《GhostNet:More Features from Cheap Operations》
??发现一个点并解决就是一篇CVPR,该文章主要发现了优秀的网络的特点是feature map提取过程中的冗余性,这种冗余性体现在很多成对的feature map间很像,就好像彼此的“ghost”,而这种特征冗余性对于理解图像来说还是必要的,所以文章把feature map分为两种,一种是本质特征,一种是“ghost”,其中“ghost”可以通过低廉的线性运算来完成,先通过普通的卷积提取本质特征,再通过线性变换对特征进行增强,这样大大减少了参数和运算量。感觉上是对原始的卷积特征一部分保留,一部分用深度可分离卷积代替。Ghost module是一个即插即用的模块,可以用来替换分类网络的卷积层从而获得更高的精度。d是ghost模块的卷积核尺寸,s是ghost模块通过卷积对同一个本质特征映射图产生ghost特征映射图的数目。通过MSE来对比特征映射图之间的差异能够发现特征图间的相关性。
Key Words:intrinsic feature maps、linear transformations、Ghost module、plug-and-play component
CVPR, 2020
作者:kai.han,yunhe.wang,tian.qi1,xuchunjing
Code:https://github.com/huawei-noah/ghostnet
Agile Pioneer??
文章目录
-
- 摘要
- 介绍
- 相关工作
- GhostNet设计
-
- 利用Ghost模块提取更多特征
- Ghost模块的复杂度分析
- Ghost Module 的有效性
-
- 超参数实验对比
-
- CIFAR-10上测试卷积核size
- CIFAR-10上测试不同的s(每个本质特征变换出s个ghost特征)
- 特征图的可视化
- ImageNet上 vs 其他模型
-
- 大模型的对比
- 轻量级模型的对比
- 结论
摘要
??在嵌入式设备上部署卷积神经网络(CNNs)是比较难的,因为设备的内存和算力资源很有限。对于那些成功的CNNs一般层数角度,一个特点就是feature map是冗余的,但是这种情况很少在网络设计上被察觉。本文提出了一个新颖的Ghost模块通过低廉运算的操作就能够得到更多的feature maps。基于固有的feature map集合,我们使用一系列的低廉运算的线性变换来产生许多ghost feature map能够彻底的揭示潜在固有特征的信息。我们提出的Ghost 模块可以作为一个即插即用的模块来提高已有的神经网络。通过堆叠Ghost 模块得到Ghost bottleneck,然后就很容易的得到了一个轻量级的GhostNet。在基准上实验的结果证明了我们提出的Ghost模块是一个令人印象深刻的替换baseline卷积层的方式,并且我们的GhostNet在ImageNet ILSVRC-2012分类数据集上,比MobileNetv3有更高的识别准确率(75.7%的top 1准确率)而且需要更少的计算量。

介绍
??随着这些年移动端的AI应用越来越多,对于模型轻量化的方法研究也随之增多,比如:模型裁剪(model pruning)、低秩量化(low-bit quantization)、知识蒸馏(knowledge-distillation)等。
??此外,利用更少的参数和计算量来设计高效的结构也是非常有潜力能设计出高效的神经网络的,这种做法在这段时间也取得了相当大的成功。而且可以为搜索框架提供新的搜索结构单元。比如MobileNet利用深度可分离卷积核逐点卷积构建的单元在更大的卷积核来近似原始的卷积层,并达到了相当的效果。ShuffleNet进一步提取了channel的洗牌操作来增强轻量级模型的表现。
??对于一个训练的很好的深度神经网络模型来说,一个重要的特征是冗余的特征,丰富的甚至冗余的特征是对输入数据有综合理解的保证,如图1所示输入数据用ResNet-50提取的特征来看,存在许多相似的特征对,他们就好像彼此的ghost。与其避开这些特征,莫不如通过一个高效的方式来利用它们。
??论文提出的Ghost模块能够通过更少的参数量来产生更多的特征。具体的做法是,**网络中的一个普通的卷积层将会被分成两部分。第一部分包含普通的卷积但是它们的总数将会被严格控制。假设内在的特征映射图来自第一部分,一系列的简单线性操作会用于产生更多的特征映射图。**不需要改变输出的特征映射图的尺寸,而整体的参数和计算复杂度在Ghost模块中都被减少了。
相关工作
??调研模型压缩 ,连接裁剪是对模型不重要的连接进行裁剪。Channel裁剪进一步的移除没用的channel。模型量化是使用离散的值来近似表示原始的参数,从而达到存储变小和加速计算的目的。典型的二值方法只用1比特的值来存储网络的权重。张量分解,通过挖掘冗余特征和对权重低秩描述来降低参数和加速计算。知识蒸馏,利用更大的模型来引导小模型学习,提高了小模型的表现,这种方法都依赖于预训练模型。在基础操作和模型结构上的改进可能会更好。
??调研压缩模型的设计 ,为了满足在嵌入式设备上部署神经网络的需求。一系列压缩模型层出不穷。Xception、MobileNet全系、shuffleNet系列、EfficientNet、MixNet等等。Xception利用深度卷积操作来高效利用了模型参数。MobileNet使用了深度可分离卷积,MobileNetv2使用了逆残差块,MobileNetv3进一步利用了AutoML技术达到了更好的效果。ShuffleNet介绍了channel混洗操作来在不用组的channel间提高信息流交换。ShuffleNetV2进一步考虑了实际的目标硬件的速度来进行模型压缩设计。尽管这些模型能够在很少的计算量下有很好的表现,但是特征映射图之间的相关性从来没有被深挖。
GhostNet设计
??Ghost模块利用原始卷积层在几个小的卷积核产生的特征上获得更多的特征映射图,然后通过Ghost模块开发一个具有高性能和高表现的网络-GhostNet。
利用Ghost模块提取更多特征
??尽管目前很多的轻量级网络诸如MobileNet和shuffleNet能够利用深度卷积和混洗操作使用小卷积核来构建高效的卷积神经网络,但余下的1x1的卷积层仍旧占据了相当大的内存和FLOPs。
??Ghost模块通过线性变换模块来代替部分通过卷积提取的特征,来减少参数量和运算量,假定输入数据为 X ∈ R c × h × w X \in R^{c \times h \times w} X∈Rc×h×w,其中c是输入的channel数,h和w是输入数据的高和宽,相应地任何产生n个特征映射图的卷积层操作都可以用如下公式来表示:
Y = X ? f + b ( 1 ) Y = X * f + b \space\space\space\space (1) Y=X?f+b (1)
其中*代表的是卷积操作,b表示偏置项, Y ∈ R h ′ × w ′ × n Y \in R^{h^{'} \times w^{'} \times n} Y∈Rh′×w′×n表示n个channel的输出特征映射图, f ∈ R c × k × k × n f \in R^{c \times k \times k \times n} f∈Rc×k×k×n表示卷积核。此外 h ′ h^{'} h′和 w ′ w^{'} w′表示输出数据的高和宽,k表示卷积核的尺寸。在执行卷积运算的FLOPs的运算可以被计算为 n × h ′ × w ′ × c × k × k n \times h^{'} \times w^{'} \times c \times k \times k n×h′×w′×c×k×k,运算量动辄成千上万,因为其中n和c的占比是很大的,因为一般channel数都会设置为(256或512)。

??图2阐释了卷积层和Ghost模块对于相同channel数的输出特征图。其中 Φ \Phi Φ代表低廉的运算。
??我们指出的冗余特征其实不必利用有大量FLOPs和参数的卷积运算来完成。假设输出的特征映射图是本质特征图通过低廉的变换得到的“ghosts”,而这些本质特征是通过普通的小卷积核得到的特征:
Y ′ = X ? f ′ ( 2 ) Y^{'} = X * f^{'} \space\space\space\space (2) Y′=X?f′ (2)
??其中 f ′ ∈ R c × k × k × m f^{'} \in R^{c \times k \times k \times m} f′∈Rc×k×k×m是使用的卷积核, m ≤ n m \le n m≤n并且为了简化,偏置项b被省略了。超参数就只有和卷积相关的卷积核大小,步长,padding,这些和公式1中的普通卷积是一样的,所以输出的特征映射图的高和宽和前面都是一致的。为了能够和普通卷积一样输出n个channel的特征映射图,我们对每个本质特征采取了一系列的低廉运算(卷积),也就是一个特征映射图得到s个ghost特征图,根据下面的公式:
y i j = Φ i , j ( y i ′ ) , ? i = 1 , . . . , m , j = 1 , . . . , s ( 3 ) y_{ij} = \Phi_{i,j}(y_i^{'}), \space\space \forall \space i=1,...,m,\space\ j=1,...,s \space\space\space\space(3) yij?=Φi,j?(yi′?), ? i=1,...,m, j=1,...,s (3)
??一个 y i ′ y_i^{'} yi′?可能有一个或多个ghost特征图 { y i j } j = 1 s \{y_{ij}\}^{s}_{j=1} { yij?}j=1s?,每个本质特征映射图 y i ′ y_i^{'} yi′?都需要通过卷积运算生成s-1个新的ghost特征,因为最后输出的结果中也保留(同一性映射)一个本质特征映射图。根据公式3,我们可以得到 n = m × s n=m \times s n=m×s个特征映射图, Y = [ y 11 , y 12 , . . . , y m s ] Y = [y_{11}, y_{12}, ..., y{ms}] Y=[y11?,y12?,...,yms]是Ghost模块的返回结果,如图2b所示。值得注意的是线性操作 Φ \Phi Φ是在每个channel单独做的,所以参数量和计算量都远小于普通卷积。实际上我们在ghost模块中使用的线性操作可能是3x3和5x5的线性核。
??之前的轻量网络中使用深度可分离卷积来处理空间信息,然后使用点卷积来处理channel间的特征交叉信息。相反,Ghost模块采用普通的卷积先来生成几个本质的特征映射图,然后在利用低廉运算操作来对特征进行增强,从而增加channel数。之前的高效网络结构在处理每个特征映射图的时候受限于深度卷积核转换操作,而Ghost模块的线性操作有很大的多样性。此外,Ghost模块也保留了m个本质特征图。
Ghost模块的复杂度分析
??复杂度分析 Ghost模块很容易替换掉现有的网络结构中的普通卷积,我们现在来分析一下Ghost模块的理论内存占用和加速比例。例如:一个同一性变换和 m × ( s ? 1 ) = n s × ( s ? 1 ) m \times (s - 1)=\frac{n}{s} \times (s - 1) m×(s?1)=sn?×(s?1)是我们要用低廉的线性变换所产生的特征图的个数。考虑到CPU和GPU卡的利用,我们建议在一个Ghost模块中的线性操作使用相同的卷积核尺寸(3x3或5x5)来执行。理论上使用Ghost模块替换掉普通卷积的加速比为:
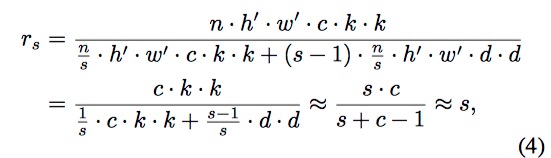
其中 d × d d \times d d×d和 k × k k \times k k×k有相同的量级, 而且s远小于c。类似地,模型的压缩比计算如下:
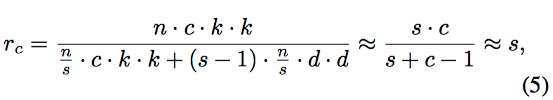
??s越大,肯定参数越少,而且计算速度越快,但是s越大,ghost特征占比越多,而本质特征占比就变少了,模型表达效果肯定不理想,所以这里需要一个balance。
??由Ghost模块来组成的Ghost bottleneck的示意图如下:

??Ghost bottleneck和基础的ResNet模型是很像的,也是几个卷积层加shortcut连接的组合,Ghost bottleneck主要由两部分组成,第一部分用于对通道进行扩张,第二部分对通道进行压缩使其能够和shortcut相连接。每层间都使用BN和RuLU,除了第二个Ghost模块,因为MobileNetv2论证了ReLU在低维的损失较为严重的问题。

Ghost Module 的有效性
超参数实验对比
CIFAR-10上测试卷积核size
??以VGG16位基础结构,加持Ghost模块,固定s=2,然后调节d在集合{1, 3, 5, 7},d=3最好。

CIFAR-10上测试不同的s(每个本质特征变换出s个ghost特征)
??固定d=3,然后调节d在集合{2, 3, 4, 5},s=2最好。

特征图的可视化
??我们也对使用ghost模块的网络机械能了特征图可视化如下图所示。尽管生成的特征映射图是来自于原始的特征映射图,它们的确有显著的不同,也就意味着生成的特征是灵活的能满足于具体任务的需求的。

ImageNet上 vs 其他模型
大模型的对比

轻量级模型的对比


结论
??为了减少近来深度神经网络的计算消耗。本文提出了一个新颖的Ghost模块来构建有高效的神经网络结构。基础的Ghost模块把原始的卷积层分为了两个部分并利用几个滤波器来生成几个本质的特征映射图。然后,在使用确定数目的低廉的线性变换对本质特征映射图进行生成ghost特征映射图。在基准模型和数据集上的实验表明我们提出的方法是一个即插即用的模块把原始的模型转化为一个压缩的模型,同时保持可比较的性能。此外,使用提出的新模块构建的GhostNet在效率和准确率上都超过了目前最好的移动端模型。