程序员小强总结的 ElasticSearch专题超全总结篇在这里:传送门
结合官网资料,做了更详细的实际使用总结。
从单机版安装到集群高可用生产环境搭建、基本概念(索引,分片,节点,倒排索引…)、DSL语法实践、分词器(内置+中文)、SpringBoot整合实战、仿京东商品搜索实战实现。
1.简单分页
对于非深度分页,简单查询时,一般使用from和size进行分页查询
- “from”: 分页起始位置
- “size”: 每页数据大小
1.1写法
GET /student_info/_search
{
"query": {
"match_all": {
}},"from": 1,"size": 2
}
常见问题:深分页问题,效率会很低,尽量避免深分页。
1.2深度分页问题
ES对于from+size的个数也是有限制的,默认限制二者之和不能超过1w。超过后会报错,
使用index.max_result_window:10000作为保护措施,虽然这个参数可以修改,也可以在配置文件配置。
但是最好不要这么做,当所请求的数据总量大于1w时,应用ES游标(scroll查询)来代替from+size。如果需要深度分页对服务器压力会变大。如果确认需要设置,则需要提前预估启动内存大小。
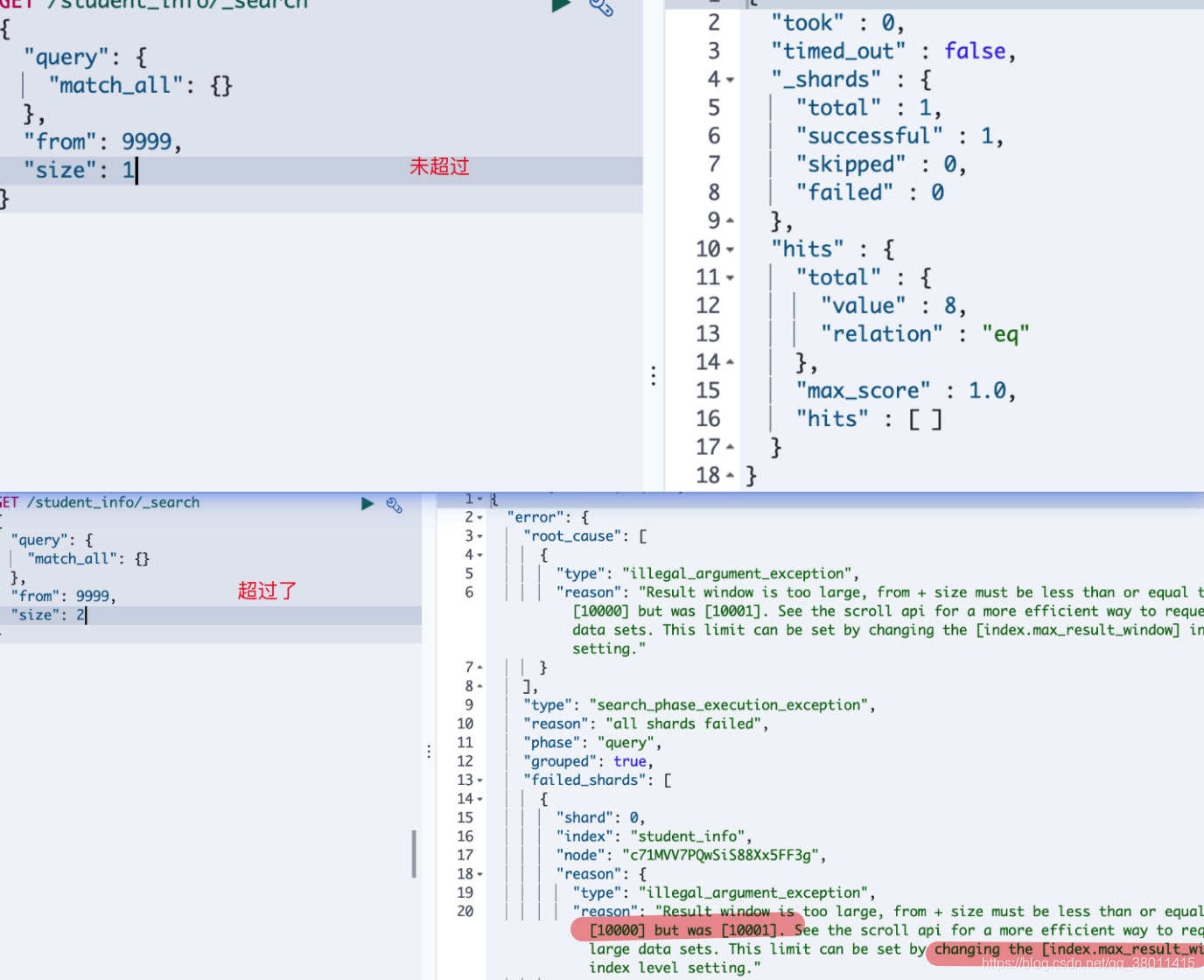
深分页举例
- 比如每页100条,当要查询第100页也就是9900 ~ 10000数据时,若是去5个节点查询,那么每个节点查到这个区间的数据,然后汇总并排序后再取9900 ~ 10000之间的数据,非常消耗资源,而且有OOM的风险。
2.游标查询(scoll)
scoll 游标查询,指定 scroll=时间 ,指定保存的分钟数,
第一次发起请求放回的是数据+_scroll_id ,后面通过 _scroll_id 去请求数据,适合大批量查询。
#游标查询-年龄> 18,每页2条,保存1分钟
GET /student_info/_search?scroll=1m
{
"query": {
"range": {
"age":{
"gt": 18}}},"size": 2
}
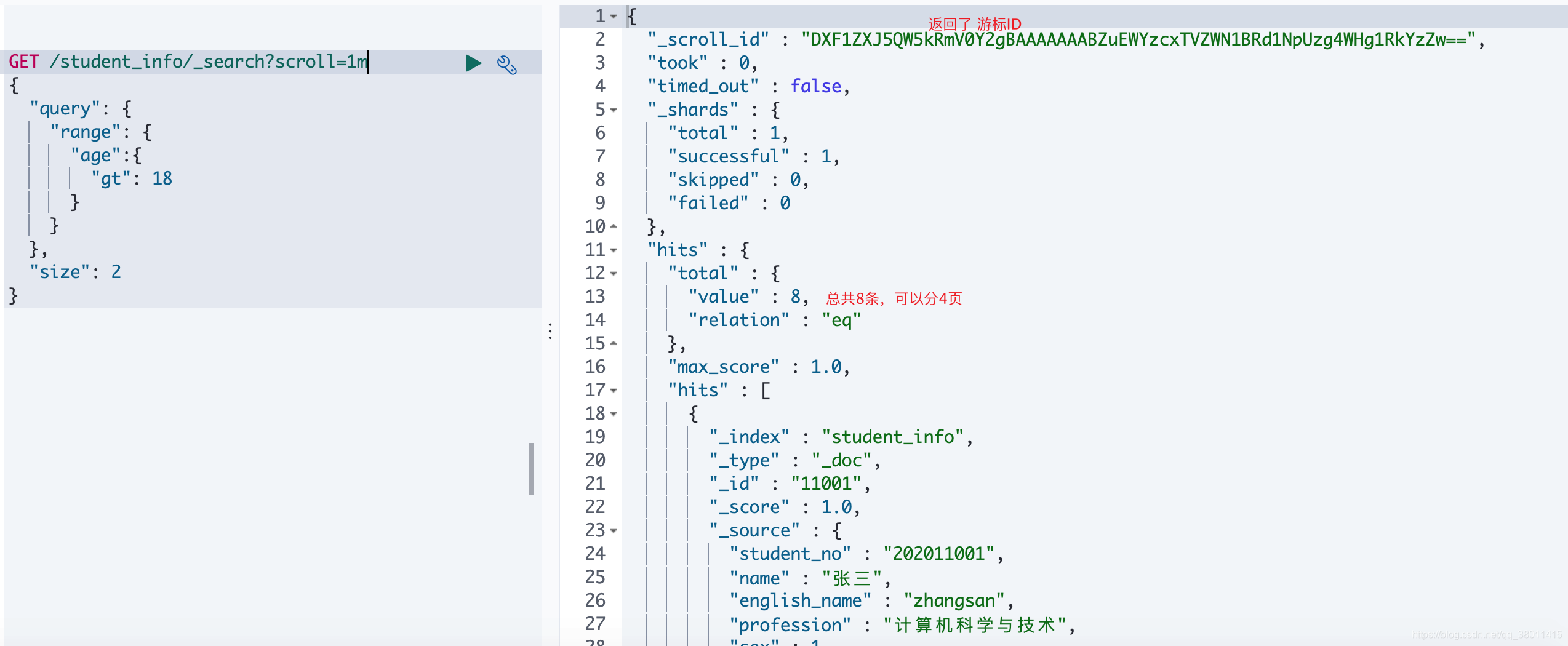
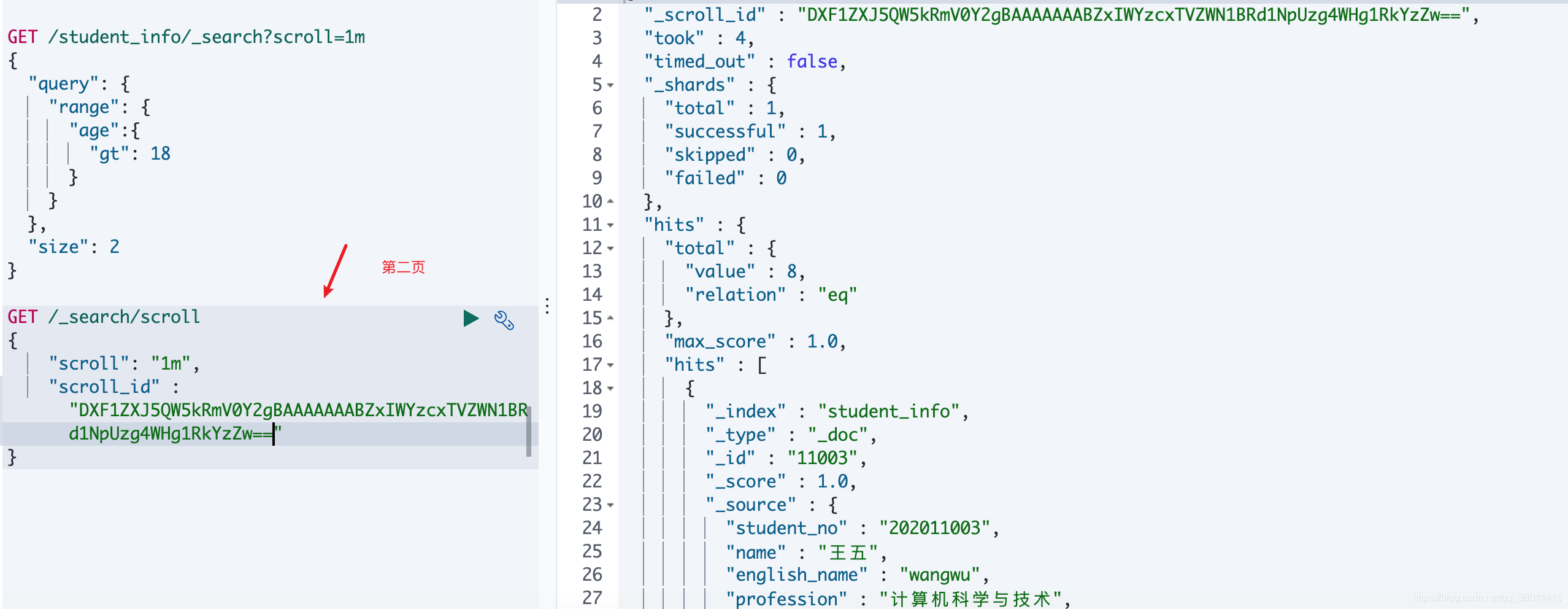
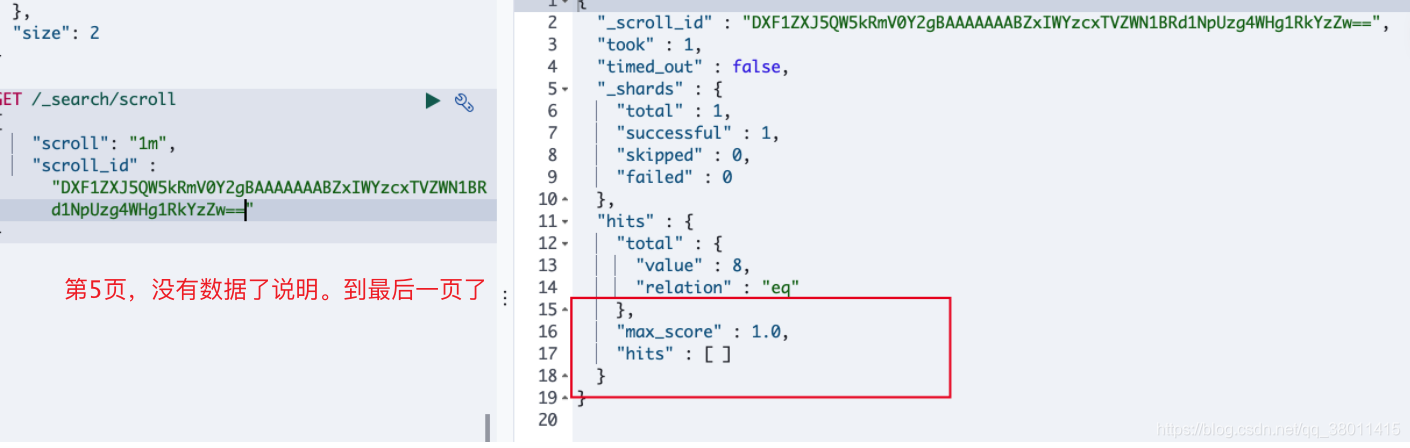
游标查询,其实是在 es 里面缓存了结果 ,然后一次一次的去取,所以发起第一次请求的时候只有 size ,没有from,后面的请求只有 scroll_id 和 scroll 时间
GET /_search/scroll
{
"scroll": "1m","scroll_id" : "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAABZxIWYzcxTVZWN1BRd1NpUzg4WHg1RkYzZw=="
}
3.search_after分页
- from + size的分页方式虽然是最灵活的分页方式,但当分页深度达到一定程度将会产生深度分页的问题。
- scroll能够解决深度分页的问题,但是其无法实现实时查询,即当scroll_id生成后无法查询到之后数据的变更,因为其底层原理是生成数据的快照。
- ES-5.X之后 search_after应运而生
使用search_after必须添加排序"sort"条件
如下示例:指定了根据ID升序,年龄倒叙,2个排序条件,search_after中[起始ID,起始年龄]
GET /student_info/_search
{
"query": {
"match_all": {
}},"search_after": [11000,20],"size": 2,"sort": [{
"_id": "asc"},{
"age": "desc"}]
}
请求第一页的时候,会返回sort 值,下一页的时候,把上一页 sort的值带入查询参数 search_after中


4.三种分页方式比较
| 分页方式 | 性能 | 优点 | 缺点 | 使用场景 |
|---|---|---|---|---|
| from + size | 低 | 灵活性好,实现简单 | 深度分页问题 | 数据量比较小,能容忍深度分页问题 |
| scroll | 中 | 解决了深度分页问题 | 无法反应数据的实时性维护成本高,需要维护一个 scroll_id跳页查询问题 | 海量数据的导出需要查询海量结果集的数据 |
| search_after | 高 | 性能最好不存在深度分页问题能够反映数据的实时变更 | 实现复杂,需要有一个全局唯一的字段连续分页的实现相对复杂,因为每一次查询都需要上次查询的结果跳页查询问题 | 海量数据的分页 |
5.总结**
- Scroll 被推荐用于深度查询,但是代价是昂贵的,不推荐用于实时用户请求,而更适用于后台批处理任务,比如非实时导出或群发。
- search_after 提供了实时的光标来避免深度分页的问题,其实现方式是使用前一页的结果来帮助检索下一页。
- search_after不能自由跳到一个随机页面,只能按照 sort values 跳转到下一页,需要使用一个唯一值的字段作为排序字段,推荐使用_id 作为唯一值的排序字段