张学程 / PingCAP 核心开发工程师,前网易游戏高级开发工程师。
目前主要从事 TiDB-Tools 的设计与开发工作,专注于数据库、分布式等技术领域。
前言
大家下午好!我叫张学程,现在是 PigCAP 核心开发工程师。主要做 TiDB-Tools 设计和开发的工作,之前也在网易游戏做一些手游开发。首先感谢一下主办方,很开心今天给大家做这个分享。
本次分享将从这3个方面来介绍 TiDB-Tool Golang 开发实践:
一、TiDB 与 TiDB-Tools 简介
二、 DM 设计与开发
三、Golang 实践与心得
一、TiDB 与 TiDB-Tools 简介
TiDB-Tools 是 PingCAP 开发的 TiDB 生态工具集,主要包括 DM (Data Migration) 、TiDB-binlog、lightning 等。本次分享将主要以 DM 为例,介绍我们使用 Golang 开发 TiDB-Tools 的一些实践经验与心得体会。
TiDB 简介
现在开始我们今天的主题,首先我给大家简单介绍一下 TiDB 和 TiDB-Tools。首先,TiDB 是开源的新一代分布式关系型 NewSQL 数据库,它既支持计算能力的扩展,也支持存储资源的拓展。比如说业务增长以后,原来单机性能不够了,如果使用 TiDB 的话,基本上只需要加机器就可以解决这个问题。
另一个特点就是说可以支持故障自恢复和异地多活,这里使用的 Raft 算法,可以保证多副本之间的一致性,故障时自动选举出一些新的主副本继续提供服务,这个过程是很快的,基本上不用人为去处理,可以支持数据中心的异地多活。还有一致性的分布式事务,和传统使用中间件的方式很不一样,如果使用中间件想做跨分片的事务就比较繁琐,但如果使用 TiDB,它就原生支持了分布式的事务。最后一个主要特点就是高度兼容 MySQL,如果原来是针对 MySQL 写的应用,一般只需要改一下连接地址然后连接到 TiDB 就可以了,另外 MySQL 有很多周边的生态工具,这些都是可以直接拿过来在 TiDB 上使用的。

TiDB-Tools 介绍
刚才介绍了 TiDB,我再简单介绍一下 TiDB-Tools,其实它是很多工具组成的一个工具集,我这里简单提一下其中的三个:
第一,DM,它也就是接下来会重点讲的一个工具,主要是做 MySQL 数据迁移和同步的工具,这个工具主要特点就是说把原来 MySQL 的数据用全量或者增量的方式同步到 TiDB 这边,方便原来在 MySQL 上的业务的迁移。这样做到的效果就是可以继续把原来 MySQL 当主库,先把 TiDB 当从库使用一段时间,自己觉得稳定了或者已经比较熟悉以后,再真正把业务全部贴到 TiDB 这边来。
第二,TiDB-Binlog,刚才讲的 DM 其实是从 MySQL 迁移数据到 TiDB,而 TiDB-Binlog 是把数据从 TiDB 这边迁移出去或者是备份出去的,将 TiDB 数据实时同步到MySQL,Kafka 或者其它 TiDB。我们也提供 Binlog 格式解析的开发包,可以针对自己需求使用这个开发包同步到各种类型的系统中去。
第三,TiDB-Lightning,这个工具也是导入的工具,但是传统的 SQL 导入方式,速度不是很理想,就是说它可能要像正常 SQL一样按那个方式来执行,Lightning 这个工具可以把 SQL 文件转成 KV 的形式后直接传到存储引擎那去,跳过上面计算引擎那一部分,这样速度会比较快,我们内部测试基本上大概有10倍以上的提升,然后它现在可以支持mydumper 数据格式作为导入数据源,我们近期也在做一些 csv 等格式的支持。
二、DM 设计与开发
DM 是什么?
前面简单介绍一下 TiDB 和 TiDB-Tools。现在进入第二部分就是 DM 的设计和开发实践。首先再讲一下,DM 是什么,我们之前有两个工具,一个工具叫 loader 一个叫 syncer,这两个工具是做全量导入和增量实时同步的,但是这两个工具其实有不少的问题,就是说它们一个上游 MySQL 就对应一个 loader 或者是一个 syncer,如果 MySQL 多的时候,运维和部署包括各种管理都是比较麻烦的。

另外一个比较困难的事情就是因为各个节点之间是没有联系的,假设原来 MySQL 做分库分表,现在想统一到同一个 TiDB,这时如果上游表做一些变更,因为他们之间没有协商,可能由于一些数据和表结构的不匹配造成很多问题,这里后面会细讲一下。
DM 主要有这样一些特性,包括使用 ansible 部署和运维管理,同时支持全量、增量或者自动全量加增量一起做,也就是说部署一套 DM 可以同时跑很多的同步任务,对刚才提到的合库合表有比较完善的支持。另外它有很多过滤的方式,因为同步数据过程中不是说所有的数据可能都是下游需要的,这部分后面也会细讲。
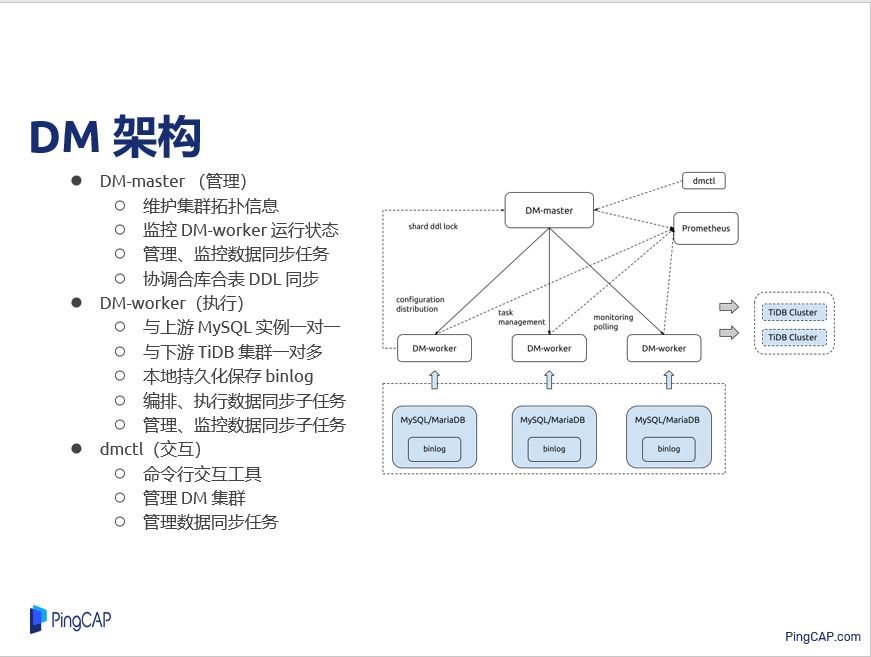
DM 架构
我们来简单看一下 DM 的架构,DM 主要由三个组件组成,主要包括管理 DM-master,这里还有一个 DM-worker、还有做集群管理的 DM-ctl,DM-master 管理这些 DM-worker 的节点,然后管理整个数据同步任务,监控同步状态,它在合库合表的时候会协调 DDL 的执行。
DM-worker 主要是做实际的数据同步任务,它一个节点对应上游一个 MySQL 实例,下游可以多对对,一个上游 MySQL 可以同步到不同的下游去,也可以多个上游 MySQL 合并同步到同一个下游 TiDB, DM-worker 会做实际数据同步任务,编排、执行数据同步子任务、管理、监控数据同步子任务,DM-ctl 只是命令交互工具,可以执行一些指令管理这个集群,也可以管理同步任务的情况。
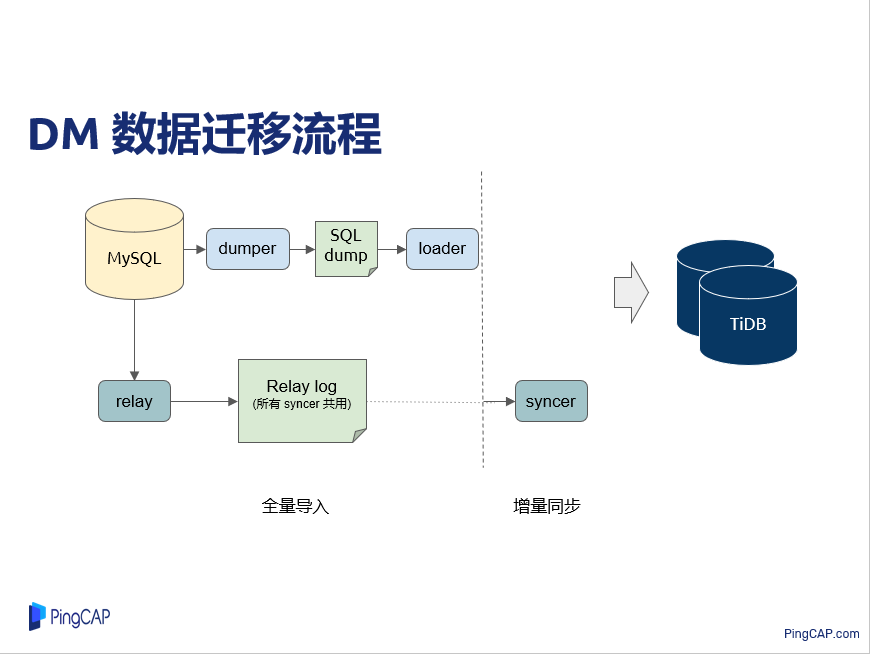
DM 数据迁移的流程
下面要讲的是 DM 数据迁移的流程,前面提到这里包括两个部分:一个部分做全量的同步,另一部分是做增量的同步。全量同步这里主要讲的都是 DM-worker 内部的,可以叫做处理单元,分别有 dumper、relay、loader 以及 syncer。做全量同步的时候,dumper 单元连到上游 MySQL 然后把数据给 dump 成 SQL 文件,包括表结构还有实际的数据文件,然后 loader 就把它加载导入到下游 TiDB。
做增量同步的时候,relay 单元会连到 MySQL 上面,就像 MySQL 主从复制的形式是一样的,它其实在这里扮演的角色就是 MySQL 从库,让它从 MySQL 那里读 binlog 回来,以 relay log 方式写在自己本地,后面做增量同步的时候就是多个 syncer 读取本地的 relay log 后同步到下游 TiDB。
这个与传统 MySQL 主从复制有一点区别,MySQL 的主从复制,就是它自己作为一个节点,它把 binlog 读回来,然后它执行以后,就会把它删除了。但是一个 MySQL 的数据可能会同步到不同的 TiDB 去,或者只是同步一部分,剩下的部分想再同步的时候,在 DM 里都可以重用这一份的 relay log,而不是再去上游 MySQL 重新拉 binlog 回来。
DM 数据迁移的流程-loader并发
再看一下 DM 做数据同步时并发相关的东西,如果只保证数据同步,其实比较简单,也比较容易保证正确性,但是这样效率就不是很好。在 DM 里,首先全量导入的时候,在loader 那部分做并发简单是 SQL 文件级别的并发,上面 dumper 的时候其实一个表可以按指定文件大小拆成不同的 SQL 文件给 dump 出来,这边做 loader 导入的时候,内部就有一个 worker 池,每个 worker 各自独立地读 SQL 文件导入 TiDB,这个主要就是 dump 出来的时候,其实是以上游某一个时刻静态的数据,它 SQL 文件之间其实没有交叠的,这样同步下游去其实是不会冲突的,先后顺序并不是重要的,所以就可以做一个并发。

DM 数据迁移的流程-syncer并发
然后看一下 syncer 内部并发的过程,syncer 相比 loader,它从上游拉一个 binlog 回来的时候,这个过程中其实 binlog 是一个流的形式,上游 MySQL 写一个 binlog 事件,下游就读到一条,即使你拿到完整之前已经写过的binlog 文件,因为在解析 binlog 之前你是不知道下一个 binlog 事件是在文件里面哪一个位置的,所以这里只能以一个顺序的方式给它做解析,但是解析完之后,每个 binlog 事件作为一个 job,就可以做并行的分发,然后在 worker 池里面可以并行消费。
但如果一个 DDL 操作其实会变更表结构的,这样其实必须保证原来老的表结构 DML 事件都已经做成功,它才能做。所以这里其实是一个同步点,前面可以并行,后面也可以并行,当在 DDL 事件自身其实必须是等前面做完以后它才能做。即使是 DML 其实有些情况下,它可能改主键之类的,如果改主键其实主键会做一个 update 的时候,它可能是一个条件,如果改主键,如果乱序其实可能就会做得不对,这里其实略有一点隐讳,就不细讲,这里其实内部有一些机制来检测这个因果关系,然后确保它的正确性。

DM 合库合表数据同步
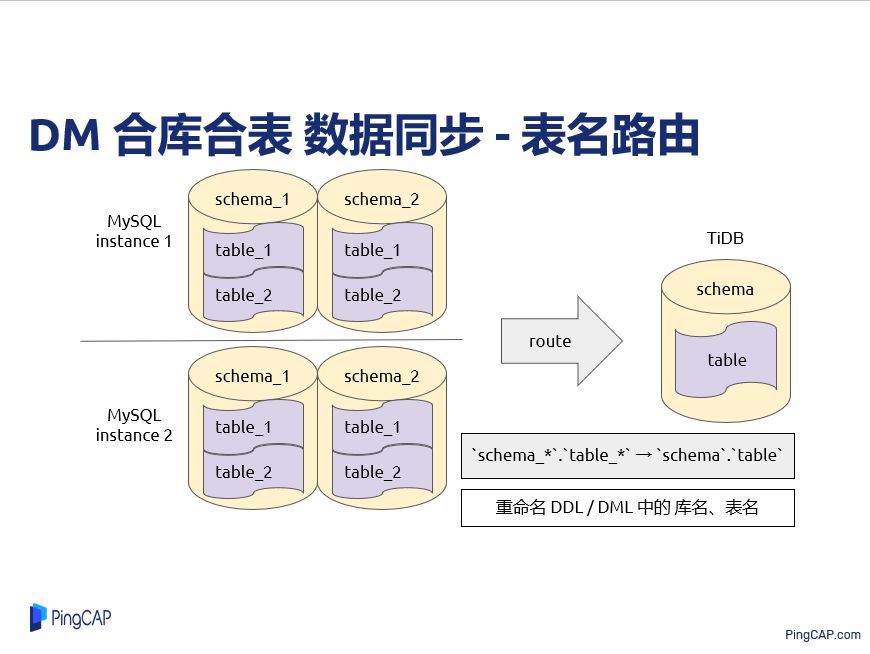
DM 具体功能是怎么做的?首先是合库和表,传统 MySQL 由于一些单机性能的限制,数据大了以后就会做分库分表,TiDB 其实自己就可以做水平扩展,一般我们只需要弄一个 TiDB 集群就可以了,把 MySQL 切到 TiDB 过程就会把原来那些分库分表然后给合库合表到一张表或者一个库里面。
这里就有一个例子就是说上游是有两个 MySQL 实例,每个实例有两个逻辑库,每个逻辑库里面有两张表,总共这里是有8张表,8张表都要同步到下游 TiDB 同一张表里面,8张表在不同实例上不同逻辑库上,它的名字也不同,首先拿到同一张 TiDB 表里面,第一个要做就是说这个表要改一下,要做一个路由,这个其实是比较简单,就把一些DDL和DML根据这样一些匹配规则做一个重命名就可以了。
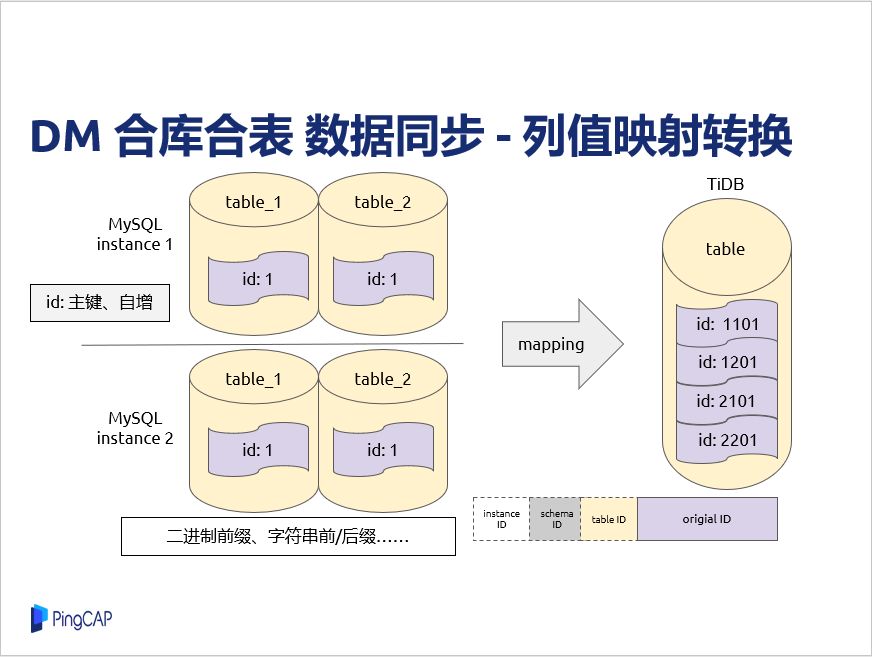
再来看一下同步过程中,还有一个问题就是原来做分布分表的时候,很多时候可能会加一些 ID 列,它可能是主键,有自增属性的这样一些情况。假如有4张表,因为他们是各自独立的时候,做自增的时候,可能有ID值是相同的情况,同步到下游去,另外他们主键是一样的,同步可能因为有些顺序的关系,同步到下游 TiDB 就只有一条记录,具体那个记录值是对应上面哪一个,这个就看同步数据。
我们强调这里是数据不一致,这样其实在 DM 里面有一个功能就是列值映射转换 ,对于这种ID,他如果是 bigint 类型,它一般来说它64位,他可能自增,但一般不会使用全部的 64 位,这时候其实你可以拿出一部分位来就可以标志来自哪一个 MySQL 实例,来自上游实例哪一个逻辑库还有原来对应哪一个表,通过这样加二进制前缀,其实同步到下游去,其实给它们的值就都是不一样了。就像在这个例子里面,它同步过去,数据就不一样。另外一些数据类型,其实也可以加一些前缀或者后缀这些方式,这里就是说有一个限制,如果在列值映射的数据在业务直接使用,肯定不能这么做,所以这里说它有一些缺陷。
再来看一下做合库表的时候怎么做 DDL 同步。这里先举个例子,假设说上游有两个MySQL 实例,他们要同步到同一个 TiDB 去,我们也提到数据是以 binlog 流形式过来的,首先有一部分是表结构变更前的 DML,然后有一些表结构变更的操作,然后是新表结构 DML,同样另一个 MySQL 也是这样的情况。当然上游在表结构变更或者数据同步过程中。在这个例子里,实例 1 的DDL 过来以后就把表结构变更掉了,但是这个时候其实还有些实例 2 的 DML还没有消费完,这时候过来以后,你再尝试同步到下游,它其实就是匹配不上,这就存在这么一个问题需要解决。
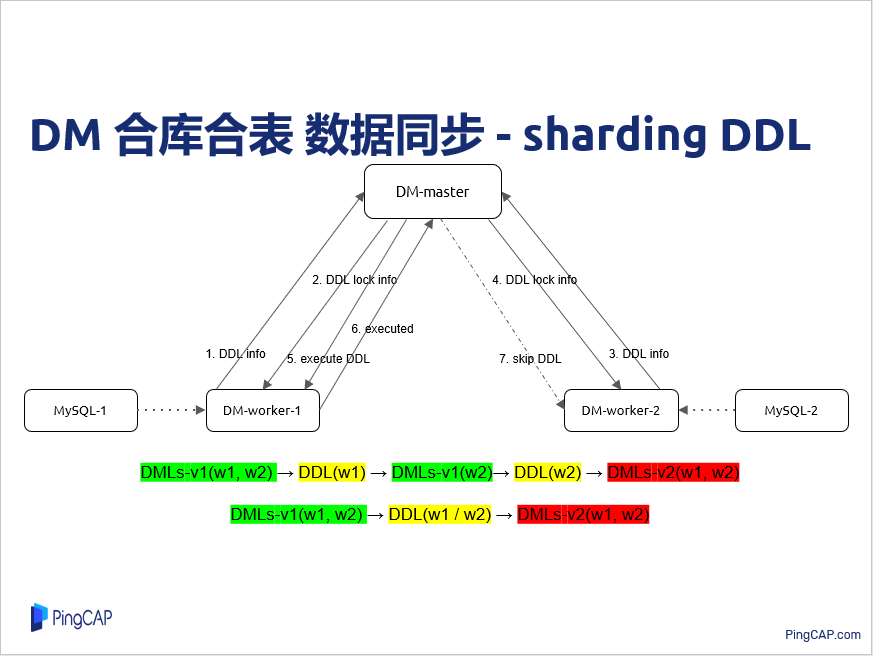
我们解决方案其实也是借助锁的概念来做一个同步,假设刚才那个例子,MySQL 实例 1 收到DDL之后,首先把 DDL 信息报到 DM-master 这个组件,DM-master 就看一下这个 DDL 之前是不是已经在这里注册过了,如果没有注册,就给他注册一下,然后创建一个锁,这个把这个锁信息再发到 DM-worker,DM-worker 说我已经遇到 DDL,但别的实例还没有遇到 DDL,现在我不能做这个表结构的变更,因为可能有些老的数据没有消费掉,这时候它把同步任务给挂起。刚才提到其实可以做多个同步任务,但是这里只是挂起当前这个同步任务,其它同步任务是不受影响的。
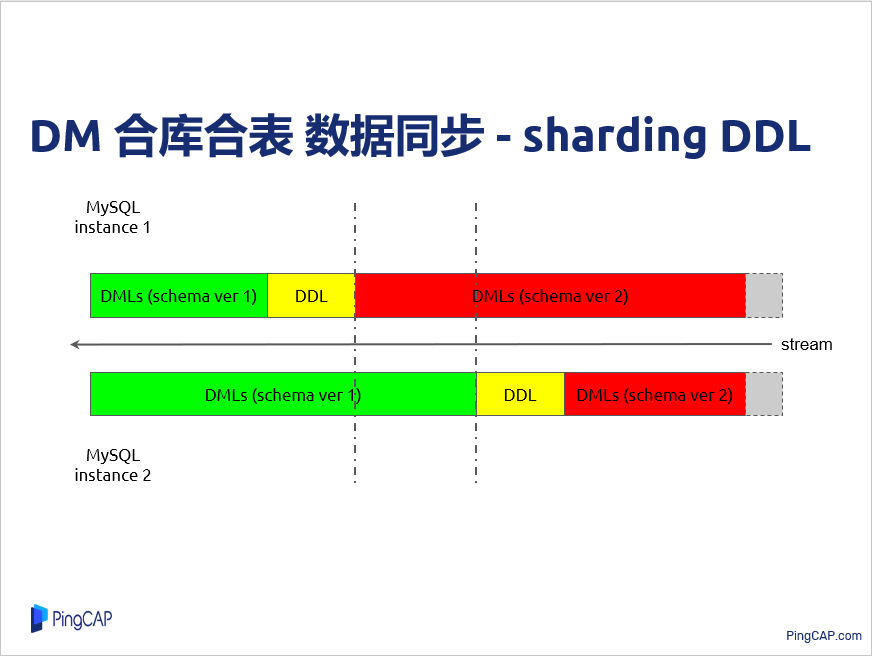
这样 MySQL 实例 2 继续消费原来老的 DML,等老的 DML 消费完以后,它一样把 DDL 信息发到 DM-master,原有 DDL 对应的锁已经存在了,它直接把锁的信息返回 DM-worker,同时它自己根据启动任务结构,就可以知道锁对应上游的 MySQL 实例都已经遇到 DDL,说明这个老的表结构数据已经消费完,就可以做实际变更表结构的操作,就会通知第一个过来注册的 DM-worker,让它做 DDL 变更语句,等它做成功以后,也把执行信息返回给 DM-master,这样它就可以继续同步。
这样就让其它 DM-worker 实例简单地把这个DDL跳过,因为下游只需要变更一次就可以了,做重复 DDL 就没有意义了,这样就相当于把原来不同 DML 有交叠的情况变成这样一个顺序的情况,其实这里就是一个锁的同步,也就和线程之间的同步也是差不多,只不过实际同步的时候是有很多细节要处理,尤其是一个 MySQL 内部其实还有很多那个表,各个表之间又有 DDL 的情况。
DM 数据同步过滤
再来看一下 DM 数据同步过滤功能,做数据库同步的时候,有一个比较常见的需求就是说原有上游还有很多库、表,但是只需要同步一部分给下游,或者说刚才提到 binlog 的情况,并不是所有 binlog 事件都要做,还有包括某一些自己符合某个规则的 SQL 就不需要做,这三种不同过滤规则在 DM 内部都是有支持的。看这里这个例子其实就是说上游有这么五个类型的 binlog 的事件,但可能说它不需要分库分表同步到下游的时候,某一个上游分片 drop 操作,可能说不希望把下游整个库给 drop,这时候可以简单配一些过滤规则把 drop 过滤掉,就不会把整个库给 drop 掉了。

这其实相对来讲比较简单,这里部分其实是开源的,这部分比较简单。
DM 监控
然后还有一个就是说做同步系统比较关心的问题就是同步过程中有没有发生一些问题,我们用 prometheus + grafana 来做监控,这个可以看到同步过程中耗时还有什么错误,同步延时情况都是可以看到,然后这两个组件都是开源的,其实这个东西还是比较好用,特别对一些分布式系统,如果不能监控到内部的状态,你想调试或者查看某些信息的时候就比较麻烦,通过这些支持其实还是比较好的。

三、Golang 实践与心得
我简单介绍一下 Golang 实践与心得,这部分其实比较主观的,大家见仁见智。
GO-简洁,好review

首先Go 最吸引我的一点是它的 简洁!方便做代码评审。我写C++的时候,开始觉得这种底层的东西自己可以很精细做一些控制,感觉写代码的时候很爽,当然实际并不是控制得那么好,但是当你看别人代码的时候,有时候你怀疑让他写这个是不是C++,主要是它的范式比较多,可能不同人写出来风格就会差别很多,然后还有一些牛人写的看起来可能就比较难懂,这不是很适合做代码评审。
还有Python的这个语言,它最大的特点就是灵活,其实这里写的时候自己很爽,但是看别人代码的时候也就不那么爽,特别有些需求变更的时候,可能有时候为了偷懒,有些人改得比较随意,这个前期改一两次没有问题,但是后面越改越多就是很麻烦,也不是要黑C++和Python,这两个语言其实我都比较喜欢,但我今天其实就是讲讲它们的不好而不是好。
右边是有人做的一些开源项目bug的统计情况,这里正数就是代码 bug 情况高于平均值,负就是低于平均值,你们看一下C++、Python其实都是比较容易出现bug,特别是C++挺多的,这个Go相对好很多,不那么容易出Bug。但是也不少人也有一些吐槽,说 Go 写这也不行那也不行,还有一些它编译时的限制也是比较严格的,但这并不是坏事,这样其实写出来以后,特别团队人多的时候,然后大家水平确实有些差别,当然用Go 写出来大家风格比较统一,代码很直白,你做代码评审的时候直接在大脑里面执行代码的流程其实都是可以的,这样比较容易查Bug出来。

有些大佬能够写出来很炫酷出来的语言特性出来的时候,他写得享受,但是你看得可能不是很舒服,然后这边有一个引用的一个话就是说程序本来应该写方便人们阅读的,它顺便可以被机器执行来做一些事情,我的感受是大家都是写程序,程序员何苦难为程序员,写得让别人看着好,你自己看着舒服就可以了。
GO-并发,真方便
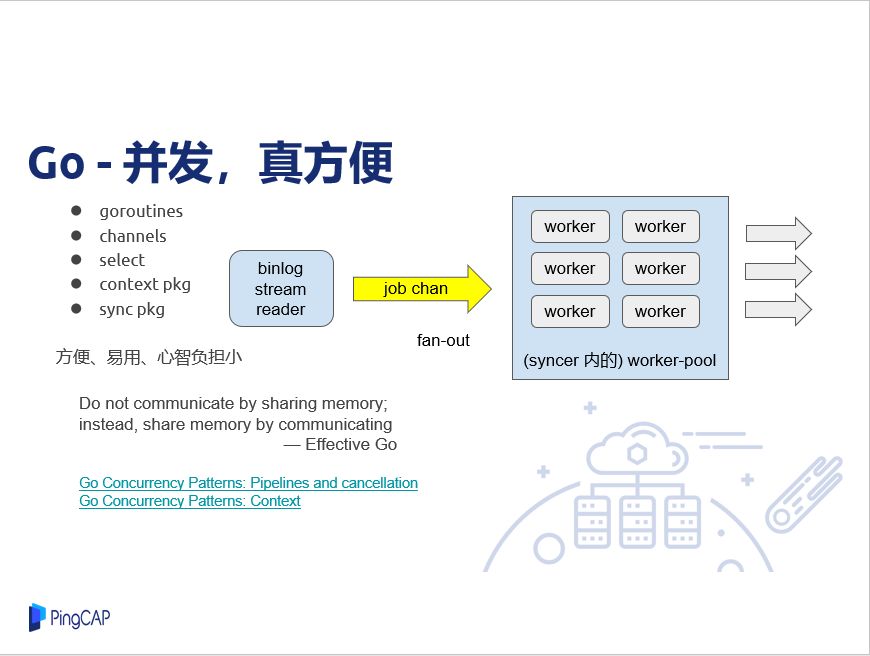
Go另外一个特点是写并发很方便,这个相比其它语言是省了很多事情,少了很多心智负担,语言层面有一些协程、chan、select,另外,context、sync 这两个包也简单、强大。可以看一下 DM 的 syncer 内部其实也用到并发的模型,刚才也提到过,这里做binlog 解析的时候,其实它是一个协程做,然后拆成 job,分发到 job chan里面,下面那些都是可以并行其它 job 出来,然后做消费,这一些就是简单的fan-out模型, Go 并发很推荐这两篇博客,基本各个地方用起来都是比较顺畅。
GO-调试、分析、挺好用
再来讲一个,代码写是写好了,但是调试肯定是需要,上线的时候出bug才是常态,所以这个时候调试Go在这方面还是做得比较好的。比如说写并发写得爽,其实在编译或者测试都可以探测到,如果已经上线,通过PProf可以简单看到内部状态,我们内部也是用它查一些 deadlock 的一些情况。

GO-官方实践
最后,推荐一下在写 Go 代码的时候,可以参考官方的 Effetive Go 来。代码评审的时候,就参考官方的 Go Code Review Comment。

Q&A
问:我想请教一下刚才看合库合表数据同步PPT上面写的是DDL是传到DM master,DM master和DM-worker之间是有中心持续下发DDL吗?
张学程:这里做实际任务,它遇到DDL,它会把DDL发到这里去,之所以把DDL发到这里去,其实是说做一个标识,因为可能其它一些到DDL顺序不一样,这时候可以探测到这个错误,做上游分片出来的DDL必须一样的话,有个分片先加一个A字段,另一个分片是加了B字段,他们两个顺序乱序,效果不能保证。
问:worker和master是以RPC方式做吗?
张学程:就是RPC方式做。
问:是建立什么连接?
张学程:这里用的 gRPC stream 的方式。
问:我看上面好像全部创新过程,master跟Worker怎么保障DDL是一致的?
张学程:这里是分两个部分,你是说DDL还是DDL info?
问:DDL info。
张学程:DDL info是Master内部维护的,第一次DDL先到达的时候,才会构建DDL info的信息来,然后后面到同一条DDL,其它worker注册过了,它直接把这个发回过去就可以了。