似 f ′ ′ ( x ( k ) ) ? 1 f''(x^{(k)})^{-1} f′′(x(k))?1,这就是拟牛顿法的基本思想(此部分使用李航老师的统计学习方法中的内容)。
先看牛顿法迭代中海瑟矩阵满足的条件 f ′ ( x ( k + 1 ) ) ? f ′ ( x ( k ) ) = f ′ ′ ( x ( k ) ) ( x ( k + 1 ) ? x ( k ) ) f'(x^{(k+1)}) - f'(x^{(k)}) = f''(x^{(k)})(x^{(k+1)}- x^{(k)}) f′(x(k+1))?f′(x(k))=f′′(x(k))(x(k+1)?x(k)),记 y k = f ′ ( x ( k + 1 ) ) ? f ′ ( x ( k ) ) y_k =f'(x^{(k+1)}) - f'(x^{(k)}) yk?=f′(x(k+1))?f′(x(k)), δ k = x ( k + 1 ) ? x ( k ) \delta_k=x^{(k+1)}- x^{(k)} δk?=x(k+1)?x(k),则:
y k = f ′ ′ ( x ( k ) ) δ k = > f ′ ′ ( x ( k ) ) ? 1 y k = δ k \begin{aligned} y_k = f''(x^{(k)})\delta_k =>f''(x^{(k)})^{-1}y_k=\delta_k \end{aligned} yk?=f′′(x(k))δk?=>f′′(x(k))?1yk?=δk??
上式成为拟牛顿条件。
拟牛顿法将 G k G_k Gk?作为 f ′ ′ ( x ( k ) ) ? 1 f''(x^{(k)})^{-1} f′′(x(k))?1的近似,要求矩阵 G k G_k Gk?满足同样的条件,首先 G k G_k Gk?需要是正定的,同时,需满足下式:
G k y k = δ k \begin{aligned} G_ky_k=\delta_k \end{aligned} Gk?yk?=δk??
按照拟牛顿条件 G k G_k Gk?作为 f ′ ′ ( x ( k ) ) ? 1 f''(x^{(k)})^{-1} f′′(x(k))?1的近似,或者选择 B k B_k Bk?作为 f ′ ′ ( x ( k ) ) f''(x^{(k)}) f′′(x(k))的近似,这种算法成为拟牛顿法。
其更新方程为:
G k + 1 = G k + Δ G k \begin{aligned} G_{k+1}=G_k + \Delta G_k \end{aligned} Gk+1?=Gk?+ΔGk??
下面分别介绍选择 G k G_k Gk?的方法,主要包括DFP(Davidon-Fletcher-Powell)算法、BFGS(Broyden-Fletcher-Goldfarb-Shanno)算法和Broyden算法。
1、DFP算法
DFP算法选择 G k + 1 G_{k+1} Gk+1?的方法是,假设每一步迭代中矩阵 G k + 1 G_{k+1} Gk+1?是由 G k G_k Gk?加上两个附加项构成的,即: G k + 1 = G k + P k + Q k G_{k+1}=G_k +P_k+Q_k Gk+1?=Gk?+Pk?+Qk?,其中 P k P_k Pk?和 Q k Q_k Qk?是待定矩阵,则 G k + 1 y k = G k y k + P k y k + Q k y k G_{k+1}y_k=G_ky_k+P_ky_k+Q_ky_k Gk+1?yk?=Gk?yk?+Pk?yk?+Qk?yk?,为使 G k + 1 G_{k+1} Gk+1?满足拟牛顿条件,可使 P k P_k Pk?和 Q k Q_k Qk?满足: P k y k = δ k P_ky_k=\delta_k Pk?yk?=δk?, Q k y k = ? G k y k Q_ky_k=-G_ky_k Qk?yk?=?Gk?yk?,可以取如下值,使其满足要求:
P k = δ k δ k T δ k T y k Q k = ? G k y k y k T G k y k T G k y k \begin{aligned} P_k &= \frac{\delta_k\delta_k^T}{\delta_k^Ty_k} \\ Q_k &= - \frac{G_ky_ky_k^TG_k}{y_k^TG_ky_k} \end{aligned} Pk?Qk??=δkT?yk?δk?δkT??=?ykT?Gk?yk?Gk?yk?ykT?Gk???
此时迭代公式为:
G k + 1 = G k + δ k δ k T δ k T y k ? G k y k y k T G k y k T G k y k \begin{aligned} G_{k+1} = G_k + \frac{\delta_k\delta_k^T}{\delta_k^Ty_k} - \frac{G_ky_ky_k^TG_k}{y_k^TG_ky_k} \end{aligned} Gk+1?=Gk?+δkT?yk?δk?δkT???ykT?Gk?yk?Gk?yk?ykT?Gk???
2、BFGS算法
DFP算法考虑的思路是使用 G k G_k Gk?逼近海瑟矩阵的逆矩阵 f ′ ′ ( x ( k ) ) ? 1 f''(x^{(k)})^{-1} f′′(x(k))?1,我们还可以选择使用 B k B_k Bk?( B k B_k Bk?一般选择正定对称矩阵)逼近海瑟矩阵 f ′ ′ ( x ( k ) ) f''(x^{(k)}) f′′(x(k)),这时相应的拟牛顿条件为: B k δ k = y k B_k\delta_k=y_k Bk?δk?=yk?,我们可以使用和DFP算法类似的方法得到迭代公式,首先,令 B k + 1 = B k + P k + Q k B_{k+1}=B_k + P_k + Q_k Bk+1?=Bk?+Pk?+Qk?,则 B k + 1 δ k = B k δ k + P k δ k + Q k δ k B_{k+1}\delta_k = B_k\delta_k + P_k\delta_k + Q_k\delta_k Bk+1?δk?=Bk?δk?+Pk?δk?+Qk?δk?,考虑使 P k P_k Pk?和 Q k Q_k Qk?同时满足 P k δ k = y k P_k\delta_k=y_k Pk?δk?=yk?, Q k δ k = ? B k δ k Q_k\delta_k=-B_k\delta_k Qk?δk?=?Bk?δk?,找出适合条件的公式,迭代公式可以是:
G k + 1 = G k + y k y k T y k T δ k ? B k δ k δ k T B k δ k T B k δ k \begin{aligned} G_{k+1} = G_k + \frac{y_ky_k^T}{y_k^T\delta_k} - \frac{B_k\delta_k\delta_k^TB_k}{\delta_k^TB_k\delta_k} \end{aligned} Gk+1?=Gk?+ykT?δk?yk?ykT???δkT?Bk?δk?Bk?δk?δkT?Bk???
3、优缺点
- 改善了牛顿法求海瑟矩阵的逆矩阵的计算复杂的缺陷,使用正定矩阵来近似海瑟矩阵的逆,简化了计算复杂度。
五、共轭梯度法
共轭梯度法是求解线性方程组的一种很有效的方法,当然也可以通过改进适用于非线性方程组,但是这里讲线性方程组的情况。
共轭梯度法也是一个迭代求解的算法。它在梯度下降法的基础上进行了改良,梯度下降法的所有参数更新的方向是负梯度方向。在共轭梯度中,初始点的下降方向仍然是负梯度方,但后面的迭代方向是该点的负梯度方向和前一次迭代方向(共轭方向)形成的凸锥中的一个方向(大概就是两个方向的线性组合),这可以避免梯度下降的“锯齿”现象,如下图所示:
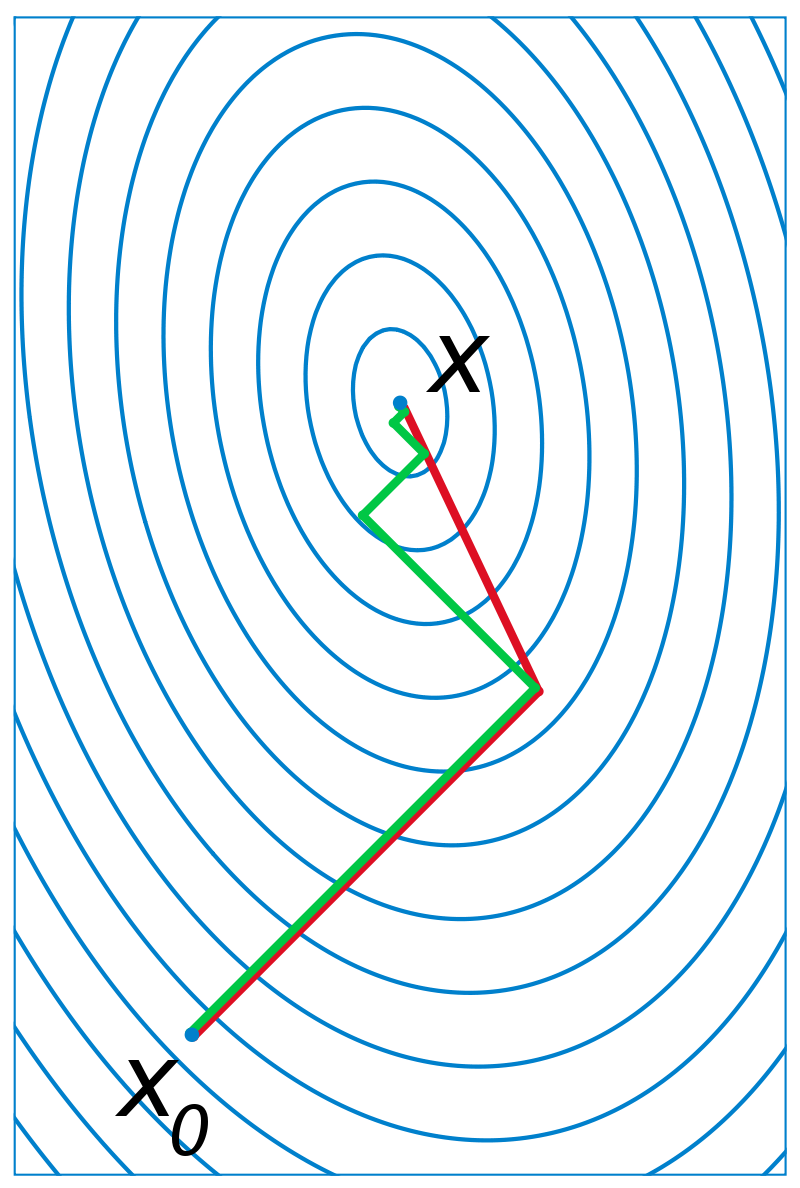
绿色线条表示梯度下降的曲线,红色线条表示共轭梯度法下降的曲线。因为梯度下降法总是沿着负梯度方向进行一维搜索,所以相邻的迭代方向是正交的,所以会出现“锯齿”现象,而且刚开始下降很多,后来下降速度越来越慢。而共轭梯度法相当于每次搜索一个方向,但是搜索一步到位,不会出现“锯齿”现象。
1、什么是共轭?
设 A A A是对称正定矩阵,其维度是 n ? n n*n n?n,若 R n R^n Rn中两个方向 d ( i ) d^{(i)} d(i)和 d ( j ) d^{(j)} d(j)满足 ( d ( i ) ) T A d ( j ) = 0 (d^{(i)})^TAd^{(j)}=0 (d(i))TAd(j)=0,则称 d ( i ) d^{(i)} d(i)和 d ( j ) d^{(j)} d(j)关于 A A A共轭。
若 d ( 1 ) , d ( 2 ) , . . . , d ( k ) d^{(1)}, d^{(2)}, ..., d^{(k)} d(1),d(2),...,d(k)是 R n R^n Rn中 k k k个方向,他们关于 A A A两两共轭,即满足 ( d ( i ) ) T A d ( j ) = 0 ( i ≠ j 且 i , j = 1 , 2 , . . . k ) (d^{(i)})^TAd^{(j)}=0(i \neq j且i,j=1,2,...k) (d(i))TAd(j)=0(i??=j且i,j=1,2,...k),则称这组方向是 A A A共轭的,或者称它们是 A A A的 k k k个共轭方向。
2、问题建模
我们讨论下述二次凸函数的共轭梯度法:
m i n f ( x ) = 1 2 x T A x + b T x + c \begin{aligned} min f(x) = \frac{1}{2}x^TAx+b^Tx + c \end{aligned} minf(x)=21?xTAx+bTx+c?
其中, x ∈ R n x \in R^n x∈Rn, A A A是对称正定矩阵, c c c是常数
3、算法流程
其大致流程如下:
Step1:初始化
给定任意一个初始点 x ( 0 ) x^{(0)} x(0),计算出目标函数 f ( x ) f(x) f(x)在这点的梯度,记为 f ′ ( x ( 0 ) ) f'(x^{(0)}) f′(x(0)),如果 ∣ ∣ f ′ ( x ( 0 ) ) ∣ ∣ ≠ 0 ||f'(x^{(0)})|| \neq 0 ∣∣f′(x(0))∣∣??=0,则停止计算,否则令 d ( 0 ) = ? ▽ f ( x ( 0 ) ) = ? f ′ ( x ( 0 ) ) d^{(0)}=-\bigtriangledown f(x^{(0)})=-f'(x^{(0)}) d(0)=?▽f(x(0))=?f′(x(0)).
Step2:迭代更新
沿方向 d ( 0 ) d^{(0)} d(0)搜索,得到点 x ( 1 ) x^{(1)} x(1),计算出目标函数 f ( x ) f(x) f(x)在点 x ( 1 ) x^{(1)} x(1)的梯度,若 ∣ ∣ f ′ ( x ( 1 ) ) ∣ ∣ ≠ 0 ||f'(x^{(1)})|| \neq 0 ∣∣f′(x(1))∣∣??=0,则利用 ? f ′ ( x ( 1 ) ) -f'(x^{(1)}) ?f′(x(1))和搜索方向(共轭方向) d ( 0 ) d^{(0)} d(0)构造第2个搜索方向 d ( 1 ) d^{(1)} d(1),再沿着方向 d ( 1 ) d^{(1)} d(1)搜索…不断迭代。
为方便公式书写,形式化表达如下:在第 k k k轮迭代中,已知点 x ( k ) x^{(k)} x(k)和搜索方向 d ( k ) d^{(k)} d(k)(注:所有的搜索方向是互为共轭的),则从 x ( k ) x^{(k)} x(k)出发沿着 d ( k ) d^{(k)} d(k)进行搜索得到:
x ( k + 1 ) = x ( k ) + λ ( k ) d ( k ) \begin{aligned} x^{(k+1)} = x^{(k)} + \lambda^{(k)}d^{(k)} \end{aligned} x(k+1)=x(k)+λ(k)d(k)?
其中,步长 λ ( k ) \lambda^{(k)} λ(k)满足 f ( x ( k ) + λ ( k ) d ( k ) ) = m i n λ f ( x ( k ) + λ ( k ) d ( k ) ) f(x^{(k)} + \lambda^{(k)}d^{(k)})=min_{\lambda}f(x^{(k)} + \lambda^{(k)}d^{(k)}) f(x(k)+λ(k)d(k))=minλ?f(x(k)+λ(k)d(k)),此时可求出 λ ( k ) \lambda^{(k)} λ(k)的显示表达 φ ( λ ) = f ( x ( k ) + λ d ( k ) ) \varphi(\lambda)=f(x^{(k)} + \lambda d^{(k)}) φ(λ)=f(x(k)+λd(k)). 下面将通过求 φ ( λ ) \varphi(\lambda) φ(λ)的最小值,确定 λ ( k ) \lambda^{(k)} λ(k)的更新公式。
4、求步长 λ ( k ) \lambda^{(k)} λ(k)
对 φ ( λ ) = f ( x ( k ) + λ d ( k ) ) = f ( x ( k + 1 ) ) \varphi(\lambda)=f(x^{(k)} + \lambda d^{(k)})=f(x^{(k+1)}) φ(λ)=f(x(k)+λd(k))=f(x(k+1))关于 λ \lambda λ求导,则:
φ ′ ( λ ) = f ′ ( x ( k + 1 ) ) T d ( k ) \begin{aligned} \varphi'(\lambda)=f'(x^{(k+1)})^Td^{(k)} \end{aligned} φ′(λ)=f′(x(k+1))Td(k)?
令 φ ′ ( λ ) \varphi'(\lambda) φ′(λ),又因为 f ( x ) = 1 2 x T A x + b T x + c = > f ′ ( x ) = A x + b f(x) = \frac{1}{2}x^TAx+b^Tx + c=>f'(x)=Ax+b f(x)=21?xTAx+bTx+c=>f′(x)=Ax+b则:
f ′ ( x ( k + 1 ) ) T d ( k ) = 0 = > ( A x ( k + 1 ) + b ) T d ( k ) = 0 = > [ A ( x ( k ) + λ ( k ) d ( k ) ) + b ] T d ( k ) = 0 = > [ ( A x ( k ) + b ) + λ ( k ) A d ( k ) ] T d ( k ) = 0 = > [ f ′ ( x ( k ) ) + λ ( k ) A d ( k ) ] T d ( k ) = 0 = > λ ( k ) = ? ( f ′ ( x ( k ) ) ) T d ( k ) ( d ( k ) ) T A d ( k ) \begin{aligned} &f'(x^{(k+1)})^Td^{(k)}=0 \\ &=>(Ax^{(k+1)}+b)^Td^{(k)} =0 \\ &=>[A(x^{(k)} + \lambda^{(k)}d^{(k)})+b]^Td^{(k)} =0 \\ &=>[(Ax^{(k)}+b) + \lambda^{(k)}Ad^{(k)}]^Td^{(k)}=0\\ &=>[f'(x^{(k)}) + \lambda^{(k)}Ad^{(k)}]^Td^{(k)}=0\\ &=>\lambda^{(k)} = - \frac{(f'(x^{(k)}))^Td^{(k)}}{(d^{(k)})^TAd^{(k)}} \end{aligned} ?f′(x(k+1))Td(k)=0=>(Ax(k+1)+b)Td(k)=0=>[A(x(k)+λ(k)d(k))+b]Td(k)=0=>[(Ax(k)+b)+λ(k)Ad(k)]Td(k)=0=>[f′(x(k))+λ(k)Ad(k)]Td(k)=0=>λ(k)=?(d(k))TAd(k)(f′(x(k)))Td(k)??
4、如何迭代求搜索方向?
我们已经找到了更新步长 λ ( k ) \lambda^{(k)} λ(k),但是我们还需要确定更新方向 d ( k + 1 ) d^{(k+1)} d(k+1), d ( k + 1 ) d^{(k+1)} d(k+1)为负梯度方向和搜索方向的线性组合,表示为:
d ( k + 1 ) = ? f ′ ( x ( k + 1 ) ) + β ( k + 1 ) d ( k ) \begin{aligned} d^{(k+1)} = - f'(x^{(k+1)}) + \beta^{(k+1)}d^{(k)} \end{aligned} d(k+1)=?f′(x(k+1))+β(k+1)d(k)?
下面我们需要求解这个\beta^{(k)},上式左右两边同乘 ( d ( k ) ) T A (d^{(k)})^TA (d(k))TA,可得:
( d ( k ) ) T A d ( k + 1 ) = ? ( d ( k ) ) T A f ′ ( x ( k + 1 ) ) + ( d ( k ) ) T A β ( k + 1 ) d ( k ) = 0 = > β ( k + 1 ) = ? ( d ( k ) ) T A f ′ ( x ( k + 1 ) ) ( d ( k ) ) T A d ( k ) \begin{aligned} &(d^{(k)})^TAd^{(k+1)} = - (d^{(k)})^TAf'(x^{(k+1)}) + (d^{(k)})^TA\beta^{(k+1)}d^{(k)} = 0 \\ &=>\beta^{(k+1)} = -\frac{(d^{(k)})^TAf'(x^{(k+1)})}{(d^{(k)})^TAd^{(k)} } \end{aligned} ?(d(k))TAd(k+1)=?(d(k))TAf′(x(k+1))+(d(k))TAβ(k+1)d(k)=0=>β(k+1)=?(d(k))TAd(k)(d(k))TAf′(x(k+1))??
知道 β ( k ) \beta^{(k)} β(k)之后,我们可以求出 d ( k + 1 ) d^{(k+1)} d(k+1),从 x ( k + 1 ) x^{(k+1)} x(k+1)沿着 d ( k + 1 ) d^{(k+1)} d(k+1)方向搜索即可。
注: 这里有点容易混淆的内容是: d ( k + 1 ) d^{(k+1)} d(k+1)是基于当前点的负梯度和 d ( k ) d^{(k)} d(k)而得, d d d表示搜索方向(也是共轭向量)。
5、算法过程
给定初始解 x ( 0 ) x^{(0)} x(0)
令 λ ( 0 ) = A x ( 0 ) + b \lambda^{(0)}=Ax^{(0)}+b λ(0)=Ax(0)+b, d ( 0 ) = ? f ′ ( x ( 0 ) ) d^{(0)}=-f'(x^{(0)}) d(0)=?f′(x(0)), k = 0 k=0 k=0
while ? f ′ ( x ( k ) ) ≠ 0 -f'(x^{(k)}) \neq 0 ?f′(x(k))??=0
λ ( k ) = ? ( f ′ ( x ( k ) ) ) T d ( k ) ( d ( k ) ) T A d ( k ) \lambda^{(k)} = - \frac{(f'(x^{(k)}))^Td^{(k)}}{(d^{(k)})^TAd^{(k)}} λ(k)=?(d(k))TAd(k)(f′(x(k)))Td(k)?
x ( k + 1 ) = x ( k ) + λ ( k ) d ( k ) x^{(k+1)} = x^{(k)} + \lambda^{(k)}d^{(k)} x(k+1)=x(k)+λ(k)d(k)
f ′ ( x ( k + 1 ) ) = A x ( k + 1 ) + b f'(x^{(k+1)})=Ax^{(k+1)}+b f′(x(k+1))=Ax(k+1)+b
β ( k + 1 ) = ? ( d ( k ) ) T A f ′ ( x ( k + 1 ) ) ( d ( k ) ) T A d ( k ) \beta^{(k+1)} = -\frac{(d^{(k)})^TAf'(x^{(k+1)})}{(d^{(k)})^TAd^{(k)} } β(k+1)=?(d(k))TAd(k)(d(k))TAf′(x(k+1))?
d ( k + 1 ) = ? f ′ ( x ( k + 1 ) ) + β ( k + 1 ) d ( k ) d^{(k+1)} = - f'(x^{(k+1)}) + \beta^{(k+1)}d^{(k)} d(k+1)=?f′(x(k+1))+β(k+1)d(k)
k = k + 1 k=k+1 k=k+1
end(while)
但是在实际中,为了提高效率,一般使用下列更新公式:
λ ( k ) = ? ( f ′ ( x ( k ) ) ) T f ′ ( x ( k ) ) ( d ( k ) ) T A d ( k ) , β ( k + 1 ) = ? ( f ′ ( x ( k + 1 ) ) ) T f ′ ( x ( k + 1 ) ) ( f ′ ( x ( k ) ) ) T A f ′ ( x ( k ) ) \lambda^{(k)} = - \frac{(f'(x^{(k)}))^Tf'(x^{(k)})}{(d^{(k)})^TAd^{(k)}}, \beta^{(k+1)} = -\frac{(f'(x^{(k+1)}))^Tf'(x^{(k+1)})}{(f'(x^{(k)}))^TAf'(x^{(k)}) } λ(k)=?(d(k))TAd(k)(f′(x(k)))Tf′(x(k))?,β(k+1)=?(f′(x(k)))TAf′(x(k))(f′(x(k+1)))Tf′(x(k+1))?
6、优缺点
- 克服了最速下降法收敛慢的缺点
- 避免了牛顿法需要存储计算海瑟矩阵并求逆矩阵的缺点
- 所需存储量小,可快速收敛,稳定性高,不需要参数,可避免梯度下降的“锯齿”现象。
六、总结
- 上述几种方法,除了最小二乘法是直接使用公式取得之外,另外几种方法都是使用迭代法进行求解。
- 梯度下降法主要沿着负梯度方向进行更新,只引入了一阶导数。
- 牛顿法则将一阶导数和二阶导数相结合进行参数的迭代更新,但是其二阶导数矩阵涉及到海瑟矩阵求逆,复杂度较高,因此基于牛顿法之上,出现了拟牛顿法,其主要思想是构造一个新的矩阵来近似替代海瑟矩阵的逆,这样可以避免牛顿法中的复杂的海瑟矩阵求逆操作。
- 本质上来说,牛顿法是二阶收敛,而梯度下降是一阶收敛,所以牛顿法收敛更快,但是每次迭代的时间,牛顿法比梯度下降时间长。牛顿法就是用一个二次曲面去拟合你当前所处位置的局部曲面,而梯度下降法使用一个平面去拟合当前的局部曲面,所有牛顿法的下降路径会更简单,更符合最优路径。
- 共轭梯度法基于梯度下降中的负梯度方向之外,引入了共轭向量,可以使收敛更快。
- 牛顿法是二阶优化方法,拟牛顿法和共轭梯度法一般叫做1.5阶优化方法,梯度下降法及其变形则是一阶优化方法。
参考文章:
[1] 批量梯度下降(BGD)、随机梯度下降(SGD)以及小批量梯度下降(MBGD)的理解
[2] 梯度下降(Gradient Descent)小结
[3] 常见的几种最优化方法(梯度下降法、牛顿法、拟牛顿法、共轭梯度法等)
[4] 牛顿法-维基百科
[5] 梯度下降法和共轭梯度法有何异同?
[6] 共轭梯度法计算回归
[7] 共轭梯度法(Conjugate Gradient Method)
[8] Second Order Optimization Algorithms I