MobileNet V1
传统卷积神经网络,内存需求大,计算量大,导致无法在移动设备以及嵌入式设备上运行。
在准确率小幅降低的前提下大大减少模型参数和运算量(相比VGG16准确率降低0.9%,但是模型参数只有VGG的1/32)
Mobilenet这篇论文是Google针对手机等嵌入式设备提出的一种轻量级的深层神经网络,取名为MobileNets。个人感觉论文所做工作偏向于模型压缩方面,核心思想就是卷积核的巧妙分解,可以有效减少网络参数。
MobileNet V1引入了深度可分离卷积,作为传统卷积层的有效替代。深度可分卷积通过将空间滤波与特征生成机制分离开来,有效地分解了传统卷积。深度可分离卷积由两个单独的层定义:用于空间滤波的轻量级深度卷积和用于特征生成的1x1点卷积。

α\alphaα:卷积层中的卷积核个数
β\betaβ:控制输入图像大小
这两个超参数是人为设置的,并不是训练得到的
传统卷积的方法

DW卷积(depthwise convolutions)的方法
对每个输入通道(输入深度)应用一个滤波器
 PW卷积(pointwise convolutions)的方法
PW卷积(pointwise convolutions)的方法
(就是普通的卷积,只不过卷积核的大小为1x1)
一个简单的1×1卷积,然后被用来创建一个线性组合的输出的深度层
 深度可分离卷积的方法(DW卷积+PW卷积)
深度可分离卷积的方法(DW卷积+PW卷积)
深度可分离卷积将其分为两层,一层用于过滤(DW卷积),另一层用于合并(PW卷积)。这种分解方法大大减少了计算量和模型尺寸。

传统卷积与深度可分离卷积的计算量对比
输入通道数M,输出通道数N,卷积核大小DKD_KDK?× DKD_KDK?、特征映射(feature map)大小DFD_FDF?× DFD_FDF?
普通卷积计算量为:DKD_KDK? x DKD_KDK? x M x N x DFD_FDF?× DFD_FDF?
深度可分离卷积的计算量:
(1)DW卷积 DKD_KDK? x DKD_KDK? x M x DFD_FDF?× DFD_FDF?------N为1
(2)PW卷积 M x N x DFD_FDF?× DFD_FDF?-----卷积核大小为1*1即DKD_KDK?=1
DW卷积 + PW卷积:DKD_KDK? x DKD_KDK? x M x DFD_FDF?× DFD_FDF?+ M x N x DFD_FDF?× DFD_FDF?


MobileNet V1网络参数
第一行
Conv/s2-----代表普通卷积,卷积的步距为2
Filter Shape 3x3x3x32----3x3代表卷积核的大小,3代表输入特征矩阵的深度,32代表采用的卷积核个数也是输出特征矩阵的深度。
第二行
Conv dw/s2-----代表DW卷积,卷积的步距为1
Filter Shape 3x3(x1)x32 dw----3x3代表卷积核的大小,(隐藏 1 ,因为在DW卷积中,一个输入通道(输入深度)应用一个卷积核,即代表输入特征矩阵的深度为1),32代表采用的卷积核个数也是输出特征矩阵的深度。

######################################################################
α\alphaα---------width multiplier--------卷积层中的卷积核个数
α\alphaα的不同对模型的准确率和计算量的影响,根据实际情况选择合理的参数。
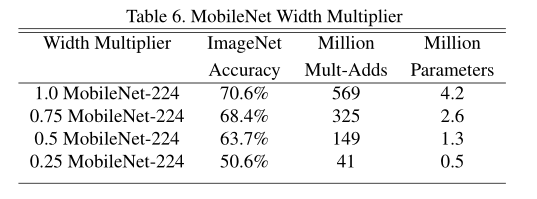
β\betaβ----Resolution Multiplier―控制输入图像大小
β\betaβ的不同对模型的准确率和计算量的影响,根据实际情况选择合理的参数。
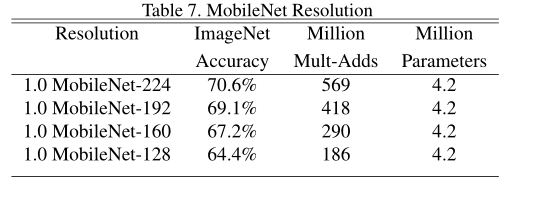
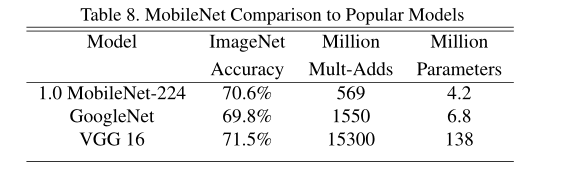
不同模型的性能对比
在V1版本中,DW卷积中的部分容易废掉,即卷积核参数大部分为零,在V2版本中会改善
MobileNet V2
相比于 MobileNet V1网络,准确率更高,模型更小。
MobileNet V2引入了线性瓶颈和反向残留结构,以便通过利用问题的低级别性质来制造更有效的层结构。由一个1x1升维卷积,然后是DW卷积和一个1x1投影层来定义。当且仅当输入和输出具有相同数量的通道时,才使用残差结构连接输入和输出。该结构在输入和输出处保持了一个紧凑的表示,同时扩展到内部的高维特征空间,以增加非线性全通道转换的表现力。
(1)引入了bottleneck结构。
(2)将bottleneck结构变成了纺锤型,即resnet是先缩小为原来的1/4,再放大,他是放大到原来的6倍,再缩小。
(3)并且去掉了Residual Block最后的ReLU。

什么是倒残差结构?
在ResNet中,先通过1x1的卷积进行压缩,再经过3x3的卷积,再经过1x1的升维。
形成**两头(256维)大,中间(64维)小的瓶颈结构**
激活函数采用Relu函数

 在MobileNet V2中,采用倒残差结构,先升维,再卷积,再降维,形成两头小,中间大的结构,称为倒残差结构。
在MobileNet V2中,采用倒残差结构,先升维,再卷积,再降维,形成两头小,中间大的结构,称为倒残差结构。
激活函数采用Relu 6函数
 针对倒残差结构的最后1x1的卷积层,使用线性的激活函数。而不是Relu激活函数,作者在论文中进行实验证明,是因为Relu激活函数对低维特征信息造成大量损失
针对倒残差结构的最后1x1的卷积层,使用线性的激活函数。而不是Relu激活函数,作者在论文中进行实验证明,是因为Relu激活函数对低维特征信息造成大量损失

形成两头小,中间大的结构,称为倒残差结构。
 输入特征矩阵与输出特征矩阵shape相同 是指的C通道 都相同。代码里是stride = 1 and in_channel = out_channel
输入特征矩阵与输出特征矩阵shape相同 是指的C通道 都相同。代码里是stride = 1 and in_channel = out_channel
下表中的S 步距只针对bottleneck的第一层的 ,即第一层步距为2,第二个bottleneck的步距为1

MobileNet V3

与MobileNet V2相比,MobileNet V3-Large在ImageNet分类上提高了3.2%,同时减少了20%的延迟。
MobileNet V3-Small比具有同等延迟的MobileNet V2模型提高了6.6%。
MobileNet V3-Large检测比MobileNet V2在COCO检测上的准确率高25%以上。
MobileNet V3-Large LRASPP比MobileNet V2 R-ASPP在城市景观分割类似精度上快34%。
MobileNet V3论文亮点

(1)Block就是在倒残差的基础上进行简单的改动 ,加入了SE模块,更新了激活函数。
引入SE结构(注意力机制)
在bottlenet结构中加入了SE结构,并且放在了depthwise filter之后,如下图。因为SE结构会消耗一定的时间,所以作者在含有SE的结构中,将expansion layer的channel变为原来的1/4,这样作者发现,即提高了精度,同时还没有增加时间消耗。并且SE结构放在了depthwise之后。
(NL 代表使用非线性激活函数,并不特指)

举个例子,假如我们输入特征矩阵的深度(channel)为2,
全连接层1(FC1)的节点个数是输入特征矩阵深度的1/4,使用Relu激活函数,
全连接层2(FC2)的节点个数与输入特征矩阵的深度一致,使用H-sigmoid激活函数,
然后就得到了有两个元素的一个向量[0.5,0.6],其中每个元素对应每一个channel对应的权重,比如预测的第一个channel的权重为0.5,然后将权重0.5与第一个channel中的所有元素相乘得到新的channel

重新设计耗时层结构
(1)减少第一个卷积层的卷积核个数(32―>16),减少卷积核的个数但是准确率没变,计算量反而会降低,检测速度更快
(2)精简Last Stage
将延迟时间减少了7毫秒,这是运行时间的11%,并将操作数量减少了3000万MAdds,几乎没有损失准确性。

重新设计激活函数
使用h-swish替换swish,swish是谷歌自家的研究成果,颇有点自卖自夸的意思,这次在其基础上,为速度进行了优化。swish与h-swish公式如下所示,由于sigmoid的计算耗时较长,特别是在移动端,这些耗时就会比较明显,所以作者使用ReLU6(x+3)/6来近似替代sigmoid,观察下图可以发现,其实相差不大的。利用ReLU有几点好处,1.可以在任何软硬件平台进行计算,2.量化的时候,它消除了潜在的精度损失,使用h-swish替换swith,在量化模式下回提高大约15%的效率,另外,h-swish在深层网络中更加明显。
swish激活函数----计算求导、复杂,对量化过程不友好
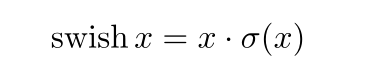
其中
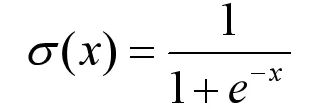
h-swish激活函数
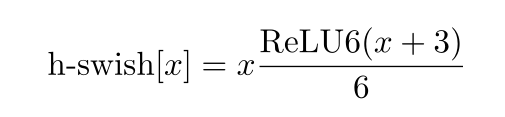
swish激活函数与h-swish激活函数曲线对比

h-sigmoid激活函数

sigmoid激活函数与h-sigmoid激活函数曲线对比

MobileNetV3-Large版本
 NBN是不使用bn层的 SE打钩才使用注意力机制 exp size对应倒残差块刚开始1*1卷积输出的深度 out对应倒残差块最后的深度。
NBN是不使用bn层的 SE打钩才使用注意力机制 exp size对应倒残差块刚开始1*1卷积输出的深度 out对应倒残差块最后的深度。