简介
一般来说,优化模型预测效果有两种方法。一是使用更加复杂的模型,二是采用集成策略。这两种方法在实际应用中都会造成很大的计算开销。因此,本文提出了一种叫做知识蒸馏的方法,从大模型中提取知识给小模型,在减少模型复杂度的同时保证预测效果。
通常我们认为模型从训练中得到的知识就是神经网络的参数,更确切的说法是从输入向量到输出向量的映射。所以我们训练小模型的目标就是让它学习大模型输入到输出的映射关系。
小模型的输入向量就是经过预处理后的数据,输出向量一般就是输出的softmax分布。于是,原来我们需要让模型输出的softmax分布与真实标签匹配,现在只需要让小模型和大模型在输入相同的情况下输出的softmax分布相近即可。大模型的softmax分布被称为小模型训练的“软目标”(soft target)。
softmax函数会通过e的x次方这类形式,拉大logits(softmax函数的输入向量)之间的大小差距,大的越大,小的越小,所以其输出的向量会非常接近one-hot向量。这种方法的缺点是输出正确分类概率的非常大,而输出错误分类的概率非常小。而即使是错误的分类,里面也包含了一些有用的信息。比如宝马车的图片,被识别为拖拉机的概率是远远大于识别为胡萝卜的概率的。
规避上述问题的一个简单的方案是:直接使用logits的分布作为软目标,而不使用softmax分布。而另外一个更一般、效果更好的方案也就是本文的重点:知识蒸馏。
如何“蒸馏”
一般化的softmax公式:
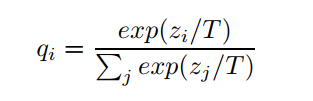
其中,qi为概率,T为温度,zi为上文中提到的logit。通常情况下我们见到的softmax函数就是T=1的特殊情况。容易证明,当T趋近于0时,其最后输出的概率向量会更偏one-hot;当T趋近于无穷大时,其输出的概率向量中各概率会更加接近,即更“软”。于是,在“蒸馏”时,我们将已经训练好的大模型(即已经学得知识的模型)的温度T升高至一定程度,将数据重新输入大模型,获得升温后的“软”的softmax分布,并将该分布作为小模型训练的软目标,在小模型训练时,也将温度T升高至和此时的大模型的T一样大,训练结束后,将小模型的温度T再降低到1,使“蒸馏”出的知识在新模型中“冷凝”。至此,就获得了和大模型性能相近而模型复杂度、参数数量大幅降低的小模型。

论文里把大模型称为 teacher model,小模型称为student model。
损失函数由两部分构成,一部分是student model在 soft targets 上训练得到的交叉熵损失函数,一部分是在真实带标签数据(hard targets)上训练得到的交叉熵损失函数乘以 1/T^2(保证两个 Loss 所产生的影响差不多) 。
https://mp.weixin.qq.com/s/9a9SiKkAcT1X3hKE0oHlEw.