开篇我们先对Spider这个功能模块进行一个官方的说明:
Burp Spider 是一个映射 web 应用程序的工具。它使用多种智能技术对一个应用程序的内容和功能进行全面的清查。
Burp Spider 通过跟踪 HTML 和 JavaScript 以及提交的表单中的超链接来映射目标应用程序,它还使用了一些其他的线索,如目录列表,资源类型的注释,以及 robots.txt 文件。结果会在站点地图中以树和表的形式显示出来,提供了一个清楚并非常详细的目标应用程序视图。
Burp Spider 能使你清楚地了解到一个 web 应用程序是怎样工作的,让你避免进行大量的手动任务而浪费时间,在跟踪链接,提交表单,精简 HTNL 源代码。可以快速地确人应用程序的潜在的脆弱功能,还允许你指定特定的漏洞,如 SQL 注入,路径遍历。
(以上都是百度的……23333)。
那官方话说完我们来谈谈小编自己的一些看法,首先学网络的都应该知道爬虫是什么,那么此模块的功能如名,Spider,蜘蛛爬虫,可以帮助我们爬取网站结构。
此功能下的爬虫异常强大,希望大家慎用2333.
那么接下来我们开始对Spider的基础功能进行一些说明:
首先,和前几章一样,依然是将浏览器代理和Burp的监听代理调成一致。
拦截一个请求,此时打开Target的Site Map,应该还是空的(废话,啥都还没抓呢)。返回刚刚抓取的信息,右键,Sent to Spider。
此时再切回Target,就可以在Site Map中看到抓取到的很多URL:
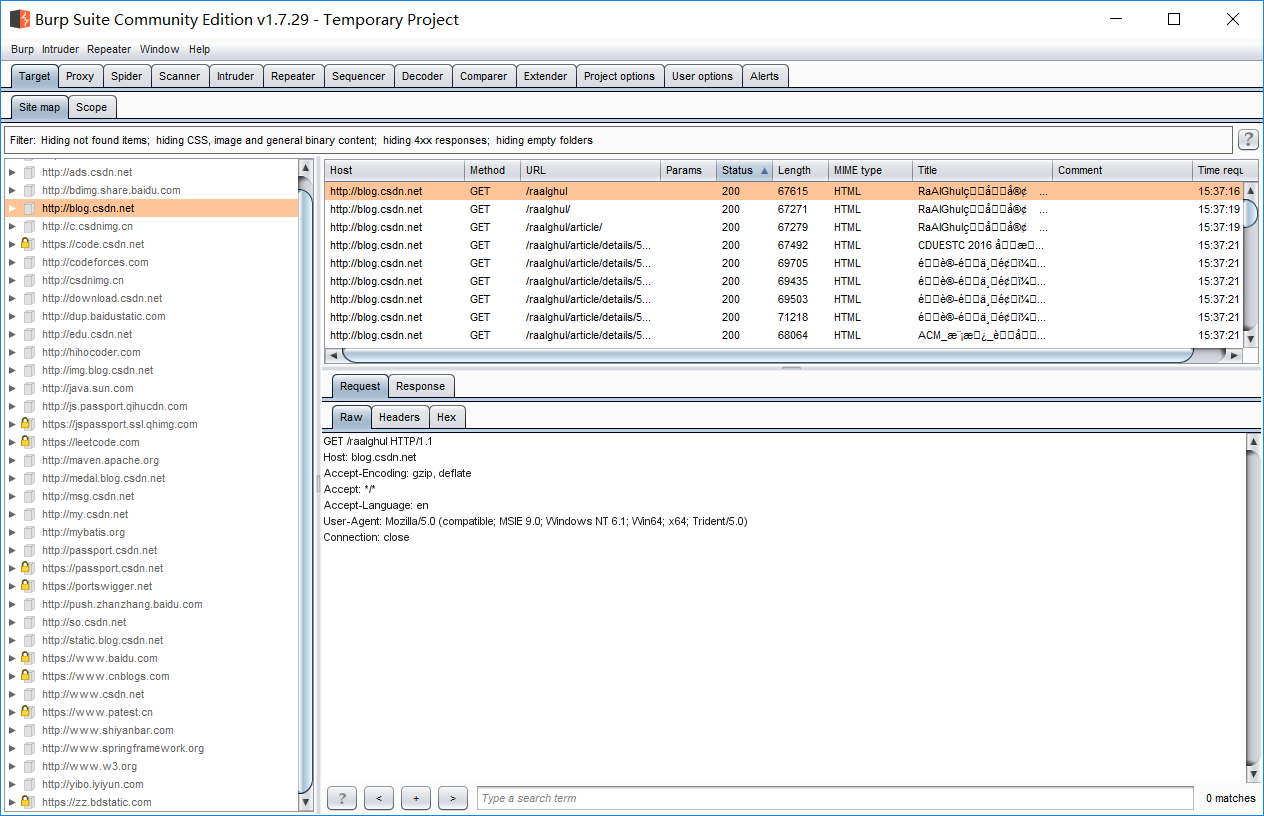
那么我们就可以将这些URL发送给Burp其他模块进行一些漏洞利用等功能。
这里我们倒回来,看一下Spider的设置。
在Spider Control(控制)中我们能看到Spider Status(状态)和Spider Scope(范围)的设置:
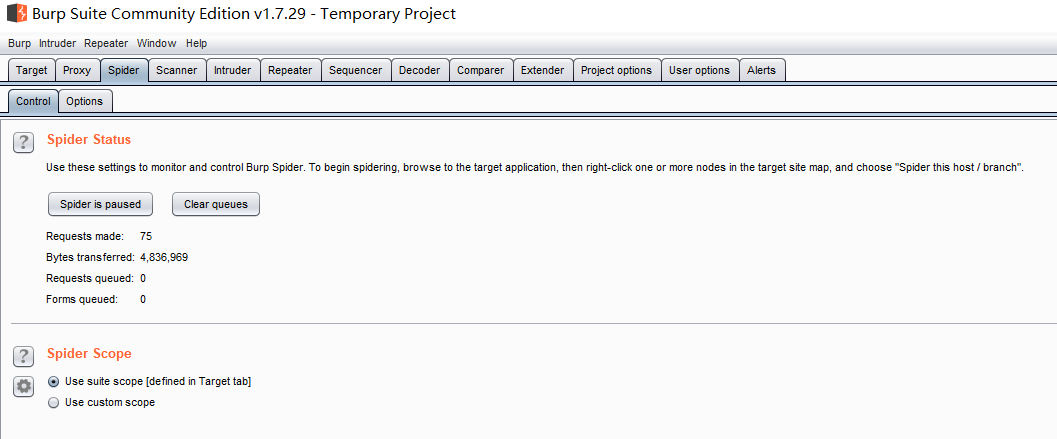
在Option(设置)选项中包含了很多控制爬虫动作的选项。
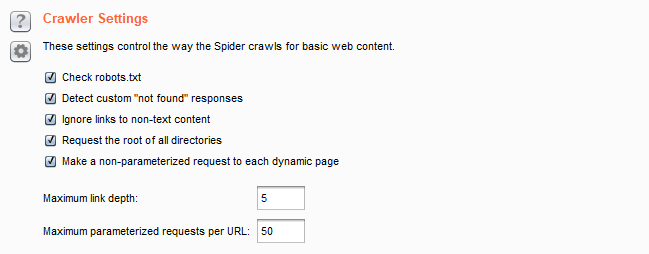
Crawler Settings(爬虫基本设置):
・ check robots.txt:检测robot.txt文件。选择后Burp Spider会要求和处理robots.txt文件,提取内容链接。
・ Detect custom "not found" responese:检测自定义的'not found'响应。打开后Burp Spider会从每个域请求不存在的资源,编制指纹与诊断“not found”响应其它请求检测自定义“not found”的响应。
・ ignore links to non-text content:忽略非文本内容的连接。这个选项被选中,Spider 不会请求非文本资源。使用这个选项,会减少 spidering 时间。
・ request the root of all directories:请求所有的根目录。如果这个选项被选中,Burp Spider 会请求所有已确认的目标范围内的 web 目录,如果在这个目标站点存在目录遍历, 这选项将是非常的有用。
・ make a non-parameterized request to each dynamic page:对每个动态页面进行非参数化的请求。如果这个选项被选中,Burp Spider 会对在范围内的所有执行动作的 URL 进行无参数的 GET 请求。如果期待的参数没有被接收, 动态页面会有不同的响应,这个选项就能成功地探测出额外的站点内容和功能。
・ Maximum link depth:这是Burp Suite在种子 URL 里的浏览”hops”的最大数。0表示让Burp Suite只请求种子 URL。如果指定的数值非常大,将会对范围内的链接进行无限期的有效跟踪。将此选项设置为一个合理的数字可以帮助防止循环Spider在某些种类的动态生成的内容。
Maximum parameterized requests per URL:请求该蜘蛛用不同的参数相同的基本URL的最大数目。将此选项设置为一个合理的数字可以帮助避免爬行“无限”的内容。
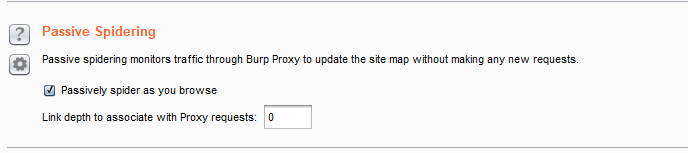
Passive Spidering(被动扫描):
・ Passively spider as you browse:如果这个选项被选中,Burp Suite 会被动地处理所有通过 Burp Proxy 的 HTTP 请求,来确认访问页面上的链接和表格。使用这个选项能让 Burp Spider 建立一个包含应用程序内容的详细画面,甚至此时你仅仅使用浏览器浏览了内容的一个子集,因为所有被访问内容链接到内容都会自动地添加到 Suite 的站点地图上。
・ link depth to associate with proxy requests:这个选项控制着与通过 Burp Proxy 访问的 web 页面 有关的” link depth”。为了防止 Burp Spider 跟踪这个页面里的所有链接,要设置一个比上面 选项卡里的” maximum link depth”值还高的一个值。
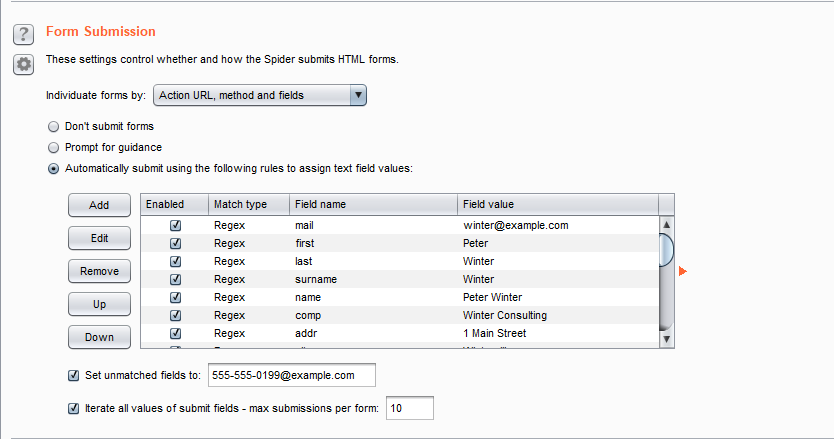
Form Submission(表单提交设置):
・ individuate forms:个性化的形式。这个选项是配置个性化的标准(执行 URL,方法,区域,值)。当 Burp Spider 处理这些表格时,它会检查这些标准以确认表格是否是新的。旧的表格不会加入到提交序列。
・ Don’t submit:开启后蜘蛛不会提交任何表单。
・ prompt for guidance:提醒向导。如果被选中,在你提交每一个确认的表单前,Burp Suite 都会为你指示引导。这允许你根据需要在输入域中填写自定义的数据,以及选项提交到服务器的哪一个区域。
・ automatically submit:自动提交。如果选中,Burp Spider 通过使用定义的规则来填写输入域的文本值来自动地提交范围内的表单。每一条规则让你指定一个简单的文本或者正则表达式来匹配表单字段名,并提交那些表单名匹配的字段值。
・ set unmatched fields to:设置不匹配的字段。
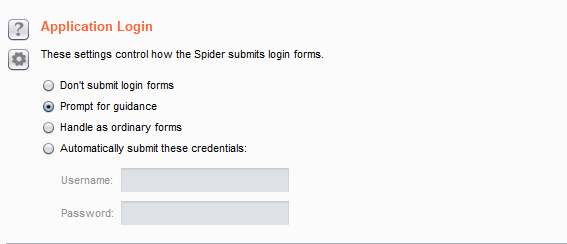
Application Login(登陆表单提交设置):
・ don't submit login forms:不提交登录表单。开启后burp不会提交登录表单。
・ prompt for guidance:提示向导。Burp能交互地为你提示引导。默认设置项。
・ handle as ordinary forms:以一般形式处理。Burp 通过你配置的信息和自动填充规则,用处理其他表单的方式来处理登陆表单。
・ automatically submit these credentials:自动提交自定义的数据。开启后burp遇到登录表单会按照设定的值进行提交。
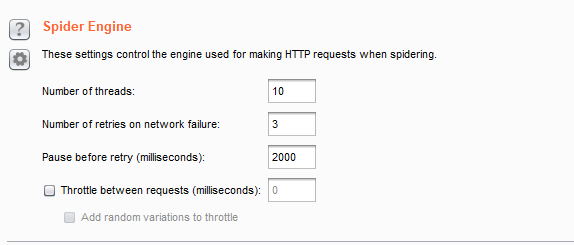
Spider Engine(蜘蛛引擎):
・ Number of threads - 设置请求线程。控制并发请求数。
・ Number of retries on network failure - 如果出现连接错误或其他网络问题,Burp会放弃和移动之前重试的请求指定的次数。测试时间歇性网络故障是常见的,所以最好是在发生故障时重试该请求了好几次。
・ Pause before retry - 当重试失败的请求,Burp会等待指定的时间(以毫秒为单位)以下,然后重试失败。如果服务器宕机,繁忙,或间歇性的问题发生,最好是等待很短的时间,然后重试。
・ Throttle between requests:在每次请求之前等待一个指定的延迟(以毫秒为单位)。此选项很有用,以避免超载应用程序,或者是更隐蔽。
・ Add random variations to throttle:添加随机的变化到请求中。增加隐蔽性。
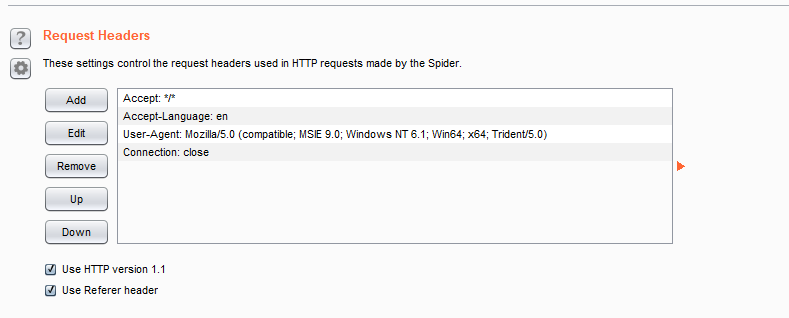
Request Headers(请求头设置):
・ Use HTTP version 1.1 :在蜘蛛请求中使用HTTP/1.1,不选中则使用HTTP/1.0.
・ Use Referer header:当从一个页面访问另一个页面是加入Referer头,这将更加相似与浏览器访问。
从篇幅来讲,大家也应该可以看出来Spider这个功能的强大,所以在网上各大教程说明上都讲"慎用"2333.
以上便是Spider基础功能的简单介绍,大家一起学习一起进步吧(^v^)。