Flume的引入
- 关于Flume的介绍和使用,官网已经给了比较详细的介绍。本文在这里做一个总结。
- Flume是Apache下的一个开源的顶级项目,它是一个分布式,可扩展,高可用,高可靠的,轻量级数据收集框架,主要用来做数据的收集,聚合,和传输,相对与传统的数据导入导出框架Sqoop,它具备多方面优势,如,简单易用,Flume只需要一个简单的配置文件即可启动;功能全面,Flume在Source,Channel,Sink三个组件部分提供了很多功能,比如Source端多种类型以支持不同的数据收集需求,并可以自定义Source来满足特定的需求,Source的拦截器(Interceptor),Channel的Selector,Sink端的Processor(下文会一一介绍),并可配置压缩格式,定义文件格式等。
Flume基本概念
- 关于Flume的基本概念,如,Agent,Source,Channel,Sink可以参照之前博客,该篇文章也有Flume 的基本使用介绍,本篇文章就不做过度阐述,这里主要拎出Flume中重要概念之一,Event。
- Event: Event是Flume事件处理的最小单元,Flume在读取数据源时,会将一行数据(也就是遇到\r\n)包装成一个Event,它主要有俩个部分,Header和Body, Header主要是以Key,Value的形式用来记录该数据的一些冗余信息,可用来标记数据唯一信息,利用Header的信息,我们可以对数据做出一些额外的操作,如对数据进行一个简单过滤,Body则是存入真正数据的地方。
Flume架构
- Flume本身的架构特点保证了端到端的数据一致性,数据经过Source被存入到Channel中,如果选择合适的Channel可以保证数据的零丢失,并且Channel 中的数据只有在被Sink 端消费(也就是数据传输到下一个Agent或写入到文件后)才会在Channel中删除相应数据。
- Flume使用两个独立的事务分别负责从soucrce到channel,以及从channel到sink的事件传递。比如spooling directory source 为文件的每一行创建一个事件,一旦事务中所有的事件全部传递到channel且提交成功,那么source就将该文件标记为完成。同理,事务以类似的方式处理从channel到sink的传递过程,如果因为某种 原因使得事件无法记录,那么事务将会回滚。且所有的事件都会保持到channel中,等待重新传递。
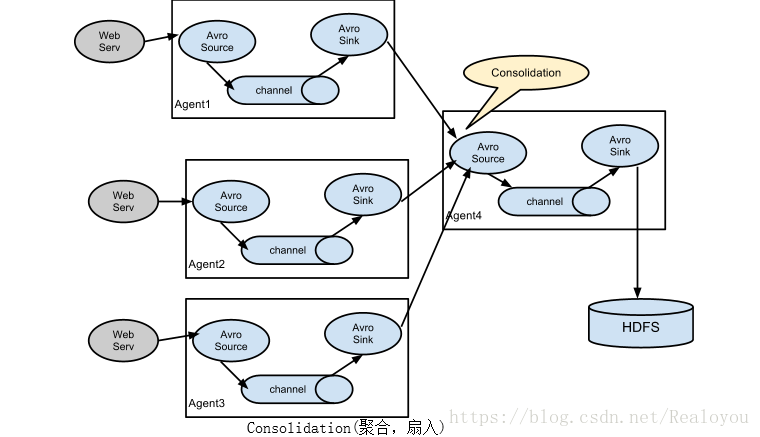
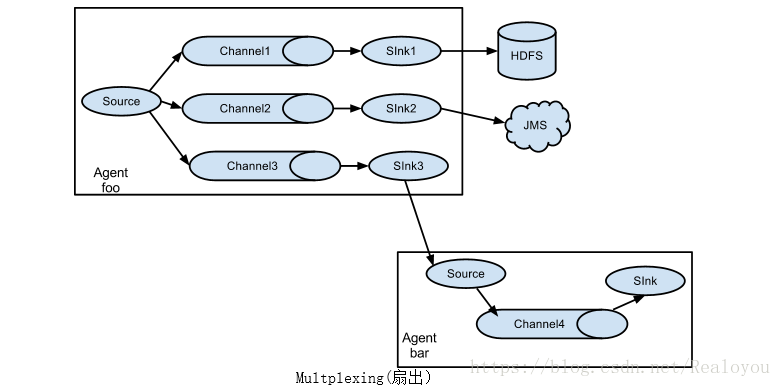
- Flume 官网介绍了Flume的两种架构选型,扇入和扇出模型,这两种架构需相互结合,并配合上Flume本身提供Load_balance,Failover 机制来使整体设计的架构稳定,可靠
Flume Interceptor(拦截器)
- Flume 的拦截器,直接从字面上理解的一种作用是拦截过滤指定的数据内容,做一个简单的清洗;还有一种作用是在Source写入到Channel中时,在Event的Header中添加一些有用的信息,比如添加Timestamp,下面介绍一些Flume中常见的Interceptor。
Timestamp Interceptor:
时间戳拦截器,将当前时间戳(毫秒)加入到events header中,key名字为:timestamp,值为当前时间戳。用的不是很多。比如在使用HDFS Sink时候,根据events的时间戳生成结果文件,hdfs.path = hdfs://var/tmp/event/%Y%m%dhdfs.filePrefix = log_%Y%m%d_%H
会根据时间戳将数据写入相应的文件中。
但可以用其他方式代替(设置useLocalTimeStamp = true)。
参数解释
Property Name Default Description type – 指定为:timestamp header timestamp header中的key的值 preserveExisting false 如果timestamp存在,是否保存
Host Interceptor:
主机名拦截器。将运行Flume agent的主机名或者IP地址加入到events header中,key名字为:host(也可自定义)。参数解释
Property Name Default Description type – 指定为:host preserveExisting false 如果host存在,是否保存 useIP true 使用IP,否则使用hostname hostHeader host header中的key的值
Static Interceptor:
静态拦截器,用于在events header中加入一组静态的key和value。参数解释
Property Name Default Description type – 指定为:static preserveExisting true 如果定义的key存在,是否保存 key key header中的key的值 value value header中的value的值
UUID Interceptor:
UUID拦截器,用于在每个events header中生成一个UUID字符串,例如:b5755073-77a9-43c1-8fad-b7a586fc1b97。生成的UUID可以在sink中读取并使用。参数解释
Property Name Default Description type – 指定为:org.apache.flume.sink.solr.morphline.UUIDInterceptor$Builder headerName id header中的key的值 preserveExisting true 如果UUID存在,是否保存 prefix “” UUID前缀
Regex Filtering Interceptor:
通过正则来清洗数据。参数解释
Property Name Default Description type – 指定为:regex_filter regex ”.*” 与事件匹配的正则表达式 excludeEvents false 按正则排除或匹配
Regex Extractor Interceptor:
通过正则表达式来在header中添加指定的key,value则为正则匹配的部分参数解释
Property Name Default Description type – 指定为:regex_extractor regex – 与事件匹配的正则表达式 serializers – 序列化value的方式,flume提供俩种内置方式:org.apache.flume.interceptor.RegexExtractorInterceptorPassThroughSerializer ,org.apache.flume.interceptor.RegexExtractorInterceptorMillisSerializer serializers.<s1>.type default 默认为default(org.apache.flume.interceptor.RegexExtractorInterceptorPassThroughSerializer), org.apache.flume.interceptor.RegexExtractorInterceptorMillisSerializer, 或者自定义class实现 org.apache.flume.interceptor.RegexExtractorInterceptorSerializer serializers.<s1>.name – key的名称 serializers.* – Serializer-specific properties
Flume Channel Selectors(选择器)
- Flume Channel Selectors 官方提供了两种选择,Replicating(复制)和Multiplexing(复用),当然,我们也可自定义Selectors,Replicating(复制):同一个Event会发送给每一个Channel 中;Multiplexing(复用):同一个Event只会选择多个Channel中的一个发送,默认使用Replicating Selector
Replicating Channel Selector (default):
参数解释
Property Name Default Description selector.type replicating 可指定类型:replicating selector.optional – 标记可选项的Channel名称注:当一个Channel被标记为可选项时,表示对该Channel写入失败时会被简单的忽略,而没被标记的Channel在写入失败时会导致Event传输停止
Multiplexing Channel Selector:
参数解释
Property Name Default Description selector.type replicating 指定为:multiplexing selector.header flume.selector.header header中key的名称 selector.default – 指定默认的Event传输的Channel selector.mapping.* – 传输到指定Channel的value属性
Flume Sink Processors(处理器)
- Flume官网提供了三种Processors可供选择,用户自定义Processor暂时还没被支持,使用Flume Sink Processors我们可以做负载均衡(load balancing)和fail over切换。
Default Sink Processor:
参数解释
Property Name Default Description sinks – 指定sink组的list,空格分隔 processor.type default processor类型default, failover or load_balance默认Sink Processor不会强制用户去创建sink group,可以采用最简单的source–channel–sink的单sink。
Failover Sink Processor:
FailoverSink Processor会通过配置维护了一个优先级列表。保证每一个有效的事件都会被处理。故障转移的工作原理是将连续失败sink分配到一个池中,在那里被分配一个冷冻期,在这个冷冻期里,这个sink不会做任何事。一旦sink成功发送一个event,sink将被还原到live 池中。在这配置中,要设置sinkgroups processor为failover,需要为所有的sink分配优先级,所有的优先级数字必须是唯一的,这个得格外注意。此外,failover time的上限可以通过maxpenalty 属性来进行设置。
参数解释
Property Name Default Description sinks – 指定sink组中sink的名称,空格分隔 processor.type default 指定类型为:failover processor.priority.<sinkName> – 指定sink组中sink的优先权,用数字表示,数字越大级别越高,且是唯一值 processor.maxpenalty 30000 故障sink的最大冷却周期
Load balancing Sink Processor:
负载均衡片处理器提供在多个Sink之间负载平衡的能力。实现支持通过round_robin(轮询)或者random(随机)参数来实现负载分发,默认情况下使用round_robin,但可以通过配置覆盖这个默认值。还可以通过集成AbstractSinkSelector类来实现用户自己的选择机制。
当被调用的时候,这选择器通过配置的选择规则选择下一个sink来调用。
参数解释
Property Name Default Description processor.sinks – 指定sink组中sink的名称,空格分隔 processor.type default 指定类型为:load_balance processor.backoff false Should failed sinks be backed off exponentially. processor.selector round_robin 指定负载机制 processor.selector.maxTimeOut 30000 Used by backoff selectors to limit exponential backoff (in milliseconds)