文章目录
- 前言
- Overview
- Model Architecture
-
- HYBRID REPRESENTATION OF CODE
- Hybrid Attention
- Text Generation
- Critic Network
- Model Training
前言
这篇论文利用了AST的信息,结合高级RL进行代码描述的生成。果然这个工作不是没人填啊,但事物总有两面性,虽然一方面没机会做首个工作了,但另一方面,可以利用一下作者的代码,虽然pytorch 0.2实在有点老,在pytorch 1.0下也没跑通,但有比没有好吧,做人要知足。
论文地址:https://dl.acm.org/citation.cfm?id=3238206
代码地址:https://github.com/wanyao1992/code_summarization_public
Overview
成功的代码概括生成不仅有利于源代码的维护,还能提高自然语言搜索代码、以及代码分类的表现。优秀的代码注解应该正确、流畅、并遵循一个标准格式。
大多数的代码概括方法基于统计学语言模型学习源代码的语义表示,基于模板或规则生成注释。encoder-decoder框架下的模型,典型地被训练在之前的words和ground-truth已给的假设下,最大化下一个word的似然性。
这些方法在两个方面受限,一是代码的序列与结构信息没有被充分利用在特征表示上,结构信息的利用可以大大提高代码表示的效率,因为代码大多具有相似的结构,比如循环、条件判断等。二是由于在测试时没有ground-truth,即目标word,训练时之前的word是样本里的,测试时是完全自己生成的,所以之前word的质量不能保证了,错误就有可能累加,就造成了exposure bias。
我的这篇文章台湾NTU李宏毅的Machine Learning (2017,Fall),部分要点总结3:Auto-encoder,GAN,seq2seq相关,RNN等里面有讲这个,并介绍了诸如scheduled sampling这样的方法来缓解这样的问题。
文章利用两个LSTM来分别encode AST与代码的序列内容,对LSTM进行的调整,称为AST-based LSTM。然后用hybrid attention layer混合两者,通过rnn的方式生成注释。利用actor-critic解决exposure bias。当然要pretrain actor和critic。actor通过loss为cross entropy的监督学习pretrain,critic通过loss为mean square pretrain。
Model Architecture

HYBRID REPRESENTATION OF CODE
comment总是从源代码中提取,比如函数名等,论文使用LSTM处理代码的序列信息,即词汇层面的信息。
句法层面,通过AST embedding方面表示。作者提出了AST-based LSTM

AST-based LSTM有多个forget gate,j代表node,l代表l-th child,k=1,2,3,…,N,N是child的数量,h代表hidden state,c代表memory,i代表input gate,f代表forget gate,o代表output gate,u代表更新memory cell的state,x是某个node的word embedding,σ是logistic即sigmoid函数,点乘是vector按元素的相乘

上图是tree-rnn的结构,为了简化,作者将AST转换为二叉树,否则每个node 的child数目不确定。具体方法是:
- 如果节点有多个child,除了最左边的child,其余child成为新的右child的child。自上而下重复直到每个node的child都不超过2个。
- 将只有一个child的node与其child结合
可以看出,跟左儿子右兄弟表示法是完全不一样的。
Hybrid Attention
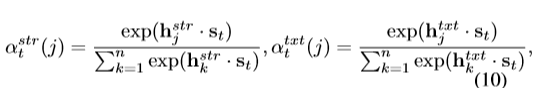
两个attention score,str代表structural representation,txt代表sequential representation,t代表decode过程的step t,j依然是node,n是code token的个数,h.s是inner project,st是源码片段加直到t得到的word:y0,y1,…,yt,st+1={st,yt+1}。
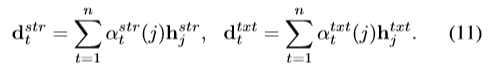
d是按权重相加的hidden state 的和,通过一层线性network将两个d合并为一个d
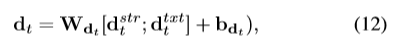
然后通过额外的隐藏层预测t+1个word
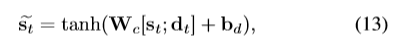
Text Generation
我觉得这里应该是yt+1,
根据上面的定义,st={st-1,yt},
我觉得这里有点问题。
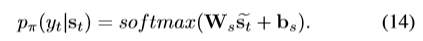
Critic Network
在每个decoding step输出一个scalar。
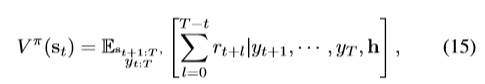
h是代码片段的表示,值函数是未来reward累加和的期望。
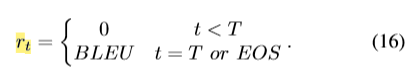
最小化loss
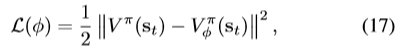
Model Training
使用policy gradient,actor最小化负的期望reward,model的总loss是:

关于actor参数的梯度为:
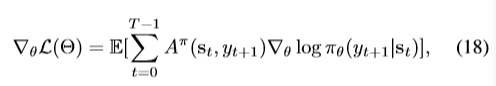
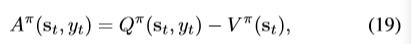
这里应该也是yt+1吧。
关于critic的参数梯度为:
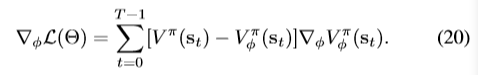
SGD+adagrad
