刚刚踏足医疗方向,目前在研究医疗实体标化问题,相较于广义上的实体链接(entity linking),不存在实体链接一般会存在的一词多义(Entity Ambiguity)问题,确切来说,医疗标准化这块最主要的问题是多词同义(Mention Variations),即同一种病,同一种药等会有许多不同的表达方式,这就是我们要去处理的,让非结构化的数据输入进来,先找到mention,然后去KB里找到对应的entity作为输出,即标准化.举个例子,"感冒"进来,输出"上呼吸道感染".
看了不少论文,目前在对其中一篇进行初探,有想法有疑问就写出来,当成翻译也行,大家一起研究.
Title:<A Lightweight Neural Model for Biomedical Entity Linking>
论文:https://arxiv.org/abs/2012.08844
代码:https://github.com/tigerchen52/Biomedical-Entity-Linking
论文思路分三步:
一~预处理。对语料库中的所有mention和 KB 中的entity进行预处理,使它们具有统一的格式。
二~候选实体生成。对于每个mention,从KB中生成一组候选entity。
三~ranking模型。对于每个mention及其候选entity,使用排名模型对每对进行评分,输出topk
一~预处理
缩写扩充('DM'-'Diabetes Mellitus')
数字替换('VI'-'6')
KB增强(拿训练集扩充KB)
二~候选生成
为了计算mention M 和entity S 之间的分数,我们将它们中的每一个拆分为token, M = {m1, m2, ..., |} 和 S = {s1, s2, ...,
|}。
经过embedding后token维度是d*V,(embedding_dim*vocab_size*)
考虑 M和S中不同token排序的可能性,利用了余弦相似度(cosine similarity),定义了一个Acos函数,公式如下:
这个公式作用是找到对应M中的token 映射到S中的最相似的token
并返回与该余弦相似度.
为了防止余弦相似度倾向于长文本(余弦相似度似乎适用于短文本啊,怎么会倾向长文本?),以及度量对称(metric symmetric,这个我不懂),所以设计了一个相似度分数, 表达如下:
构造出来的候选集 ={ <E1, S1> , <E2,S2>,...,<Ek,Sk>} ,其中 Ei是mention的 id, Si是候选entity.这个集合包含每个mention 的topk个候选entity,如果存在分数等于 1的候选entity,别的就直接pass.
三~ranking模型
整个结构如图

从下到上:
word embedding:矩阵 d*V, V 是词表大小(vocab_size),d 是词向量维度(embedding_dim)
char embedding:解决OOV问题,就是从字粒度出发,采用Bi-lstm的输出作为char-level的表征.然后与word embedding输出拼接作为整个entity的表征.
alignment fearture:对齐层解决的其实就是顺序问题,这里利用了一个注意力矩阵(attention martrix),设计一个维度|M|*|S| 的权重矩阵 W ,表示mention 的
与entity的
的相似度,
,在W 的每一行上用softmax 函数归一化,产生一个新的矩阵 W '
定义mention的第 i 个 token向量 ,它是 S 中token的向量之和,权重为其与
的相似度:
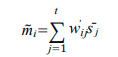
主要使用 S 中与
相似的向量相加来重构
,如果重建成功(即
与
相似),则 S 包含与
相同的信息
为了衡量这种相似性,使用以下两个比较函数:
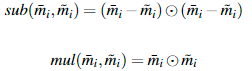
![]() 表示逐元素相乘
表示逐元素相乘
sub 与欧氏距离相似,mul 与 余弦相似度相似
最后,有了新的定义
![]()
类此,可以产生
![]()
CNN层 :现在mention和entity有了新的表示,![]()
![]()
直接上一层cnn
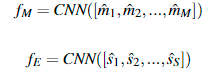
合并为一个输出: ![]()
输出层。使用两层全连接神经网络
![]()
其中W2 和W1是学习的权重矩阵,而 b1 和 b2是偏差值。
先写到这里,后面有新的理解和翻译再更新,2021年12月22日18:31:08