GooLeNet是ILSVRC2014竞赛图像分类任务第一名
使用了更深的网络
- 22层(包括池化层共27层)
- 高效的"Inception"模块
- 无全连接层
- 参数数量仅为AlexNet的1/12
- ILSVRC-2014的分类和检测任务的冠军(6.7% top-5 error)
Inception module (聚合)
设计良好的局部网络拓扑,然后将这些模块堆叠在一起
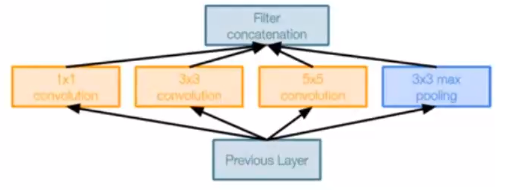

- 对前一层的输入进行并行滤波操作
- 多个感受野大小(1x1,3x3,5x5)的卷积
- 池化操作(3x3)
所有滤波器输出沿深度(depth-wise)拼接在一起
设计理念
- 图像中的突出部分可能具有极大的尺寸变化。
- 信息位置的这种巨大变化,卷积操作选择正确的核大小比较困难。
- 对于较全局分布的信息,首选较大的内核,对于较局部分布的信息,首选较小的内核。
- 非常深的网络容易过拟合。它也很难通过整个网络传递梯度更新。
- 简单地堆叠大卷积运算导致计算复杂度较高。

具有降维的Inception Module
简单地堆叠大卷积运算导致计算复杂度较高,引入了具有降维的Inception Module(Inception module with dimension reduction)解决复杂度的问题:引入**“bottleneck” **层,其使用1x1卷积来减小特征深度

我们再来看Inception?Module的基本结构,其中有4个分支:
- 第一个分支对输入进行1?1的卷积,这其实也是NIN中提出的一个重要结构。1?1的卷积是一个非常优秀的结构,它可以跨通道组织信息,提高网络的表达能力,同时可以对输出通道升维和降维。可以看到Inception?Module的4个分支都用到了1?1卷积,来进行低成本(计算量比3?3小很多)的跨通道的特征变换。
- 第二个分支先使用了1?1卷积,然后连接3?3卷积,相当于进行了两次特征变换。
- 第三个分支类似,先是1?1的卷积,然后连接5?5卷积。
- 最后一个分支则是3?3最大池化后直接使用1?1卷积。
我们可以发现,有的分支只使用1?1卷积,有的分支使用了其他尺寸的卷积时也会再使用1?1卷积,这是因为1?1卷积的性价比很高,用很小的计算量就能增加一层特征变换和非线性化。 Inception?Module的4个分支在最后通过一个聚合操作合并(在输出通道数这个维度上聚合)。Inception?Module中包含了3种不同尺寸的卷积和1个最大池化,增加了网络对不同尺度的适应性,这一部分和Multi-Scale的思想类似。早期计算机视觉的研究中,受灵长类神经视觉系统的启发,Serre使用不同尺寸的Gabor滤波器处理不同尺寸的图片,Inception?V1借鉴了这种思想。Inception?V1的论文中指出,Inception?Module可以让网络的深度和宽度高效率地扩充,提升准确率且不致于过拟合。

- 1.Shortcut连接: 1x1卷积
- 2, 多尺度滤波1: 1x1卷积+3x3卷积(不同感受野结合)
- 3・多尺度滤波2: 1x1卷积+5x5卷积(不同感受野结合)
- 4,池化分支: 3x3 pooling + 1x1卷积
inception结构的主要贡献:一是使用1x1的卷积来进行降维;二是在多个尺寸上同时进行卷积再聚合
多尺度聚合的作用
多尺度多层次滤波:
- 多尺度:对输入特征图分别在3x3和5x5的卷集核上进行滤波,提高了所学特征的多样性,增强了网络对不同尺度的鲁棒性。
- 多层次:符合Hebbian原理( 赫布理论,下面进行解释) ,即通过1x1卷积把具有高度相关性的不同通道的卷积结果进行组合汇聚一起,起到减少冗余、加速收敛的作用。

*参数数量大量减少,复杂度更低
Hebbian原理
人脑神经元的连接是稀疏的,因此研究者认为大型神经网络的合理的连接方式应该也是稀疏的。稀疏结构是非常适合神经网络的一种结构,尤其是对非常大型、非常深的神经网络,可以减轻过拟合并降低计算量,例如卷积神经网络就是稀疏的连接。Inception?Net的主要目标就是找到最优的稀疏结构单元(即Inception?Module),论文中提到其稀疏结构基于Hebbian原理,这里简单解释一下Hebbian原理:神经反射活动的持续与重复会导致神经元连接稳定性的持久提升,当两个神经元细胞A和B距离很近,并且A参与了对B重复、持续的兴奋,那么某些代谢变化会导致A将作为能使B兴奋的细胞。总结一下即“一起发射的神经元会连在一起”(Cells?that?fire?together,?wire?together),学习过程中的刺激会使神经元间的突触强度增加。受Hebbian原理启发,另一篇文章Provable?Bounds?for?Learning?Some?Deep?Representations提出,如果数据集的概率分布可以被一个很大很稀疏的神经网络所表达,那么构筑这个网络的最佳方法是逐层构筑网络:将上一层高度相关(correlated)的节点聚类,并将聚类出来的每一个小簇(cluster)连接到一起,如图11所示。这个相关性高的节点应该被连接在一起的结论,即是从神经网络的角度对Hebbian原理有效性的证明。
Hebbian原理与1x1卷积
因此一个“好”的稀疏结构,应该是符合Hebbian原理的,我们应该把相关性高的一簇神经元节点连接在一起。在普通的数据集中,这可能需要对神经元节点聚类,但是在图片数据中,天然的就是临近区域的数据相关性高,因此相邻的像素点被卷积操作连接在一起。而我们可能有多个卷积核,在同一空间位置但在不同通道的卷积核的输出结果相关性极高。因此,一个1?1的卷积就可以很自然地把这些相关性很高的、在同一个空间位置但是不同通道的特征连接在一起,这就是为什么1?1卷积这么频繁地被应用到Inception?Net中的原因。 1?1卷积所连接的节点的相关性是最高的,而稍微大一点尺寸的卷积,比如3?3、5?5的卷积所连接的节点相关性也很高,因此也可以适当地使用一些大尺寸的卷积,增加多样性(diversity)。最后Inception?Module通过4个分支中不同尺寸的1?1、3?3、5?5等小型卷积将相关性很高的节点连接在一起,就完成了其设计初衷,构建出了很高效的符合Hebbian原理的稀疏结构。
GooLeNet 结构框架

前面经过传统的卷积,之后通过九个堆叠Inception Modules,最后经过分类的输出

辅助分类器: 辅助分类输出,用于在较低层注入额外的梯度,这样相当于做了模型融合,同时给网络增加了反向传播的梯度信号,也提供了额外的正则化,对于整个Inception?Net的训练很有裨益。
损失函数
训练时的Inception net的总损失:
total loss = real loss + 0.3 * aux_loss_1 + 0.3 * aux_loss_2
辅助损失纯粹用于训练目的,在推理(测试)过程中被忽略。
网络最后的部分并没有使用全连接层,而是使用了全局平均值池化GAP,由于GAP没有参数,所以不会导致过拟合

总结
Google?Inception?Net首次出现在ILSVRC?2014的比赛中(和VGGNet同年),就以较大优势取得了第一名。那届比赛中的Inception?Net通常被称为Inception?V1,它最大的特点是控制了计算量和参数量的同时,获得了非常好的分类性能――top-5错误率6.67%,只有AlexNet的一半不到。Inception?V1有22层深,比AlexNet的8层或者VGGNet的19层还要更深。但其计算量只有15亿次浮点运算,同时只有500万的参数量,仅为AlexNet参数量(6000万)的1/12,却可以达到远胜于AlexNet的准确率,可以说是非常优秀并且非常实用的模型。
Inception?V1降低参数量的目的有两点,
- 第一,参数越多模型越庞大,需要供模型学习的数据量就越大,而目前高质量的数据非常昂贵;
- 第二,参数越多,耗费的计算资源也会更大。Inception?V1参数少但效果好的原因除了模型层数更深、表达能力更强外,还有两点:
一是去除了最后的全连接层,用全局平均池化层 (即将图片尺寸变为1?1)来取代它。全连接层几乎占据了AlexNet或VGGNet中90%的参数量,而且会引起过拟合,去除全连接层后模型训练更快并且减轻了过拟合。用全局平均池化层取代全连接层的做法借鉴了Network?In?Network(以下简称NIN)论文。
二是Inception?V1中精心设计的Inception?Module提高了参数的利用效率,其结构如图10所示。这一部分也借鉴了NIN的思想,形象的解释就是Inception?Module本身如同大网络中的一个小网络,其结构可以反复堆叠在一起形成大网络。不过Inception?V1比NIN更进一步的是增加了分支网络, NIN则主要是级联的卷积层和MLPConv层。一般来说卷积层要提升表达能力,主要依靠增加输出通道数,但副作用是计算量增大和过拟合。 每一个输出通道对应一个滤波器,同一个滤波器共享参数,只能提取一类特征,因此一个输出通道只能做一种特征处理。而NIN中的MLPConv则拥有更强大的能力,允许在输出通道之间组合信息,因此效果明显。可以说,MLPConv基本等效于普通卷积层后再连接1?1的卷积和ReLU激活函数。
