BN-Inception核心组件
- Batch Normalization (批归―化)
目前BN已经成为几乎所有卷积神经网络的标配技巧 - 5x5卷积核→ 2个3x3卷积核

Batch Normalization的采用理由
内部协变量偏移(Internal Covariate Shift) : 训练时网络参数的变化引起的网络激活分布的变化

机器学习领域有个很重要的假设:IID独立同分布假设,就是假设训练数据和测试数据是满足相同分布的,模型能够从稳定的数据分布中学习规律,这是通过训练数据获得的模型能够在测试集获得好的效果的一个基本保障。而BatchNorm是干啥的呢?BatchNorm就是在深度神经网络训练过程中使得每一层神经网络的输入保持相同分布的。
对于深度学习这种包含很多隐层的网络结构,在训练过程中,因为各层参数老在变,所以每个隐层都会面临covariate shift的问题,也就是在训练过程中,隐层的输入分布老是变来变去,这就是所谓的“Internal Covariate Shift”,Internal指的是深层网络的隐层,是发生在网络内部的事情,而不是covariate shift问题只发生在输入层。
BN的基本思想其实相当直观:因为深层神经网络在做非线性变换前的激活输入值(就是那个x=WU+B,U是输入)随着网络深度加深或者在训练过程中,其分布逐渐发生偏移或者变动,之所以训练收敛慢,一般是整体分布逐渐往非线性函数的取值区间的上下限两端靠近(对于Sigmoid函数来说,意味着激活输入值WU+B是大的负值或正值),所以这导致后向传播时低层神经网络的梯度消失,这是训练深层神经网络收敛越来越慢的本质原因,而BN就是通过一定的规范化手段,把每层神经网络任意神经元这个输入值的分布强行拉回到均值为0方差为1的标准正太分布
其实就是把越来越偏的分布强制拉回比较标准的分布,这样使得激活输入值落在非线性函数对输入比较敏感的区域,这样输入的小变化就会导致损失函数较大的变化,意思是这样让梯度变大,避免梯度消失问题产生,而且梯度变大意味着学习收敛速度快,能大大加快训练速度。
首先我们看下均值为0,方差为1的标准正态分布代表什么含义:

这意味着在一个标准差范围内,也就是说64%的概率x其值落在[-1,1]的范围内,在两个标准差范围内,也就是说95%的概率x其值落在了[-2,2]的范围内。那么这又意味着什么?我们知道,激活值x=WU+B,U是真正的输入,x是某个神经元的激活值,假设非线性函数是sigmoid,
就是说经过BN后,大部分Activation的值落入非线性函数的线性区内,其对应的导数远离导数饱和区,这样来加速训练收敛过程。
但是很明显,看到这里,稍微了解神经网络的读者一般会提出一个疑问:如果都通过BN,那么不就跟把非线性函数替换成线性函数效果相同了?这意味着什么?我们知道,如果是多层的线性函数变换其实这个深层是没有意义的,因为多层线性网络跟一层线性网络是等价的。这意味着网络的表达能力下降了,这也意味着深度的意义就没有了。所以BN为了保证非线性的获得,对变换后的满足均值为0方差为1的x又进行了scale加上shift操作(y=scale*x+shift),每个神经元增加了两个参数scale和shift参数,这两个参数是通过训练学习到的,意思是通过scale和shift把这个值从标准正态分布左移或者由移一点并长胖一点或者变瘦一点,每个实例挪动的程度不一样,这样等价于非线性函数的值从正中心周围的线性区往非线性区动了动。核心思想应该是想找到一个线性和非线性的较好平衡点,既能享受非线性的较强表达能力的好处,又避免太靠非线性区两头使得网络收敛速度太慢。
原文链接:https://blog.csdn.net/malefactor/article/details/51476961
如何做Batch Normalizationivation
位置:卷积→BN→ReLU

为使每一维成为标准高斯分布(均值为0,方差为1),可应用
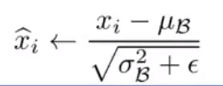
但是转换后的数据都是标准高斯分布的数据(加速收敛),不能反映真实数据的分布(表征受到影响),又做了一次逆转(减小表征受到影响的程度)。
逆转:
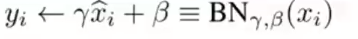
- 观点一:为能工作在激活的非线性区,再进行尺度缩放和平移(scale&shift)(减小表征受到影响的程度)
- 另外的观点:将normalize的x逆转回去,是为了在加速收敛和表征破坏之间,有个trade off(折中)的空间
现在所用的优化方法大多都是min-batch SGD,所以归一化操作就成为Batch Normalization

对一个BATCH,N个样本做BN:
先求一个batch的均值和方差,然后做归一化,变为均值为0,方差为1的变量,再做逆转操作:尺度缩放和平移(scale&shift)
在每个mini-batch中计算得到mini-batch的mean和variance来替代整体训练集的mean和variance
- 训练时,在每一层都用这样的方式进行归一化,是实时计算的
- 而测试的时候,是记录训练时候的均值和方差累加和求平均,直接用

Batch Normalization的采用理由
论文: How Does Batch Normalization Help Optimization?
(No, It Is Not About Internal Covariate Shif)
它使优化loss地貌(landscape)更加平滑。这种平滑性使梯度更具预测性和稳定性,训练更快

好处:
- 可使用较高的学习率,减低参数初始化的敏感性
- 可作为一种正则化方法 ,在某些情形下可不使用Dropout:
这是因为在使用 Mini-batch 梯度下降的时候,每次计算均值和偏差都是在一个 Mini-batch 上进行计算,而不是在整个数据样集上。这样就在均值和偏差上带来一些比较小的噪声。那么用均值和偏差计算得到的 z?[l]也将会加入一定的噪声
所以和 Dropout 相似,其在每个隐藏层的激活值上加入了一些噪声,(这里因为 Dropout 以一定的概率给神经元乘上 0 或者 1)。所以和 Dropout 相似,Batch Norm 也有轻微的正则化效果。
这里引入一个小的细节就是,如果使用 Batch Norm ,那么使用大的 Mini-batch 如 256,相比使用小的 Mini-batch 如 64,会引入跟少的噪声,那么就会减少正则化的效果。

*收敛更快,准确率提升
ImageNet图像分类结果


总结
Inception?V2学习了VGGNet,用两个3?3的卷积代替5?5的大卷积(用以降低参数量并减轻过拟合),还提出了著名的Batch?Normalization(以下简称BN)方法。BN是一个非常有效的正则化方法,可以让大型卷积网络的训练速度加快很多倍,同时收敛后的分类准确率也可以得到大幅提高。BN在用于神经网络某层时,会对每一个mini-batch数据的内部进行标准化(normalization)处理,使输出规范化到N(0,1)的正态分布,减少了Internal?Covariate?Shift(内部神经元分布的改变)。BN的论文指出,传统的深度神经网络在训练时,每一层的输入的分布都在变化,导致训练变得困难,我们只能使用一个很小的学习速率解决这个问题。而对每一层使用BN之后,我们就可以有效地解决这个问题,学习速率可以增大很多倍,达到之前的准确率所需要的迭代次数只有1/14,训练时间大大缩短。而达到之前的准确率后,可以继续训练,并最终取得远超于Inception?V1模型的性能――top-5错误率4.8%,已经优于人眼水平。因为BN某种意义上还起到了正则化的作用,所以可以减少或者取消Dropout,简化网络结构。
当然,只是单纯地使用BN获得的增益还不明显,还需要一些相应的调整:
- 增大学习速率并加快学习衰减速度以适用BN规范化后的数据;去除Dropout并减轻L2正则(因BN已起到正则化的作用);
- 去除LRN;更彻底地对训练样本进行shuffle;
- 减少数据增强过程中对数据的光学畸变(因为BN训练更快,每个样本被训练的次数更少,因此更真实的样本对训练更有帮助)。
在使用了这些措施后,Inception?V2在训练达到Inception?V1的准确率时快了14倍,并且模型在收敛时的准确率上限更高。