1���������ݼ����س����ķ�����
1.1 bagging
�Ծٻ�۷���bootstrap aggregating����Ҳ��Ϊbagging���������ڴ�ԭʼ���ݼ�ѡ��S�κ�õ�S�������ݼ���һ�ּ����������ݼ���ԭ���ݼ��Ĵ�С��ȣ�ÿ�����ݼ�������ԭʼ���ݼ����зŻ����ѡ�������õ�������ζ�������ݼ��п������ظ���������Ҳ����û�а���ԭ���ݼ�������������
��S�����ݼ�����֮��ij��ѧϰ�㷨�ֱ�������ÿ�����ݼ��͵õ���S����������������Ҫ�������ݽ��з���ʱ���Ϳ���Ӧ����S�����������з��ࡣ���ͬʱ��ѡ�������ͶƱ��������������Ϊ���ķ�������
1.2 boosting
boosting��bagging�����ƣ�����ʹ����ͬ���͵ķ�������������boosting�У���ͬ�ķ�������ͨ������ѵ������õġ�Boosting���й�ע�����з��������ֵ���Щ����������µķ�������
����boosting����Ľ���ǻ������з������ļ�Ȩ��͵Ľ����������boosting�з�������Ȩ�ز�����ȣ�ÿ��Ȩ�ش�����������ڷ���������һ�ֵ����еijɹ��ȡ�
Boosting�����ж���汾������ֻ��ע����һ�������еİ汾AdaBoost��
1.3 AdaBoost
AdaBoost��adaptive boosting������Ӧboosting������д���������۸�ֲ��ʹ�����������Ͷ��ʵ��������һ��ǿ������������ġ�������ζ�ŷ����������ܱ�����²�Ҫ�Ժã�����Ҳ�����̫�ࣻ����ǿ���������Ĵ����ʽ���ͺܶࡣ
�����й������£�ѵ�������е�ÿ����������������һ��Ȩ�أ���ЩȨ�ع���������D��һ��ʼ����ЩȨ�ض���ʼ�������ֵ��������ѵ��������ѵ����һ����������������÷������Ĵ����ʣ�Ȼ����ͬһ���ݼ����ٴ�ѵ�������������ڷ������ĵڶ���ѵ�����У��������µ���ÿ��������Ȩ�أ����е�һ�ηֶԵ�������Ȩ�ؽ��ή�ͣ�����һ�ηִ���������Ȩ�ؽ�����ߡ�Ϊ�˴��������������еõ����յķ�������AdaBoostΪÿ����������������һ��Ȩ��ֵalpha����Щalphaֵ�ǻ���ÿ�����������Ĵ����ʽ��м���ġ����У������ʦŵĶ���Ϊ��

��alpha�ļ��㹫ʽΪ��

�����alphaֵ֮���Զ�Ȩ������D���и��£���ʹ����Щ��ȷ�����������Ȩ�ؽ��Ͷ�����������Ȩ�����ߡ�
���ij����������ȷ���࣬Ȩ�ظ���Ϊ��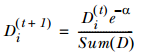
����������֣�Ȩ�������Ϊ��
�ڼ����D֮��AdaBoost�ֿ�ʼ������һ�ֵ�����֪��ѵ��������Ϊ0����������������Ŀ�ﵽ�û�ָ��ֵΪֹ��
2��AdaBoost�㷨��ʵ��---python����
## 1�� ������������---�����������AdaBoost�������е����������� import numpy as npdef loadSimpData():'''�����ѵ������ '''datMat = np.matrix([[ 1. , 2.1],[ 2. , 1.1],[ 1.3, 1. ],[ 1. , 1. ],[ 2. , 1. ]])classLabels = [1.0, 1.0, -1.0, -1.0, 1.0]return datMat,classLabelsdef buildStump(dataArr,classLabels,D):'''����һ���������������ΪȨ������D�����ؾ�����С�����ʵĵ������������С�Ĵ������Լ����Ƶ��������''' dataMatrix =np. mat(dataArr); labelMat =np. mat(classLabels).Tm,n = np.shape(dataMatrix)numSteps = 10.0; bestStump = {}; bestClasEst = np.mat(np.zeros((m,1)))minError = np.inf #for i in range(n):#�����ݼ��е�ÿһ������rangeMin = dataMatrix[:,i].min(); rangeMax = dataMatrix[:,i].max();stepSize = (rangeMax-rangeMin)/numStepsfor j in range(-1,int(numSteps)+1):#��ÿ������for inequal in ['lt', 'gt']: #��ÿ�����Ⱥ�threshVal = (rangeMin + float(j) * stepSize)predictedVals = stumpClassify(dataMatrix,i,threshVal,inequal)errArr = np.mat(np.ones((m,1)))errArr[predictedVals == labelMat] = 0weightedError = D.T*errArr #�����Ȩ������#print("split: dim %d, thresh %.2f, thresh ineqal: %s, the weighted error is %.3f" % (i, threshVal, inequal, weightedError))#��������ʵ���minError����ǰ�����������Ϊ��ѵ�������� if weightedError < minError:minError = weightedErrorbestClasEst = predictedVals.copy()bestStump['dim'] = ibestStump['thresh'] = threshValbestStump['ineq'] = inequalreturn bestStump,minError,bestClasEstdef stumpClassify(dataMatrix,dimen,threshVal,threshIneq):'''ͨ����ֵ�Ƚ϶����ݽ��з��� '''retArray = np.ones((np.shape(dataMatrix)[0],1))if threshIneq == 'lt':retArray[dataMatrix[:,dimen] <= threshVal] = -1.0else:retArray[dataMatrix[:,dimen] > threshVal] = -1.0return retArray##2�����ڵ����������AdaBoostѵ������def adaBoostTrainDS(dataArr,classLabels,numIt=40):'''���ڵ����������AdaBoostѵ������'''weakClassArr = []m = np.shape(dataArr)[0]D = np.mat(np.ones((m,1))/m) #��ʼ��Ȩ������Ϊ1/maggClassEst = np.mat(np.zeros((m,1)))#��¼ÿ�����ݵ���������ۼ�ֵfor i in range(numIt):#����һ�����������bestStump,error,classEst = buildStump(dataArr,classLabels,D)print("D:",D.T)#����alpha���˴���ĸ��max(error,1e-16)�Է�ֹerror=0alpha = float(0.5*np.log((1.0-error)/max(error,1e-16)))bestStump['alpha'] = alpha weakClassArr.append(bestStump)print("classEst: ",classEst.T)#������һ�ε�����Dexpon = np.multiply(-1*alpha*np.mat(classLabels).T,classEst)D = np.multiply(D,np.exp(expon)) D = D/D.sum()#���¼���ѵ�������ʣ�����ܴ�����Ϊ0������ֹѭ��aggClassEst += alpha*classEstprint("aggClassEst: ",aggClassEst.T)aggErrors = np.multiply(np.sign(aggClassEst) != np.mat(classLabels).T,np.ones((m,1)))errorRate = aggErrors.sum()/mprint("total error: ",errorRate)if errorRate == 0.0: breakreturn weakClassArr,aggClassEst##3�����Է���Ч�� def adaClassify(datToClass,classifierArr):'''����ѵ�����Ķ�������������з��� datToClass:����������classifierArr:ѵ���Ľ��'''dataMatrix =np. mat(datToClass)m =np. shape(dataMatrix)[0]aggClassEst = np.mat(np.zeros((m,1)))#����classifierArr�е���������������������stumpClassify��ÿ���������õ�һ�����Ĺ���ֵfor i in range(len(classifierArr)):classEst = stumpClassify(dataMatrix,classifierArr[i]['dim'],\classifierArr[i]['thresh'],\classifierArr[i]['ineq'])aggClassEst += classifierArr[i]['alpha']*classEst #�˴�����δ���--��ά����print(aggClassEst)return np.sign(aggClassEst)if __name__ == "__main__":dataArr,labelArr=loadSimpData()print(labelArr)print('-----------------------')classifierArr=adaBoostTrainDS(dataArr,labelArr,30)print(classifierArr)print('-----------------------')pred=adaClassify([0,0],classifierArr)print(pred)