����Ŀ¼
- ǰ��
- Classic Exploration Strategies
- Key Exploration Problems
-
- The Hard-Exploration Problem
- The Noisy-TV Problem
- Q-Value Exploration
- Variational Options
ǰ��
̽��-����������RL�еĹؼ����⣬ִ��Ŀ�����ʹ�����ǿ���ֱ�Ӽ���Ŀ����Ե�״ֵ̬������ǰ���Բ�һ����ȫ�����ţ������Ҫ̽������ֲ����ţ�������������ѵ��ʱ�䡣����Ϊ�ٴ��������ǵ����ķ��룬ּ�ڽ�ȫ���˽�����Щ̽����ʽ�������Ǹ��ڱ�����˽⡣˳���Ƽ�һ��������ߣ����������ܸߡ�
Exploration Strategies in Deep Reinforcement Learning
Classic Exploration Strategies
�������ڶ���ϻ�����tabular RL��Ч��������̽��������
- Epsilon-greedy����?\epsilon?�ĸ��ʽ������̽����1??1-\epsilon1??�ĸ���ִ�����Ų��ԡ���Ϊһ�־��䷽����annealing epsilon-greedy��DRL��Ҳ�й㷺��Ӧ�á�
- Upper confidence bounds��ѡ������������Ž�Q^t(a)+U^t(a)\hat{Q}_t(a)+\hat{U}_t(a)Q^?t?(a)+U^t?(a)������Q^t(a)\hat{Q}_t(a)Q^?t?(a)�ǽ���ʱ��ttt������aaa��ƽ�����ͣ�U^t(a)\hat{U}_t(a)U^t?(a)��һ��������aaa��ִ�д����ĺ�������˸ò��Ի�����ѡ��ִ�д����١���Qֵ��Ķ�����Ҳ����˵��������ƺ��ܺã�����Ϊִ�д�����������Ҫ���ִ�еõ�ȷ��Qֵ��ȷ��������ĺá�����ϸ�ڿɲο����
- Boltzmann exploration������ boltzmann distribution (softmax) ����������ÿ�������ĸ���ΪeQt(a)�ӡ�b=1neQt(b)��\frac{e^{\frac{Q_t(a)}{\tau}}}{\sum_{b=1}^{n}e^{\frac{Q_t(b)}{\tau}}}��b=1n?e��Qt?(b)?e��Qt?(a)??������ͨ���¶Ȳ�����>0\tau>0��>0���ơ����������������������̰�ġ�
- Thompson sampling��agent���ٶ�����ж��Ŀ����Ե�������Ӹ÷ֲ��в��������ȶ���ÿ��������Beta�ֲ�Beta(��,��)Beta(\alpha,\beta)Beta(��,��)����\alpha�������ɹ��õ����͵Ĵ�������\beta������ʧ�ܵĴ���������ij�������ʼ�����ߡ���ʱ�䲽ttt�����Ƕ���ÿ���������������������ͣ�ѡ�������������Ķ������õ����ͺ��±�ѡ�����IJ�������+=rt,��+=(1?rt)\alpha+=r_t,\beta+=(1-r_t)��+=rt?,��+=(1?rt?)��������Probability matching�����ݹ۲��ƶϸ��ʣ��ø���ƥ��۲죬���˽����ɲο������
����IJ��Կ�����DRL���и��õ�̽����
- Entropy loss term������ʧ����������һ�����Ե��أ�����ִ�в�ͬ�Ķ���
- Noise-based Exploration���ڹ۲졢�������������ռ���������(Fortunato, et al. 2017, Plappert, et al. 2017)
Key Exploration Problems
����������ϡ�轱����̽������������ѡ�
The Hard-Exploration Problem
��hard-exploration��������ָ�ڽ����dz�ϡ������������ƭ�ԵĻ����н���̽����������ѣ���Ϊ����������½������̽�����ٻᷢ�ֳɹ�״̬����������ķ���������Montezuma��s Revenge��
The Noisy-TV Problem
��Noisy-TV������ʼ��Burda���ˣ�2018�꣩��˼��ʵ�顣����agentͨ��Ѱ������ľ����ý��ͣ���ô���в��ɿغͲ���Ԥ��������������ĵ��ӽ��ܹ���Զ����agent��ע������agentʼ�մ����ӵĵ����л���µĽ�������δ��ȡ���κ�������Ľ�������˳�Ϊ��couch potato����
ʾ����ͼ
Q-Value Exploration
�� Thompson sampling ��������Bootstrapped DQN(Osband, et al. 2016)ͨ��ʹ���Ծٷ��������˾���DQN��Qֵ���ƵIJ�ȷ���Ը���Ծٷ���ͨ����δ���ͬ�����н����зŻز�����Ȼ����ܽ�������Ʒֲ���
���Qֵͷ����ѵ������ÿ��ͷ������һ���Ծ��Ӳ������ݼ���ÿ����ͷ�����Լ��Ķ�ӦĿ�����硣����Qֵͷ������ͬһ�Ǹ�����


��һ��episode��ʼʱ�������Ȳ���һ��Qֵͷ��Ȼ�������episode��ִ���ռ��������ݡ�Ȼ�������ֲ�m?Mm\sim Mm?M�в���һ�����������룬��ȷ����Щͷ����ʹ�ø����ݽ���ѵ��������ֲ�MMM��ѡ��������������bootstrapped���������磺
- ���MMM��p=0.5p = 0.5p=0.5�Ķ�����Ŭ���ֲ���������Ӧ��double-or-nothing bootstrap��
- ���MMM���Ƿ���ȫһ���룬����㷨����Ϊ���ɷ��� ��
���ǣ�����̽����Ȼ�ܵ����ƣ���Ϊ�Ծ�����IJ�ȷ������ȫ������ѵ�����ݡ����ע��һЩ���������ݵ�������Ϣ���������֡����ӡ������齫��ʹagent�ڽ���ϡ���ʱ�����̽������bootstrapped DQN��������������Խ��и���̽�����㷨��Osband, et al. 2018���ǻ��ڱ�Ҷ˹���Իع顣��Ҷ˹�ع�ĺ���˼���ǣ������ǿ���ͨ�������ݵ����Ӱ汾��ѵ����������һЩ������������ɺ����������� ʹ��ͳ��ѧ��bootstrap�����Ǹ�˹������ʵ��״̬��صı仯��

��f��f_\thetaf��?Ϊ������Q������f��?f_{\theta^-}f��??Ϊ������Ŀ��Q������ʹ��������麯��ppp������DDD����ʧ����Ϊ��
L��(��;��?,p,D):=��t��D(rt,��max?a���A(f��?+p?target Q)(st��,a��)?(f��+p?online Q)(st,at))2\mathcal{L}_{\gamma}(\theta;\theta^-,p,D):=\sum_{t\in D}(r_t,\gamma\max_{a'\in A}(\underbrace{f_{\theta^-}+p}_{\text{target Q}})(s_t',a')-(\underbrace{f_{\theta}+p}_{\text{online Q}})(s_t,a_t))^2L��?(��;��?,p,D):=t��D��?(rt?,��a����Amax?(target Q
f��??+p??)(st��?,a��)?(online Q
f��?+p??)(st?,at?))2
Variational Options
options�Ǿ�����ֹ�����IJ��ԡ������ռ����д�������options��������agent����ͼ�ء�ͨ�����ڲ�options��ȷ�ذ����ڽ�ģ�У�agent���Ի�ȡ�ڲ��Ľ�������̽����
VIC (short for ��Variational Intrinsic Control��; Gregor, et al. 2017)��������һ��ͨ����ģoptions��ѧϰ����options�IJ�������agent�ṩ�ڲ�̽�����͡�����\Omega��������s0s_0s0?��ʼsfs_fsf?������һ��option���������ʷֲ�pJ(sf�Os0,��)p^J(s_f|s_0,\Omega)pJ(sf?�Os0?,��)�����˸�����ʼ״̬s0s_0s0?��option ��\Omega����������ֹ���ɿ����Էֲ�pC(���Os0)p^C(\Omega|s_0)pC(���Os0?)���������ǿ��Դ��в���option�ĸ��ʷֲ�����˿ɵ�p(sf,���Os0)=pJ(sf�Os0,��)PC(���Os0)p(s_f,\Omega|s_0)=p^J(s_f|s_0,\Omega)P^C(\Omega|s_0)p(sf?,���Os0?)=pJ(sf?�Os0?,��)PC(���Os0?)
ѡ��options��ʱ����Ҫʵ������Ŀ�꣺
- ʵ��һ����������ʼ��s0s_0s0?���ս�״̬���ϣ������H(sf�Os0)H(s_f|s_0)H(sf?�Os0?)
- ȷ֪��һ��������\Omega�����ս�״̬������С��H(sf�Os0,��)H(s_f|s_0,\Omega)H(sf?�Os0?,��)
���߽�Ͼ��ܵõ�Ҫ��Ļ���Ϣ��
I(��;sf�Os0)=H(sf�Os0)?H(sf�Os0,��)I(\Omega;s_f|s_0)=H(s_f|s_0)-H(s_f|s_0,\Omega)I(��;sf?�Os0?)=H(sf?�Os0?)?H(sf?�Os0?,��)

�˴�������ʹ���κ�RL�㷨�Ż���(a�O��,s)\pi(a|\Omega,s)��(a�O��,s)��option��������q(���Os0,sf)q(\Omega|s_0,s_f)q(���Os0?,sf?)���мලѧϰ������pCp^CpC������ʹ����������ѡ����нϸ߽�������\Omega������ע�⣬pCp^CpCҲ�����ǹ̶��ģ������˹����ͨ��ѧϰ��������\Omega�����ᵼ�²�ͬ����Ϊ��
DIAYNΪ��Diversity is all you need������д������һ������������û�н��ͺ����������ѧϰ���ü��ܵĿ�ܡ�����ʽ�ؽ�������zzz��ģΪskill embedding����ʹ���Ի���״̬sss��zzz���Ц�(a,�Os,z)\pi_{\theta}(a,|s,z)����?(a,�Os,z)�������һЩ���裺
- ����Ӧ�ö������������²�ͬ״̬�ķ�����\to�����״̬�뼼��֮��Ļ���ϢI(S;Z)I(S;Z)I(S;Z)
- ����Ӧ��ͨ��״̬�����Ƕ�����������\to����״̬Ϊ��������С�������ͼ���֮��Ļ���ϢI(A;Z�OS)I(A; Z�OS)I(A;Z�OS)
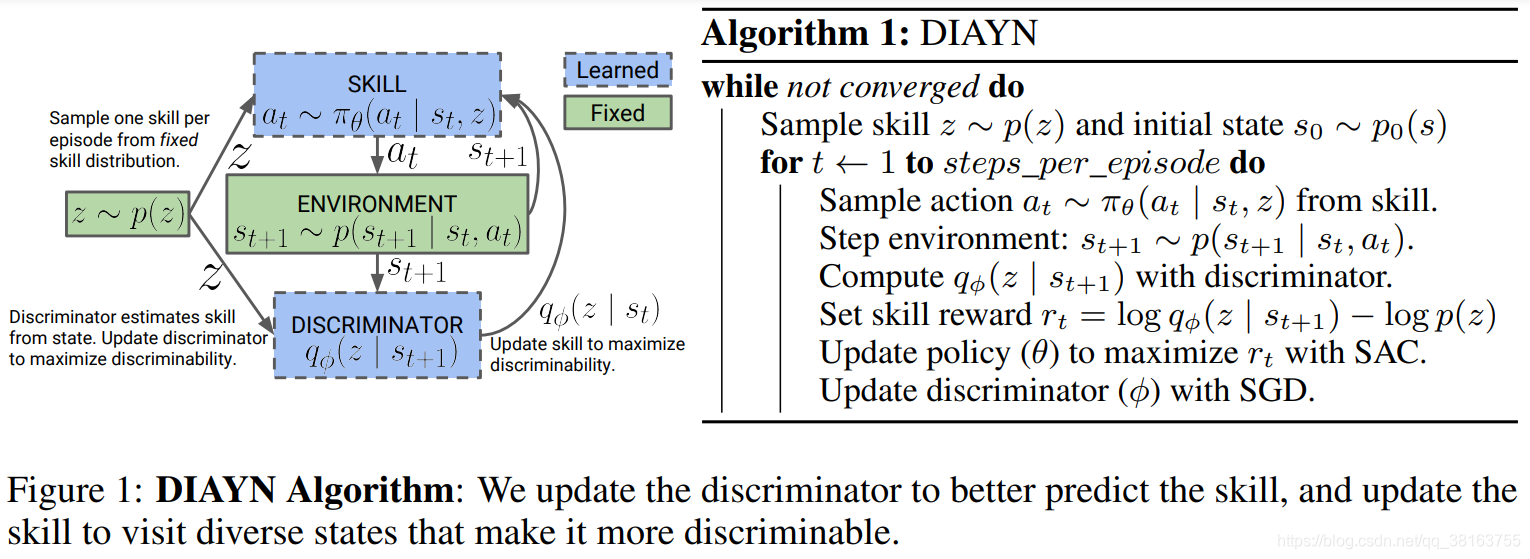
���Ŀ�꺯�������Ӳ����ع��������ԣ�
F(��)=I(S;Z)+H[A�OS]?I(A;Z�OS)\mathcal{F}(\theta)=I(S;Z)+H[A|S]-I(A;Z|S)F(��)=I(S;Z)+H[A�OS]?I(A;Z�OS)
���⣬Gregor, et al. (2017)�۲쵽��ʹ������ʽoption��VIC��ʵ���к������к������Ƶ�����������ã�������ǻ��������һ��������ʽoption��VIC�汾����ͬ��VIC����\Omega����ģΪ�����ڿ�ʼ״̬�ͽ���״̬��VALOR����Variational Auto-encoding Learning of Options by Reinforcement����Achiam, et al. 2018�������������켣����ȡoption������ccc����ӹ̶��ĸ�˹�ֲ��в������� VALOR�У�
- ���Գ䵱���������������Ĵ������ֲ�ת��Ϊ�켣
- ���������Դӹ켣�лָ������ģ�������ʹ�������������ֵIJ��ԡ���������Զ������ѵ�������п������������agent�����뻷�����н������ٽ����������ͨ�ţ���ʵ�ָ��õ�Ԥ�⡣���ң�������ѭ��������һ���켣��step���У��Ը��õؽ�ģʱ�䲽֮�������ԡ�
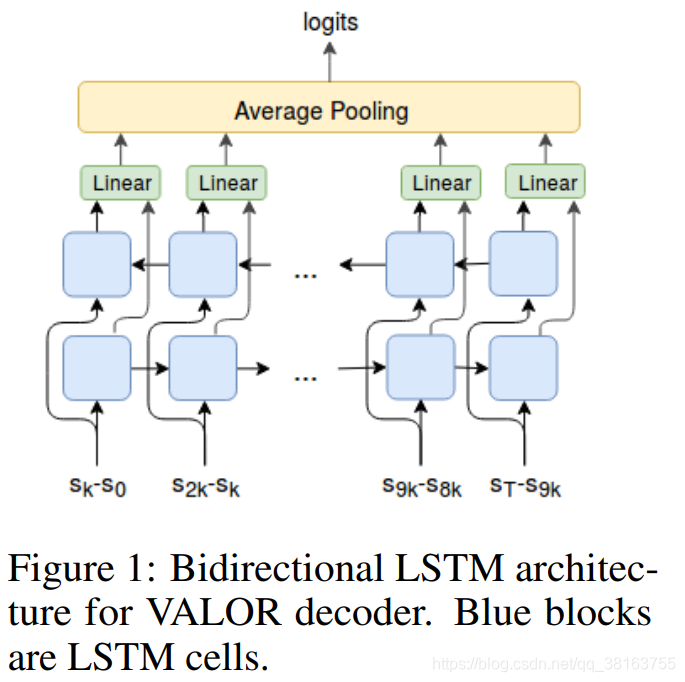
����ʹ��ѭ���Ľ������ṹ��ʵ��VALOR��ʹ��˫��LSTM��ȷ���켣�������յ㶼ͬ����Ҫ�����ǽ�ʹ�����Թ켣��N = 11���Ⱦ�۲���Ϊ���룬ԭ����������1������Ч�ʣ�2������һ������ʽ��Ϣ��������ֻ�Ե�Ƶ��Ϊ����Ȥ������Ϣ�ܼ��ĸ�Ƶ�����෴�������Vezhnevets et al.(2017)����������������N���۲�ֵ֮���״̬�ռ��е�k��transitions��deltas���н��н��롣ֱ���ϣ����Ӧ��agentӦ���ƶ������飬��Ϊ��agent���ڲ�ͬ���Ʊ��־�ֹ���κ�����ģʽ�£������������������ǣ���Ϊdelta��ͬ��Ϊ�㣩��
DIAYN��VIC���Ǵ�״̬���룬�����������켣��