深度神经网络的聚合残差变换

摘要
我们为图像分类提供了一个简单的高度模块化的网络架构。我们的网络通过重复构建块来构造,该构建块聚合具有相同拓扑的一组变换。我们的简单设计导致均匀的多分支架构,只有几个超级参数设置。该策略公开了一种新的维度,我们称之为“基数”(变换集的大小),除了深度和宽度的尺寸之外,还为本要素。在ImageNet-1K数据集上,我们经验表明,即使在保持复杂性的限制条件下,增加的基数能够提高分类准确性。而且,当我们增加容量时,增加的基数比更深或更宽更加宽。我们的模型名为Resnext,是我们进入ILSVRC 2016分类任务的基础,我们确保了第二个地方。我们进一步调查了ImageNet-5K集合和Coco检测集的Resnext,也显示出比其Resnet对应物更好的结果。代码和模型在线公开提供1。
1介绍
视觉识别的研究正在从“特征工程”到“网络工程”[25,24,44,34,36,38,14]的过渡。与传统的手指特征(例如,SIFT [29]和HOG [5])相比,由大规模数据的神经网络学习的特征需要在训练期间需要最小的人类参与,并且可以转移到各种识别任务[7,10,28]。尽管如此,人类努力已经转移到设计更好的网络架构以获得学习陈述。
设计架构越来越困难,越来越多的超参数(宽度2,过滤尺寸,步幅等),尤其是当有许多层时。 VGG-Net [36]展示了构建非常深网络的简单而有效的策略:堆叠相同shape的组件。该策略继承于Resnet[14],Resnet堆叠了相同拓扑的模块。这个简单的规则减少了超参数的自由选择,深度揭示了神经网络中的基本维度。此外,我们认为这条规则的简单性可能会降低过度调整超参数到特定数据集的风险。通过各种视觉识别任务[7,10,9,28,31,14]并通过涉及语音[42,30]和语言[4,41,20]的非视觉任务已经被证明的VGGNET和RESNET的鲁棒性。
与VGG-nets不同,Inception模型系列[38,17,39,37]已经证明,精心设计的有着较低理论复杂性的拓扑结构足以实现令人信服的精确率。随着时间的推移,Inception模型已经进化[38,39],但重要的常见属性是分裂变换合并策略。在Inception模块中,输入被分成几维低维的输入(按1×1卷积),由一组专用过滤器(3×3,5×5等)转换,并通过连接合并。可以表明,这种架构的解决方案是在高维输入的单个大网络层(例如,5×5)的解空间的严格子空间。预计Inception模块的分流变换合并行为将接近大而致密层的代表性,但是具有相当较低的计算复杂性。
尽管准确性良好,但Inception模型的实现已经伴随着一系列复杂的因素——过滤器数量和大小是为每个单独的变换定制的并且模块是分阶段自定义的。虽然这些组件的仔细组合产生了优秀的神经网络结构,但通常不清楚如何将初始化架构调整到新的数据集/任务,特别是当有许多因素和超参数时要设计。
在本文中,我们提出了一种简单的架构,它采用VGG / Resnets的重复层策略,同时以简单,可扩展的方式利用分流交换合并策略。我们网络中的模块执行一组变换,每执行一个低维输入时,其输出通过求和聚合。我们追求这种想法的简单实现 - 要汇总的转换是所有相同的拓扑(例如,图1(右))。这种设计允许我们扩展到任何大量的转换,无需专门设计。我们追求这种想法的简单实现-要汇总的变换是所有相同的拓扑(例如,图1(右))。这种设计使我们能够扩展到没有专门设计的大量变换。
有趣的是,根据这种简化,我们的模型具有另外两种等同形式(图3)。图3(b)中的重构类似于Inception-ResNet模块[37],其中它连接多个路径;但是我们的模块与所有现有的Inception模块不同,因为我们所有路径都共享相同的拓扑,因此可以容易地隔离路径的数量作为要调查的因素。在更加简洁的重构中,我们的模块可以由Krizhevsky等人重塑。的分组卷积[24](图3(c)),然而,这一点被制定为工程妥协。
我们经验证明,即使在维持计算复杂度和模型大小的限制条件下,我们的聚合变换也优于原始的Reset模块 - 例如,图1(右)旨在保持图1的浮点复杂性和参数的参数数量。1(剩下)。我们强调,虽然通过增加容量(进展更深或更宽)的方法相对容易地提高准确性,但在维持(或降低)复杂性的同时提高精度的方法是罕见的。
我们的方法表明,除了宽度和深度之外,基数(变换集合的大小)是一个具有中心重要性的具体的、可测量的维度。实验表明,增加基数是一种比增加深度或增加宽度更有效的获得准确性的方法,特别是当深度和宽度开始为现有模型带来递减的回报时。
我们的神经网络,命名为ResNeXt(暗示下一个维度),在ImageNet分类数据集上优于ResNet-101/152[14]、ResNet200[15]、Inception-v3[39]和Inception- ResNet -v2[37]。特别是,101层的ResNeXt能够达到比resnet - 200[15]更好的精度,但复杂度只有50%。此外,ResNeXt展示的设计比所有Inception模型都要简单得多
ResNeXt是我们提交ILSVRC 2016分类任务的基础,我们在该任务中获得了第二名。本文进一步评估了ResNeXtona larger imagenet-5kset和COCO object检测数据集[27],始终显示出比ResNet同类数据集更好的准确性。我们希望ResNeXt也能很好地推广到其他视觉(和非视觉)识别任务。
2相关工作
多分支卷积网络。Inception模型[38,17,39,37]是成功的多分支架构,其中每个分支经过仔细定制。 RESNET [14]可以被认为是一个分支网络,其中一个分支是恒等映射。深度神经决策森林[22]是具有学习拆分功能的树模式的多分支网络。
分组卷积。使用分组的卷积可以追溯到AlexNet论文[24],如果不是之前。Krizhevsky等人提供的想法 [24]用于将模型分布在两个GPU上。 Caffe [19],Torch[3]和其他框架支持分组的卷积,主要用于AlexNet的兼容性。据我们所知,有关利用分组卷积的一点证据,以提高准确性。分组卷积的特殊情况是明智通道的卷积,其中组的数量等于渠道数量。明智通道的卷积是[35]中可分离卷积的一部分。
压缩卷积网络。分解(在空间[6,18]和/或通道[6,21,16]水平)是一种广泛采用的技术,以减少深卷积网络的冗余并加速/压缩它们。 Ioannou等人[16]呈现用于减少计算的“根”-模式网络,并且通过分组的卷积来实现根部的分支。这些方法[6,18,21,16]显示了具有较低复杂性和更小的模型尺寸的精度的优雅妥协。我们的方法代替压缩,而不是压缩,这是一个经验呈现更强大的代表性的架构。
集合。平均一组独立培训的网络是提高准确性的有效解决方案[24],广泛采用识别竞争[33]。 VEit等人 [40]将单个RESET解释为较浅网络的集合,从Reset的想加表现导致了[15]。我们的方法利用添加了一组变换。但是,我们认为它是不精确的,以便将我们的方法视为合奏,因为要聚合的成员是联合训练,而不是独立训练的。
3方法
3.1模板
我们采用高度模块化的设计,遵循VGG/ResNets.我们的网络由堆叠的残差块组成。这些块具有相同的拓扑,并受到VGG / Resnets的两个简单规则的影响:(i)如果产生相同大小的空间映射,则该块共享相同的超参数(宽度和滤波器大小),以及(II )每次当空间映射下采样因子为2时,块的宽度就乘以2。第二条规则确保计算复杂性,按照浮点操作(浮点操作中,在#中乘法添加)对于所有块大致相同。
通过这两个规则,我们只需要设计模板模块,并且可以相应地确定网络中的所有模块。因此,这两个规则极大地缩小了设计空间,让我们专注于一些关键因素。由这些规则构建的网络在表1中。

3.2 回顾简单的神经元
人工神经网络中最简单的神经元执行内积(加权和),这是由全连通和卷积层完成的初等变换。内积可以看作是一种聚集变换形式:

其中x=[x1,x2,…,xD]x=[x_1,x_2,…,x_D]x=[x1?,x2?,…,xD?] 是神经元的一个具有DDD通道的输入向量,并且wiw_iwi?是一个卷积核第iii通道权重。这个操作(通常包括一些输出非线性)被称为“神经元”。参见图2。

可以将上述操作理解为分裂、变换和聚合的组合。
(i) 分割:将向量xxx切为低维输入,其中为单维子空间xix_ixi?。
(ii)变换:对低维表示进行变换,并对其进行简单缩放:wixiw_ix_iwi?xi?。
(iii)聚合:所有输入的变换由公式(1)聚合
3.3 聚合变换
考虑到以上对单个神经元的分析,我们考虑用更一般的函数代替初等变换(wixiw_ix_iwi?xi?),它本身也可以是一个网络。与原来增加深度维度的“网络中的网络”[26]相比,我们的“神经元中的网络”沿着一个新的维度扩展。
形式上,我们将聚合转换表示为
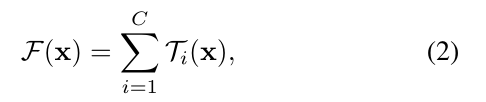
其中Ti(x)T_i(x)Ti?(x)可以是任意函数。类似一个简单的神经元,TiT_iTi?应该将xxx投影到一个(可选的低维)输入,然后将其变换
在Eqn.(2)中,CCC是要聚合的转换集合的大小。我们把CCC称为基数[2]。在Eqn.(2)中CCC的位置与Eqn.(1)中的DDD相似,但CCC不必等于DDD,可以是一个任意的数。虽然宽度的维度与简单转换(内积)的数量有关,但我们认为基数的维度控制更复杂转换的数量。我们通过实验表明基数是一个基本的维度,可以比宽度和深度的维度更有效。
在本文中,我们考虑了一种简单的设计变换函数的方法:所有的TiT_iTi?具有相同的拓扑。这扩展了vgg风格的策略,即重复相同形状的层,这有助于隔离一些因素并扩展到任何大量的转换。我们将个别的转换Ti设置为瓶颈型架构[14],如图1(右)所示。在本例中,每个TiT_iTi?中的第一个1×1层产生低维输入

图3.等价的ResNext的构建块。
(a):聚合的残差变换,与图1右部分相同
(b):相当于(a)的一个块,实现为提前串联
(c):等价于(a,b)的一个块,实现为分组卷积
粗体文本的符号将突出显示重新构建的改变。一个层表示为(input channels,filter size,output channels)
Eqn.(2)中的聚合变换作为残差函数(图1右):
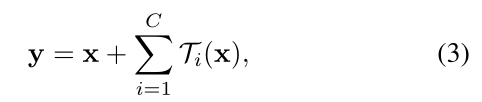
其中yyy是输出.
与Inception-ResNet的关系.
一些张量处理表明,图1(右)中的模块(图3(a)中也展示了)等价于图3(b)。图3(b)与Inception-ResNet[37]的块相似,它在残差函数中涉及分支和串联。但与所有Inception或Inception- ResNet模块不同的是,我们在多个路径之间共享相同的拓扑结构。我们的模块需要最少的额外努力设计每个路径。
与分组卷积的关系。使用分组卷积[24].4的表示法,上面的模块变得更加简洁。图3?说明了这种重新构建的结构。所有的低维输入(第一个1×1层)都可以用一个更宽的单一层代替(如图3?中的1×1, 128-d)。分裂本质上是由分组卷积层完成的,当它把输入通道分成组时。图3( c)中的分组卷积层进行了32组卷积,其输入和输出通道为四维。(这里将输入128通道分为32组,每组4个通道)
分组的卷积层将它们串联起来作为层的输出。图3?中的区块与图1(左)中的原始瓶颈剩余区块相似,但图3?是一个较宽但连接稀疏的模块。

上图左右两边的结构是等价的。
我们注意到,只有当块具有深度≥3时,重新制定才会产生非平凡拓扑。如果块具有深度= 2(例如,[14]中的基本块),则重新制定导致宽阔的密集模块。看到图4中的图示。
讨论。我们注意到,尽管我们提出了重新制定(图3(b))或分组卷积(图3(c)),但这种重新制定并不总是适用于等式3的一般形式。(,例如,如果转化Ti是任意形式,是异源的。我们选择在本文中使用同构的形式,因为它们更简单和可扩展。在这种简化的情况下,图3(c)的形式的分组卷积有助于简化实现。
3.4 模型能力
我们在下一节中的实验将表明,在保持模型复杂性和参数数量的情况下,我们的模型可以提高精度。这不仅在实践中很有趣,更重要的是,参数的复杂性和数量代表了模型的固有容量,因此通常被研究为深层网络的基本属性[8]。
当我们在保持复杂性的同时评估不同的基数时,我们希望最小化对其他超参数的修改。我们选择去适配BottleNeck的宽度(图1右边的4-d),因为它可以与模块的输入和输出隔离。这种策略对其他超参数(块的深度或输入/输出宽度)没有引入任何变化,因此有助于我们关注基数的影响。
在图1(左),原始的ResNet BottleNeck Block[14]有25664+336464+64*256?70K的参数并且成正比的浮点数(在相同的特征图大小上)。对于BottleNeck宽度d,我们的模板在图1有:
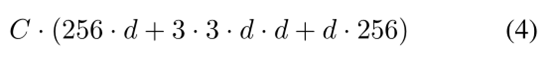
当C=32C=32C=32和d=4d=4d=4时,等式(4)约等于70K。表2显示了基数CCC和瓶颈宽度ddd之间的关系。

因为我们采用3.1节的两个规则,上述近似等式在ResNet的BottleNeck Block和我们的ResNext之间的所有阶段都有效(除了子采样层,其中特征图大小发生变化)。表1比较了原始的ResNet-50和我们容量相似的ResNext-50。5我们注意到复杂性只能近似保留,但复杂性的差异很小,不会影响我们的结果。
4执行细节
我们的实现遵循[14]和公开可用的代码fb.resnet.torch [11]。在ImageNet数据集上,使用[11]实现的[38]的比例和纵横比增强,从调整大小的图像中随机裁剪出224×224的输入图像。除了那些增加的维度是投影(在[14]中的类型B),快捷方式是相同的连接。conv3、4和5的下采样是通过每个阶段第一个块的3×3层中的步长-2卷积来完成的,如[11]中所建议的。我们在8个图形处理器(每个图形处理器32个)上使用256个小批量的SGD。重量衰减为0.0001,动量为0.9。我们从0.1的学习率开始,用[11]中的计划表除以10,做三次。我们采用[13]的权重。在标记比较中,我们从一个短边为256的图像中评估单个224×224中心裁剪的误差
我们的模型是通过图3?的形式实现的。我们执行了BN标准化[17]在图3(c)的卷积之后。ReLU在每个BN之后立即执行,除了在添加到快捷方式之后执行ReLU的块的输出,如下[14]。我们注意到,当BN和ReLU如上所述被适当地处理时,图3中的三种形式是严格等价的。我们训练了所有三种形式,得到了相同的结果。我们选择通过图3?来实现,因为它比其他两种形式更简洁、更快。
5实验
5.1 在ImageNet-1K的实验
我们在1000级ImageNet分类任务上进行消融实验[33]。我们按照[14]构造50层和101层残差网络。我们只是用我们的块替换ResNet-50/101中的所有块。
标记。因为我们采用3.1节的两个规则,我们通过模板引用一个架构就足够了。例如,表1显示了由基数= 32、瓶颈宽度= 4d的模板构建的ResNeXt-50(图3)。为简单起见,该网络表示为ResNeXt-50 (32×4d)。我们注意到,模板的输入/输出宽度固定为256-d(图3),每次对要素图进行二次采样时,所有宽度都会加倍(见表1)。
基数与宽度。我们首先评估基数C和bottleneck宽度之间的权衡,保留表2中列出的复杂性。表3显示了结果,图5显示了误差对时期的曲线。与ResNet-50(上表3和左图5)相比,32×4d ResNeXt-50的验证误差为22.2%,比ResNet基线的23.9%低1.7%。随着基数C从1增加到32,同时保持复杂度,错误率不断降低。此外,32×4d ResNeXt的训练误差也比ResNeXt低得多,这表明增益不是来自正则化,而是来自更强的表示。
在ResNet-101的情况下也观察到类似的趋势(图5右侧,表3底部),其中32×4d ResNeXt101的表现优于ResNet-101的0.8%。虽然这种验证误差的改善小于50层情况,但训练误差的改善仍然很大(ResNet-101为20%,32×4d ResNeXt-101为16%,图5右)。事实上,更多的训练数据将扩大验证误差的差距,正如我们在下一小节中在ImageNet-5K集上显示的那样。
表3还表明,在保持复杂性的情况下,当bottleneck宽度小的时候以减少宽度为代价增加基数开始显示出饱和的准确性。我们认为,在这种情况下,继续缩小宽度是不值得的。所以我们在下面采用一个不小于4d的瓶颈宽度。


增加基数与更深/更宽。接下来,我们研究通过增加基数C或增加深度或宽度来增加复杂性。下面的比较也可以参考ResNet-101基线的2倍浮点运算来进行。我们比较了以下具有150亿次浮点运算的变体。(一)深入到200层。我们采用在[11]中实现的ResNet-200 [15]。㈡通过增加瓶颈宽度扩大范围。(三)通过加倍c来增加基数。

表4显示,与ResNet-101基线(22.0%)相比,复杂度增加2倍会持续降低误差。但是当更深(ResNet200,0.3%)或更宽(更宽的ResNet-101,0.7%)时,改善很小。
相反,相比增加深度或者宽度,增加基数C得到的结果更好。2×64d ResNeXt-101(即在1×64d ResNet-101基线上加倍并保持宽度)将top-1误差降低1.3%至20.7%。64×4d ResNeXt-101(即在32×4d ResNeXt-101上加倍C并保持宽度)将top-1误差降低到20.4%。
我们还注意到,32×4d ResNet-101 (21.2%)比更深的ResNet-200和更宽的ResNet101性能更好,尽管它的复杂性只有50%。这再次表明基数比深度和宽度更有效。
残差连接。下表显示了残差(快捷方式)连接的效果:
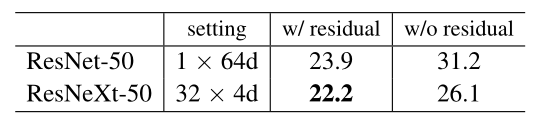
从ResNeXt-50中删除快捷方式会使错误增加3.9点,达到26.1%。从它的1497 ResNet-50对应物中删除快捷方式要糟糕得多(31.2%)。这些比较表明,剩余连接有助于优化,而聚合转换是更强的表示,这是因为它们始终比有或没有剩余连接的对应转换表现得更好。
执行。为了简单起见,我们使用Torch内置的分组卷积实现,没有特殊的优化。我们注意到这个实现是暴力的,并且不支持并行化。在NVIDIA M40的8个GPU上,表3中的32×4d ResNeXt-101训练每小批量需要0.95秒,而ResNet-101基线的0.70秒具有相似的浮点运算。我们认为这是合理的开销。我们期望精心设计的较低级别的实现(例如,在CUDA中)将减少这种开销。我们还期望CPU上的推理时间将呈现更少的开销。训练2×复杂性模型(64×4d ResNeXt-101)每个小批量需要1.7秒,在8个图形处理器上总共需要10天。
与最先进结果的比较。表5显示了ImageNet验证集的单作物测试的更多结果。除了测试224×224作物外,我们还评估了320×320 crop,如下所示[15]。我们的结果优于ResNet、Inception-v3/v4和Inception-ResNet-v2,single-crop前5名的错误率为4.4%。此外,我们的架构设计比所有的初始模型都简单得多,并且需要手动设置的超参数也少得多。
Resnext是我们的参赛作品的基础,对ILSVRC 2016分类任务,我们实现了2个。我们注意到使用多尺度和/或多帧测试后,许多模型(包括我们的)开始在此数据集上饱和。使用[14]中的多尺度密集测试,我们的单模型top-1/top-5错误率为17.7%/3.7%,与采用多尺度多作物测试的Inception-ResNet-v2的单模型结果17.8%/3.7%相当。我们在测试集中进行了3.03%的前5个错误的集合结果,与winner的2.99%和Inception-V4 / InceptionResnet-V2的3.08%[37]相符。



5.2 在ImgaeNet-5K的实验
ImageNet-1K上的性能似乎饱和。但我们认为这不是因为模型的能力,而是因为数据集的复杂性。接下来,我们在具有5000类的更大的想象中子集上评估我们的模型。
我们的5k数据集是完整的Imagenet-22k集合[33]的子集。 5000类别由原始Imagenet1K类别和其他4000类包含完整的ImageNet集中最多的图像。 5K套装有680万个图像,约为1K集的5倍。没有官方火车/ val拆分,因此我们选择评估原始ImageNet-1K验证集。在此1k-class val集合中,可以将模型评估为5k路分类任务(预测为其他4K类的所有标签自动错误)或作为1k路分类任务(SoftMax仅在1K上应用课程)在测试时间。
实验细节和第4节相同。5K-trainning 模型均从零开始训练并且针对与1K训练模型相同数量的小批量进行训练(因此1/5Xepochs)
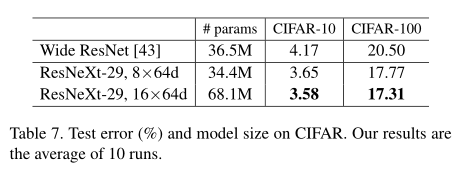
表6和图6显示了在保持复杂性的情况下的比较。ResNeXt-50比ResNet-50减少了3.2%的5K路top-1错误,ResNetXt-101比ResNet-101减少了2.3%的5K路top-1错误。在1K路误差上观察到类似的间隙。这些显示了ResNeXt更强的代表性。
此外,我们发现在5K集上训练的模型(表6中的1K路误差为22.2%/5.7%)与在1K集上训练的模型(表3中的21.2%/5.6%)相比表现更有竞争力,在验证集上的相同1K路分类任务上进行了评估。这一结果是在不增加训练时间(由于相同数量的小批量)和不进行微调的情况下实现的。我们认为这是一个有希望的结果,因为将5K分类的训练任务是一个更具挑战性的任务。
5.3 在CIFAR的实验
我们在CIFAR-10和100数据集上进行了更多的实验[23]。我们使用[14]中的体系结构,并用bottleneck模板替换基本残差块
Bottleneck template: 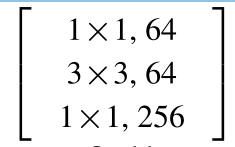
我们的网络从单个3×3 conv层开始,然后是3个阶段,每个阶段有3个残差块,最后是平均池和一个完全连接的分类器(总共29层),如下文[14]。我们将这种转换和翻转数据增强称为[14]。实施细节见附录。
我们基于上述基线比较了两种情况下提高复杂性:(i)增加基数并修复所有宽度,或(ii)增加bottleneck的宽度和修复基数= 1.我们在这些变化下培训并评估一系列网络。图7显示了测试误差速率与模型大小的比较。我们发现,随着我们在Imagenet-1K上观察到的宽度,增加的基数比增加的宽度更有效。表7显示了结果和模型尺寸,与宽Reset [43]相比,这是最好的已发布记录。我们具有类似型号(34.4M)的模型显示结果比Reset更好。我们的较大方法在CIFAR-10和CIFAR-100上实现了3.58%的测试误差(平均10次运行)和17.31%。据我们所知,这些是文献中的最先进的结果(具有类似的数据增强),包括未发表的技术报告。


5.4在COCO目标检测的实验
接下来,我们评估Coco对象检测集的概括性[27]。我们在80K训练集上培训模型加上35k Val子集并在5K Val子集(称为MINIVAL)上进行评估,如[1]。我们评估Cocostyle平均精度(AP)以及AP@iou=0.5 [27]。我们采用基本更快的R-CNN [32]并关注[14]将Reset / Resnext插入其中。模型在ImageNet-1k上预先培训,并在检测集上进行微调。实施细节在附录中。
表8显示了比较。在50层基线上,RESNEXT将AP @ 0.5改善2.1%,AP达1.0%,而不会增加复杂性。 ResNext在101层基线上显示了较小的改进。我们猜测更多培训数据将导致更大的差距,如想象的-5K集合所观察到的。
值得注意的是,最近在Mask R-CNN [12]中采用了最近的ResNext,以实现最先进的Coco实例分割和对象检测任务。
感谢
S.X.和Z.T. NSF IIS-1618477部分支持的研究。作者谨此感谢Tsung-yi Lin和Priya Goyal的宝贵讨论。