目录
-
-
- 摘要
- 1 引言
- 2 任务定义
- 3 模型
-
- 3.1 嵌入层
- 3.2 注意力嵌入传播层
- 3.3 模型预测
- 3.4 优化
- 4 实验
-
- 4.1 数据描述
- 4.2 实验设置
- 4.3 模型表现 RQ1
- 4.4 消融实验 RQ2
- 4.5 案例研究RQ3
-
摘要
推荐算法引入side info,传统算法(FM)假设每个交互都是一个带有side info 编码的独立实例,这些方法不足以从用户的集体行为中提取出协作信号。本文提出KGAT,显式地构造KG图中地高阶连通性。
1 引言
CF模型无法引入side info。SL模型引入side info的范式:将side info、uid,iid转化成特征向量,将他们送入监督模型来预测得分,比如FM、NFM、WideDeep、xDeepFM。
SL模型将一条交互建模成单独的数据样本,没有考虑交互之间的关系。

由图一可见CF和基于特征的SL模型的局限性,对于target user u1来说:
- CF模型关注历史行为的相似用户,也就是也看了i1的用户,u4
- 基于特征的SL模型,关注于和i1有相似特征(e1)的item,i2
- 忽略了黄色区域和灰色区域
为了解决SL模型的局限性,解决方法为考虑item side info的图形式(将KG和交互图混合,CKG,collaborative knowledge graph),这样就可以探索高阶连通性,就可以到达黄色区域和灰色区域。挑战有:阶数越高,计算复杂度高;高阶关系的加权和选择问题
CKG的研究有基于path的,基于正则化的,各有缺点;本文的KGAT使用GNN,高效、显式的和端到端的方式来对高阶连通性建模。
2 任务定义
- 用户-物品二部图
- 知识图谱,注意关系集合R包含正方向和逆方向(比如 电影被xx主演;xx主演电影;这是两个关系)
- 协调知识图,CKE,将用户行为和物品知识整合成一个统一关系图,将交互看作一种关系,整合两个图
任务描述:输入CKE;输出u对i地预测得分
- 高阶连通性,CF方法建立在用户之间的行为相似性之上,行为相似性就可以用高阶连通性来表示
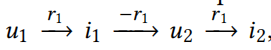
不同于CF模型,SL模型致力于基于属性的连通性,比如u1可能采用i2,i2和i1有相同的导演;但是SL模型不能展示跨field和相关实例的关系,比如:
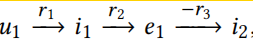
3 模型

3.1 嵌入层
使用一种知识图嵌入模型――TransR,学习到实体和关系的表示。每个关系有一个转化矩阵 WrW_rWr?,将头实体和尾实体投影到关系r的空间中。下式这个得分越小,表明嵌入越好。
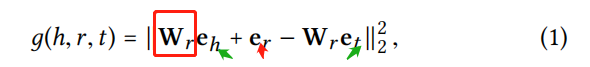
采用pair loss来训练:
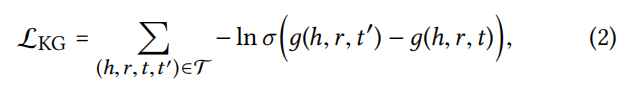
3.2 注意力嵌入传播层
信息传播,用 NhN_hNh? 表示h作为头实体的三元组集合,计算h的 ego-network,其中 π\piπ 表示在关系r下从尾实体t传递信息到头实体h,的信息量比例。
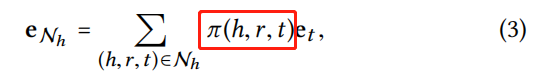
知识感知的注意力,π\piπ 通过关系注意力机制实现:
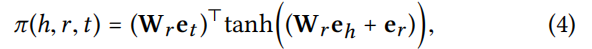
注意分数取决于h和t在关系r空间中的距离,越近的实体传递的信息量越多。h通过所有的尾实体来传递信息给自身*(感觉也可以反过来,尾实体由所有头实体传递信息)*,所以 π\piπ 归一化的分母是所有尾实体:
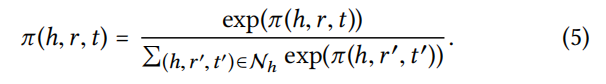
GAN只以节点表示为输入,但是KGAT输入还包括关系r,在传播的过程中编码了更多信息。
信息聚合,聚合实体表示 ehe_heh? 和 它的 ego-network表示 eNhe_{Nh}eNh? ,使用了三种聚合算子:
- GCN Aggregator
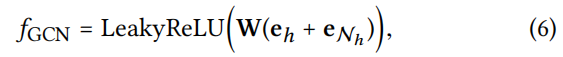
- GraphSage Aggregator
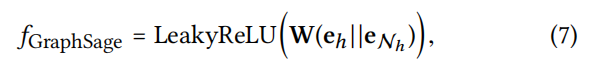
- Bi-Interaction Aggregator
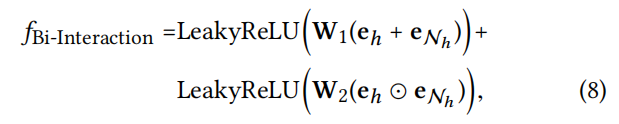
嵌入传播层的优点在于显式地利用一阶连接信息来关联用户、物品和知识实体表示。
高阶传播,stack更多嵌入传播层,来探究高阶连通信息,从多阶邻居收集传播到的信息。
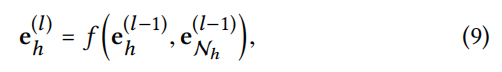
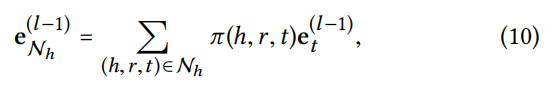
3.3 模型预测
concat 每一层的用户/物品 表示(包括初始的嵌入)得到最终表示
对最终表示进行内积得预测分
3.4 优化
BPR loss:
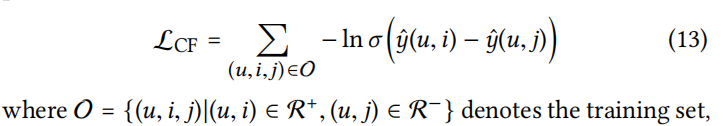
联合TransR的损失,最终损失函数为:
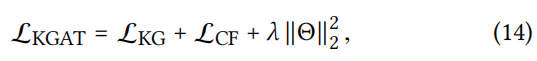
- 交替优化 LKGL_{KG}LKG? 和 LCFL_{CF}LCF?
4 实验
4.1 数据描述
- 10-core
- Amazon-book和Last-FM,将item通过匹配Freebase中的实体;不同于现有的知识感知数据库只提供item的一阶实体,本文考虑涉及到item的二阶实体;
- Yelp2018,从数据中(目录、位置、属性)提取item KG
- 每个用户交互行为的80%作为训练集;训练集的随机10%作为验证集调参
- 每个正样本采样一个负样本
4.2 实验设置
评价指标:所有模型输出用户对所有物品的预测得分(除了训练集中的正样本),recall,ndcg
baseline: FM、NFM;CKE、CFKG;MCRec、RippleNet;GC-MC
参数:Adam、batch1024、Xavier初始化、网格搜索{学习率、dropout率、L2系数};提前终止:当recall在验证集上连续50epoch没有增长
4.3 模型表现 RQ1

还探究了使用高阶连通性能否缓解稀疏性:基于user的交互数量划分测试集为4个组,并且保持4个组每个组的总交互数相同

4.4 消融实验 RQ2
layer number、聚合操作、KG嵌入和注意力



4.5 案例研究RQ3

个人认为本篇论文核心是:KG和交互图的混合;先用KGE初始化嵌入;再使用GNN进行信息传播,同时使用注意力机制,用多阶邻居节点共同更新当前节点的表示。