softmax函数
softmax用于多分类过程中,它将多个神经元的输出,映射到(0,1)区间内,可以看成概率来理解,从而来进行多分类!
假设我们有一个数组,V,Vi表示V中的第i个元素,那么这个元素的softmax值就是
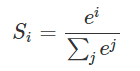
更形象的如下图表示:
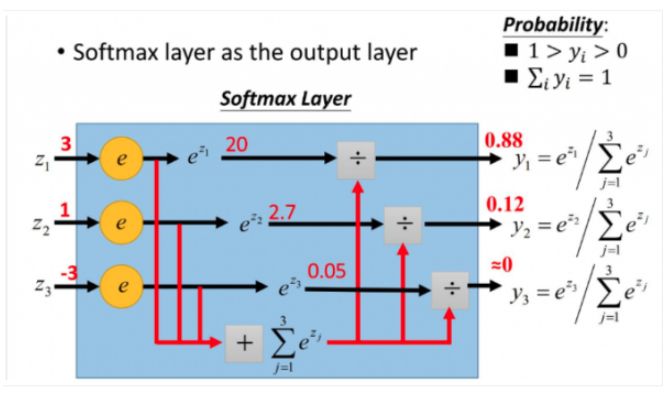
softmax直白来说就是将原来输出是3,1,-3通过softmax函数一作用,就映射成为(0,1)的值,而这些值的累和为1(满足概率的性质),那么我们就可以将它理解成概率,在最后选取输出结点的时候,我们就可以选取概率最大(也就是值对应最大的)结点,作为我们的预测目标!
举一个我最近碰到利用softmax的例子:我现在要实现基于神经网络的句法分析器。用到是基于转移系统来做,那么神经网络的用途就是帮我预测我这一个状态将要进行的动作是什么?比如有10个输出神经元,那么就有10个动作,1动作,2动作,3动作...一直到10动作。(这里涉及到nlp的知识,大家不用管,只要知道我现在根据每个状态(输入),来预测动作(得到概率最大的输出),最终得到的一系列动作序列就可以完成我的任务即可)
原理图如下图所示:
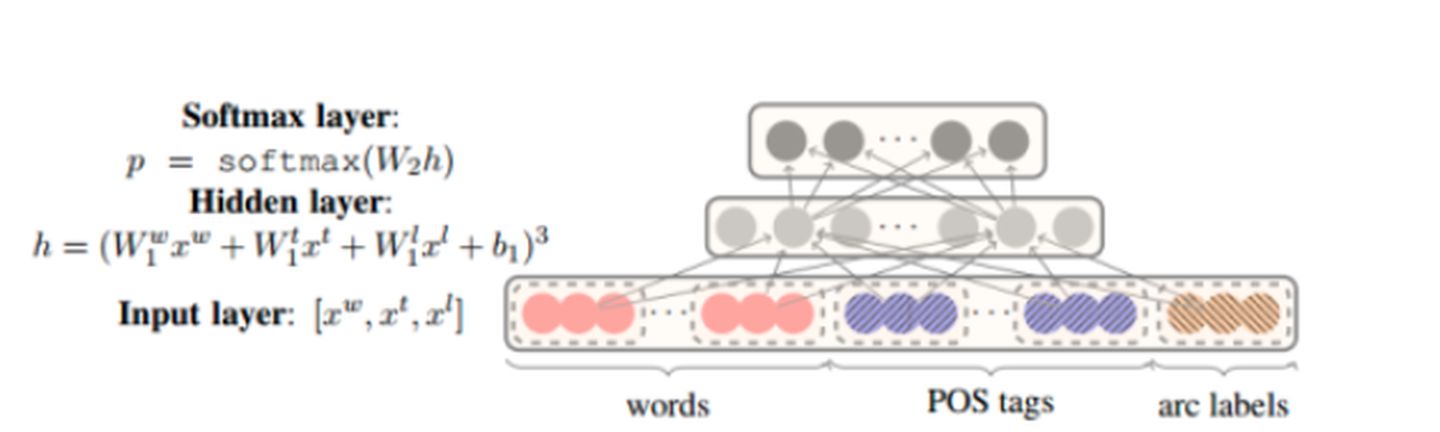
那么比如在一次的输出过程中输出结点的值是如下:
[0.2,0.1,0.05,0.1,0.2,0.02,0.08,0.01,0.01,0.23]
那么我们就知道这次我选取的动作是动作10,因为0.23是这次概率最大的,那么怎么理解多分类呢?很容易,如果你想选取俩个动作,那么就找概率最大的俩个值即可
(softmax取自
作者:忆臻
链接:https://www.zhihu.com/question/23765351/answer/240869755
来源:知乎)
hardmax
hardmax函数就是平时大家用的max()函数
softmax和hardmax的区别
hardmax是找到数组中所有元素的最大的元素;softmax含义在于不再唯一的确定某一个最大值,而是输出每个分类结果的概率值,表示这个类别的可能性;将多分类信息,转化为范围在[0,1]之间和为1的概率分布;
Sigmoid函数
常用的转化线性信号为非线性信号的激活函数,数学表达形式如下:
主要特点:
1:将输入的连续值转化到0和1之间的输出;
2:深度学习的反向传递中可能导致梯度爆炸和梯度消失的情况,梯度消失发生的概率比较大;如果初始化神经网络的权重为高斯分布的随机值(均值为0方差为1),通过反向传播算法的数学推导可知,每一层梯度值会逐层下降0.25,如果神经网络层特别多,可能使得在穿过多层之后,梯度非常小,可能接近于0,即出现梯度消失的现象;
3:由于sigmoid函数的函数值是正数,那么每一层的输入为上一层的非0均值信号,模型收敛可能不理想;
4:幂运算的求解耗时,增加训练时间
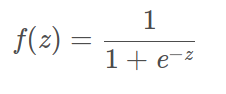

――――――――――――――――
原文链接:https://blog.csdn.net/yangqinglin193/article/details/114661925
激活函数
激活函数是神经网络中对输入数据转换的方法,通过激活函数后将输入值转化为其他信息;在神经网络的隐藏层中,激活函数负责将进入神经元的信息汇总转换为新的输出信号,传递给下一个神经元;如果不使用激活函数,每个输入节点的输入都是一样的,成为了原始的感知机,没有信号的转换,使得网络的逼近能力有限,无法充分发挥网络的强大学习能力;
――――――――――――――――
原文链接:https://blog.csdn.net/yangqinglin193/article/details/114661925
输出层函数
输出层神经元,通过将输出值经过输出层函数转化为针对某一分类的置信概率值,在多分类问题中常见(softmax)
――――――――――――――――
原文链接:https://blog.csdn.net/yangqinglin193/article/details/114661925
attention机制
attention机制计算某个数值占比注意力的时候,使用softmax进行计算。
在Seq2Seq中,编码时输入序列的全部信息压缩到了一个向量表示中,随着序列增长,句子越前面的词的信息丢失就越严重。另外,Seq2Seq模型的输出序列中,经常会损失部分输入序列的信息,这是因为在解码时,当前词及对应的源语言词的上下文信息和位置信息在编解码过程中丢失了
Seq2Seq模型中引入注意力机制就是为了解决上述的问题。采用双向循环神经网络的注意力机制模型如图所示:
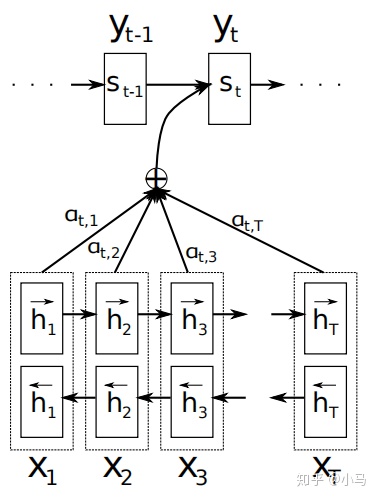


attention机制取自https://zhuanlan.zhihu.com/p/97722949