本篇主要整理下激活函数的相关内容。
首先讲下激活函数需要满足的条件:
- 计算简单
- 非线性
为什么需要满足非线性呢?我们来看下面这个例子。
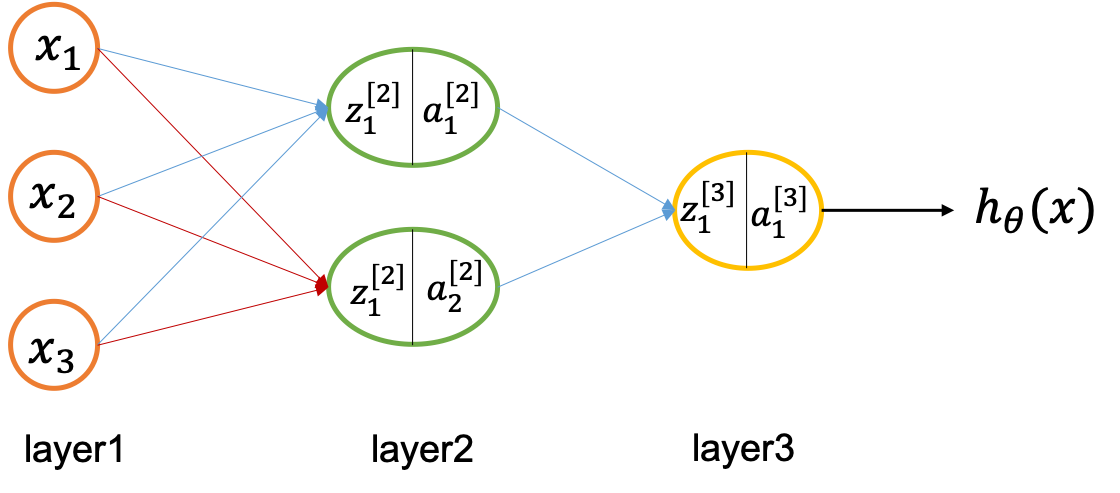
如图单隐层神经网络,我们在计算的时候有如下公式:
z 1 [ 2 ] = w [ 1 ] x + b [ 1 ] a 1 [ 2 ] = g [ 1 ] ( z 1 [ 2 ] ) \begin{aligned} z_1^{[2]} &= w^{[1]}x+b^{[1]} \\ a_1^{[2]} &= g^{[1]}(z_1^{[2]}) \end{aligned} z1[2]?a1[2]??=w[1]x+b[1]=g[1](z1[2]?)?
其中, g g g表示激活函数,假设激活函数是线性函数,其表达式为: g ( x ) = w x + b g(x)=wx+b g(x)=wx+b,则
a 1 [ 2 ] = g [ 1 ] ( z 1 [ 2 ] ) = w z 1 [ 2 ] + b = w ( w [ 1 ] x + b [ 1 ] ) + b = w w [ 1 ] x + w b [ 1 ] + b \begin{aligned} a_1^{[2]} &= g^{[1]}(z_1^{[2]}) \\ &=wz_1^{[2]}+b \\ &=w(w^{[1]}x+b^{[1]} )+b \\ &=ww^{[1]}x+wb^{[1]}+b \end{aligned} a1[2]??=g[1](z1[2]?)=wz1[2]?+b=w(w[1]x+b[1])+b=ww[1]x+wb[1]+b?
我们令 w ′ = w w [ 1 ] w'=ww^{[1]} w′=ww[1], b ′ = w b [ 1 ] + b b'=wb^{[1]}+b b′=wb[1]+b,则 a 1 [ 2 ] = w ′ x + b ′ a_1^{[2]}=w'x+b' a1[2]?=w′x+b′,这和没有经过激活函数处理的结果一样,因此如果激活函数是线性的,则无论有多少隐层,其和具有线性激活函数的单隐层网络效果一样。因此,为了得到更好的效果,我们需要激活函数是非线性的。一般而言,线性激活函数只有的输出层才使用,比如,你需要预测一个回归问题,线性激活函数可以将结果映射为实数。
下面介绍几种常用的激活函数:
1、sigmoid
sigmoid函数也成logistic函数,其公式为:
σ ( x ) = 1 1 + e x p ( ? x ) \begin{aligned} \sigma(x)=\frac{1}{1+exp(-x)} \end{aligned} σ(x)=1+exp(?x)1??
下图是sigmoid函数对应的图像(图片来源):
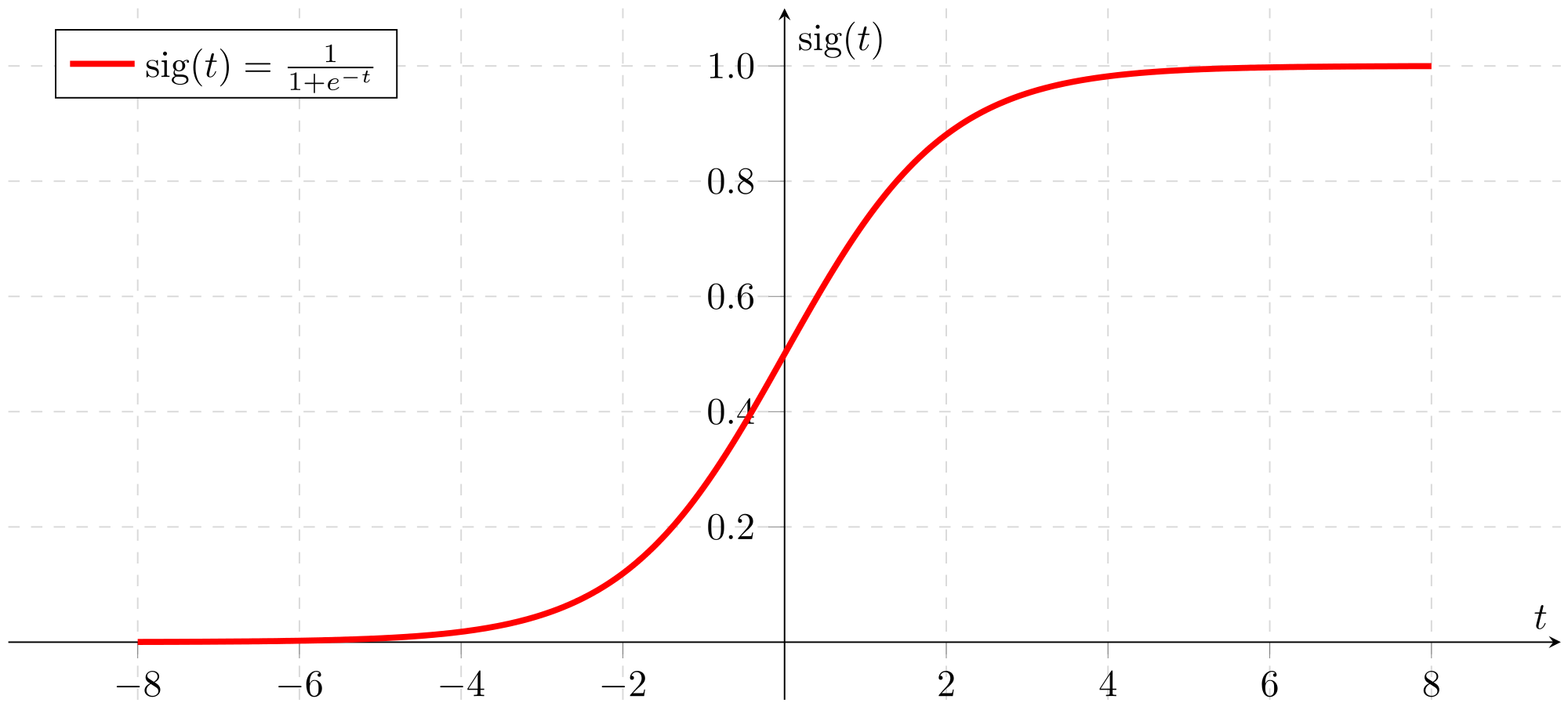
从上图可以看出,sigmoid函数的性质如下:
- 关于 ( 0 , 0.5 ) (0, 0.5) (0,0.5)中心对称,其值全部大于0
- sigmoid可以将实数域的值映射到 ( 0 , 1 ) (0, 1) (0,1)之间,赋予了概率的意义。
- 在sigmoid函数值 x > 5 x>5 x>5或者 x < ? 5 x<-5 x<?5的区域,出现了饱和区域,函数值几乎平稳不变。
上述性质便带来了以下问题:
- 一般而言,我们期望神经网络内数值的期望为0,方差为1(lecun的论文有说明这种情况下效果最好),但是很明显sigmoid函数的期望大于0。
- sigmoid函数存在的一个非常大的弊端便是它的饱和性,在函数值 x > 5 x>5 x>5或者 x < ? 5 x<-5 x<?5的区域,sigmoid值几乎不变,也就是说梯度几乎为0,这会导致在反向传播过程中导数处于该区域的误差很难甚至无法被传递到前层(因为在梯度传递过程中,有乘以 σ ′ ( x ) \sigma'(x) σ′(x)这一项),梯度消失,进而导致整个网络无法正常训练。这种现象叫做“梯度饱和”,也称为“梯度消失”。
因此,基于sigmoid函数的缺陷提出了tanh(x)激活函数。
2、tanh
tanh的公式如下:
σ ( x ) = 2 s i g m o i d ( 2 x ) ? 1 = 2 ? 1 1 + e x p ( ? 2 x ) ? 1 = 1 ? e x p ( ? 2 x ) 1 + e x p ( ? 2 x ) = e x p ( x ) ? e x p ( ? x ) e x p ( x ) + e x p ( ? x ) \begin{aligned} \sigma(x)&=2sigmoid(2x)-1 \\ &=2 \cdot \frac{1}{1+exp(-2x)} - 1\\ &=\frac{1-exp(-2x)}{1+exp(-2x)} \\ &=\frac{exp(x)-exp(-x)}{exp(x)+exp(-x)} \end{aligned} σ(x)?=2sigmoid(2x)?1=2?1+exp(?2x)1??1=1+exp(?2x)1?exp(?2x)?=exp(x)+exp(?x)exp(x)?exp(?x)??
其函数图如下所示(图片来源):
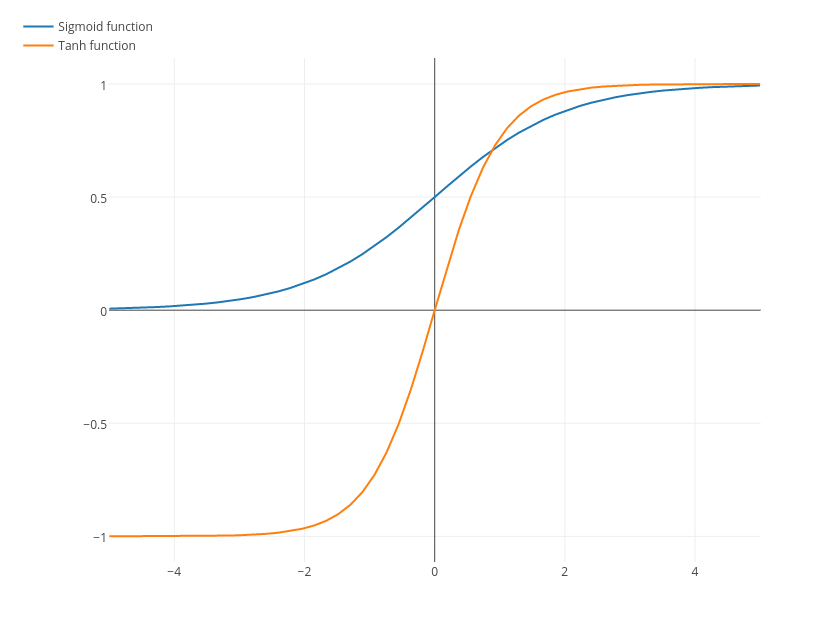
从图中可以看出,tanh函数以 ( 0 , 0 ) (0,0) (0,0)为中心点,这在一定程度上缓解了sigmoid函数带来的“均值不为0”的问题,但是仍然存在“梯度饱和”的现象。
3、ReLU
为了避免梯度饱和现象的发生,修正线性单元(Rectified Linear Unit, ReLU)被提出。ReLU是一个分段函数,其公式如下:
σ ( x ) = m a x { 0 , x } = { x , x ≥ 0 0 , x < 0 \begin{aligned} \sigma(x)&=max\{0, x\} \\ &= \left\{\begin{matrix} x,&x\geq 0\\ 0,&x< 0 \end{matrix}\right. \end{aligned} σ(x)?=max{
0,x}={
x,0,?x≥0x<0??
我们可以看到,在 x ≥ 0 x\geq 0 x≥0时,梯度为1,这部分解决了sigmoid函数和tanh函数梯度饱和的问题,同时,也加速了训练过程,除此之外,ReLU的计算比较简单。但是ReLU存在的一个问题是当 x < 0 x< 0 x<0时,梯度为0,这部分叫做“死区”现象。
4、Leaky ReLU
为了缓解“死区”现象,Leaky ReLU尝试将ReLU的 x < 0 x< 0 x<0部分调整成一个斜率很小的值,其公式如下:
σ ( x ) = { x , x ≥ 0 α ? x , x < 0 \begin{aligned} \sigma(x)=\left\{\begin{matrix} x,&x\geq 0\\ \alpha \cdot x,&x< 0 \end{matrix}\right. \end{aligned} σ(x)={
x,α?x,?x≥0x<0??
α \alpha α是一个很小的正数,这个超参数需要设置并且比较敏感,因此出现了参数化ReLU和随机化ReLU,这些都是ReLU的变体,这里不再细说。
5、ELU
指数化线性单元(Exponential Linear Unit, ELU)的公式如下:
σ ( x ) = { x , x ≥ 0 λ ? ( e x p ( x ) ? 1 ) , x < 0 \begin{aligned} \sigma(x) = \left\{\begin{matrix} x,&x\geq 0\\ \lambda \cdot (exp(x)-1),&x< 0 \end{matrix}\right. \end{aligned} σ(x)={
x,λ?(exp(x)?1),?x≥0x<0??
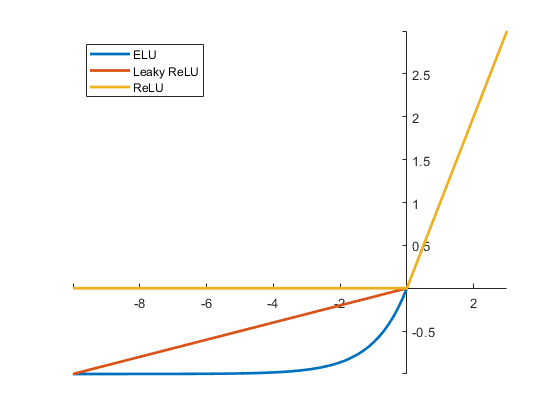
如图所示(图片来源),ELU除了解决ReLU中的“死区”现象,但是其计算量较大。
6、总结
深度网络模型强大的表示能力大部分是由激活函数的非线性带来的。一般而言,在输出层使用线性激活函数,其他隐层使用非线性激活函数,在实际中,ReLU激活函数的使用更频繁。