����Ŀ¼
- ǰ��
- Intrinsic Rewards as Exploration Bonuses
-
- Count-based Exploration
-
- Counting by Density Model
- Counting after Hashing
ǰ��
����Exploration Strategies in Deep Reinforcement Learning (1)������
����Exploration Strategies in Deep Reinforcement Learning�ٴ�����
Intrinsic Rewards as Exploration Bonuses
���õؽ���̽���������ǽ�����⣩��һ�ֳ���������ͨ�������bonus�����ӻ����Ľ������Թ������ж����̽������ˣ�������������Ľ�����ѵ������rt=rte+��rtir_t = r^e_t +\beta r^i_trt?=rte?+��rti?��������\beta���ǵ���������̽��֮���ƽ��ij�������
- rter^e_trte?��ʱ��ttt�����Ի������ⲿ������������ͷ�������塣
- rtir^i_trti?��ʱ��t���ڲ�̽��bonus��
�������ڵĽ�����ij�̶ֳ����ܵ�����ѧ�����ڶ�����������Oudeyer��Kaplan, 2008������������ʹ��̽�������Ƕ�ͯ�ɳ���ѧϰ����Ҫ��ʽ�����仰˵��̽���ԻӦ��������˼ά�л�����ڽ������Թ���������Ϊ�����ڵĻر�����������ģ����棬�Թ��ҵ���Ϥ�Լ��������������йء�
��ͬ���뷨����Ӧ����RL�㷨�������¸����У�����bonus��̽�������������·�Ϊ���ࣺ
- ������״̬
- agent���ڻ���֪ʶ������
Count-based Exploration
������ǽ����ڽ�����Ϊʹ���Ǹе����ȵĽ�����������ô������Ҫһ�ַ���������һ��״̬����ӱ�Ļ��Ǿ������ֵġ�һ��ֱ�۵ķ����Ǽ�������ij��״̬�Ĵ�������Ӧ�ط��佱����bonus����agent����Ϊƫ����ٷ��ʵ�״̬�������dz�����״̬�����Ϊ���ڼ�����̽��������
��Nn(s)N_n(s)Nn?(s)Ϊ��������������ú�����¼����s1:ns_{1:n}s1:n?��״̬sss��ʵ�ʷ��ʴ��������ҵ��ǣ�ֱ��ʹ��Nn(s)N_n(s)Nn?(s)����̽���Dz���ʵ�ʵģ���Ϊ�����״̬��Nn(s)=0N_n(s)=0Nn?(s)=0�������ǿ��ǵ�״̬�ռ�ͨ���������Ļ��ά�ġ� ���ڴ����״̬����ʹ��ǰ��δ���������Ƕ���Ҫһ�����������
Counting by Density Model
Bellemare, et al. (2016)ʹ���ܶ�ģ��������״̬���ʵ�Ƶ�ʣ���ʹ��һ����ӱ���㷨�Ӹ��ܶ�ģ���еó�α���������ȶ���״̬�ռ��ϵ�����������n=��(s�Os1:n)\rho_n=\rho(s|s_{1:n})��n?=��(s�Os1:n?)��Ϊ��ǰn��״̬Ϊs1:ns_{1:n}s1:n?������£���(n + 1)��״̬Ϊsss�ĸ��ʡ�Ϊ��ʵ���Ϻ����������ǿ��Լ�ʹ��Nn(s)n\frac{N_n(s)}{n}nNn?(s)?��
�����ǻ���״̬s�� recoding probability ����Ϊ�ܶ�ģ�۲쵽�³��ֵ�s֮������s�ĸ��ʣ���n��(s)=��(s�Os1:ns)\rho^��_n(s)=\rho(s | s_{1:n}s)��n��?(s)=��(s�Os1:n?s)��
���½��������������Ը��õص����ܶ�ģ�ͣ�α��������N^n(s)\hat{N}_n(s)N^n?(s)��α������n^\hat{n}n^����������ּ��ģ�¾��������������������У�
��n(s)=N^(s)n^�ܦѡ�(s)=N^(s)+1n^+1\rho_n(s)=\frac{\hat{N}(s)}{\hat{n}}\leq\rho'(s)=\frac{\hat{N}(s)+1}{\hat{n}+1}��n?(s)=n^N^(s)?������(s)=n^+1N^(s)+1?
��n(s)\rho_n(s)��n?(s)����n��(s)\rho'_n(s)��n��?(s)֮��Ĺ�ϵҪ���ܶ�ģ��learning-positive���������е�s1:n��Sns_{1:n}\in S^ns1:n?��Sn�Լ����е�s��Ss\in Ss��S��������n(s)�ܦ�n��(s)\rho_n(s)\leq \rho'_n(s)��n?(s)����n��?(s)�����仰˵���۲쵽һ��sssʵ�����ܶ�ģ�Ͷ������sss��Ԥ��Ӧ�����ӡ�����learning-positive���ܶ�ģ��Ӧ����ȫ����ѵ����ʹ�÷�����ľ���״̬��minibatches�������Ȼ����������n��(s)=��n+1\rho'_n(s)=\rho_{n+1}��n��?(s)=��n+1?��
α��������ͨ�������Է��̵õ���
N^n(s)=n^��n(s)=��n(s)(1?��n��(s))��n��(s)?��n(s)\hat{N}_n(s)=\hat{n}\rho_n(s)=\frac{\rho_n(s)(1-\rho'_n(s))}{\rho'_n(s)-\rho_n(s)}N^n?(s)=n^��n?(s)=��n��?(s)?��n?(s)��n?(s)(1?��n��?(s))?
����ͨ��prediction gain(PG)���ƣ�
N^n(s)��(ePGn(s)?1)?1=(elog?��n��(s)?log?��n(s)?1)?1\hat{N}_n(s)\approx(e^{PG_n(s)}-1)^{-1}=(e^{\log \rho'_n(s)-\log \rho_n(s)}-1)^{-1}N^n?(s)��(ePGn?(s)?1)?1=(elog��n��?(s)?log��n?(s)?1)?1
ͨ��count-based������bonusΪ��rti=N(st,at)?12r_t^i=N(s_t,a_t)^{-\frac{1}{2}}rti?=N(st?,at?)?21?(as in MBIE-EB; Strehl & Littman, 2008)��pseudo-count-based̽�������Ƶģ�rti=(N^(st,at)+0.01)?12r_t^i=(\hat{N}(s_t,a_t)+0.01)^{-\frac{1}{2}}rti?=(N^(st?,at?)+0.01)?21?
Bellemare et al., (2016) ��ʵ�������һ���� CTS��Context Tree Switching���ܶ�ģ��������α������CTS ģ�ͽ� 2D ͼ����Ϊ���룬������λ����ص� L ���˲����ij˻�Ϊ�������ʣ�����ÿ���˲�����Ԥ�����ڹ�ȥͼ����ѵ���� CTS �㷨������CTS ģ�ͺܼ����ڱ�������������չ�Ժ�����Ч�ʷ�����ھ����ԡ� �ں��������У�Georg Ostrovski, et al. (2017)ͨ��ѵ�� PixelCNN (van den Oord et al., (2016)) ��Ϊ�ܶ�ģ�Ľ��˸÷�����
�ܶ�ģ��Ҳ������ Zhao & Tresp (2018) �еĸ�˹���ģ�͡�����ʹ�ñ�� GMM �����ƹ켣���ܶȣ����磬һϵ��״̬�Ĵ���������Ԥ����ʣ���ָ��off-policy�����о����طŵ����ȼ���
Counting after Hashing
ʹ������ά״̬��Ϊ���ܵ���һ���뷨�ǽ�״̬ӳ�䵽��ϣ�룬�Ա�״̬�ij��ֱ�ÿ��٣�Tang et al. 2017����״̬�ռ��ù�ϣ����?:S?Zk\phi:S\longmapsto\mathbf{Z}^k?:S?Zk��ɢ���� ̽������ ri:S?R �����ӵ����������У�����Ϊ ri(s)=N(?(s))?1/2������ N(?(s)) �� ? ���ֵľ������ (s)��̽��bonusΪri(s)=N(?(s))?12r^i(s)=N(\phi(s))^{-\frac{1}{2}}ri(s)=N(?(s))?21?������N(?(s))N(\phi(s))N(?(s))��?(s)\phi(s)?(s)���ִ����ļ�����

Tang et al. (2017) ���ʹ�� Locality-Sensitive Hashing (LSH) �������ĸ�ά����ת��Ϊ��ɢ�Ĺ�ϣ�롣LSH ��һ�����еĹ�ϣ���������ڻ���ijЩ�����Զ�����ѯ����ھӡ������ϣ����x?h(x)x\longmapsto h(x)x?h(x)�������ݵ�֮��ľ�����Ϣ��������λ�����еģ������������������ƵĹ�ϣ����Զ�������зdz���ͬ�Ĺ�ϣ��SimHash ��һ�ּ���Ч�ʸߵ� LSH����ͨ���Ǿ���������ԣ�
?(s)=sgn(Ag(s))��{?1,1}k\phi(s)=sgn(Ag(s))\in\{-1,1\}^k?(s)=sgn(Ag(s))��{
?1,1}k
A��Rk��DA\in \mathbf{R}^{k\times D}A��Rk��D��һ������ÿ����Ŀ���Ǵӱ���˹�ж���ͬ�ֲ��ز����õ���g:S?RDg:S\longmapsto \mathbf{R}^Dg:S?RD��һ����ѡ��Ԥ���������������Ʊ����ά����kkk������״̬�ռ���ɢ�����ȣ�kkkԽ������Խ�ߣ���ײԽ�١�
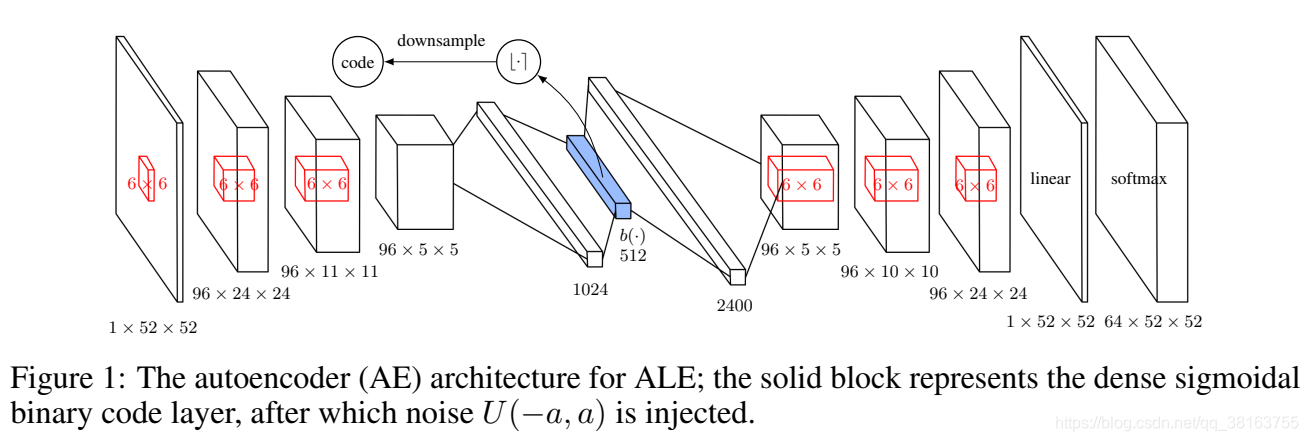

���ڸ�άͼ��SimHash ��ԭʼ���ؼ����Ͽ���Ч�����ѡ�Tang et al. 2017�����һ��autoencoder(AE)����������״̬sss��ѧϰ��ϣ�롣����һ�������ȫ���Ӳ㣬�� k �� sigmoid ���������Ϊ�м��DZ��״̬��Ȼ��ò�� sigmoid ����ֵ b(s)b(s)b(s) ͨ���������뵽��ӽ��Ķ����������ж�ֵ�� ?b(s)?��{0,1}D?b(s)?\in\{0, 1\}^D?b(s)?��{
0,1}D ��Ϊ״̬ sss �Ķ����ƹ�ϣ�롣n ��״̬�� AE ��ʧ�������
L({sn}n=1N)=?1N��n=1Nlog?p(sn)?reconstruction loss+1N��K��n=1N��i=1kmin?{(1?bi(sn))2,bi(sn)2}?sigmoid activation being closer to binary\mathcal{L}(\{s_n\}_{n=1}^N)=\underbrace{-\frac{1}{N}\sum_{n=1}^N\log p(s_n)}_{\text{reconstruction loss}}+\underbrace{\frac{1}{N}\frac{\lambda}{K}\sum_{n=1}^N\sum_{i=1}^k\min\{(1-b_i(s_n))^2,b_i(s_n)^2\}}_{\text{sigmoid activation being closer to binary}}L({
sn?}n=1N?)=reconstruction loss
?N1?n=1��N?logp(sn?)??+sigmoid activation being closer to binary
N1?K��?n=1��N?i=1��k?min{
(1?bi?(sn?))2,bi?(sn?)2}??
p(sn)p(s_n)p(sn?)��AE���������\lambda�������������ġ����������һ�������Dz�ͬ��������ܻ�ӳ�䵽��ͬ�Ĺ�ϣ�룬������ϣ�� AE ��Ȼ�����������ؽ����ǡ����˿������ù�ϣ��?b(s)??b(s)??b(s)?�滻ƿ����b(s)b(s)b(s)�������ݶȲ���ͨ��rounding����������ע������������Լ�������Ӱ�죬��Ϊ AE ����ѧ�ὫDZ�ڱ����Ʒ����Եֿ�������