文章的思路很简单,类似于SENet(对channel做attention)、spacial attention就是将channel分为group, 然后对每个group进行spatial的attention

模块如上图所示,
1、将feature map按channel维度分为G个group
2、对每个group单独进行attention
3、对group进行global average pooling得到g
4、进行pooling之后的g与原group feature进行element-wise dot
5、在进行norm
6、再使用sigmoid进行激活
7、再与原group feature进行element-wise dot
模块结构
**我们把channel分成多个group,每个group都有sub feature,但是我们也注意到,由于噪声和相似特征,特征很难有良好的分布。**所以作者利用全局信息来进一步加强关键区域的语义特征学习。在这里作者提到,因为整个空间的特征不受噪声的支配(否则模型从这个组中什么也学不到)。因此用GAP来近似语义向量。(我觉得这里的解释有点牵强了,我还是倾向于SEnet里的说法)
1.所有feature求GAP
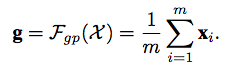
2.得到每个位置的attention
首先将特征分组,每组feature在空间上与其global pooling后的feature做点积(相似性)得到初始的attention mask,在对该attention mask进行减均值除标准差的normalize,并同时每个组学习两个缩放偏移参数使得normalize操作可被还原,然后再经过sigmoid得到最终的attention mask并对原始feature group中的每个位置的feature进行scale。
每个SGE模块引入大约2倍组数个参数,组数一般在32或64,这个数量级基本在大几十。相比于百万级别的CNN而言基本上参数量的增加基本可忽略不计。
这么设计的出发点也很容易理解,我们希望能够增强CNN学到的feature的语义分布,使得在正确语义的region,特征能够突出,而在无关语义的region,特征向量能够尽可能接近0。概念上受Capsule等启发,首先我们将特征分组,并认为每组特征在学习地过程中能够捕捉到某一个特定的语义。自然地,我们可以将global的平均feature代表该组学习到的语义向量(至少是接近的,否则该组就都被noise feature dominate了,那我做不做操作都没太大影响)。接下来,我们用每个position的feature与该global feature做点积,那么根据点积的定义,那些本身模长大的feature以及与global feature向量方向接近的feature就会得到一个较大的初始attention mask数值,这也是我们所期望的。因为不同样本在同一组上求得的attention mask分布差异很大,所以我们需要归一到同样的范围来给出准确的attention。最后,每一个location的feature都会scale上最终的0-1之间的数值。该方法的名称也准确地反应了核心操作:我们是group-wise地在spatial上enhance了语义feature的分布。
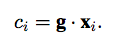
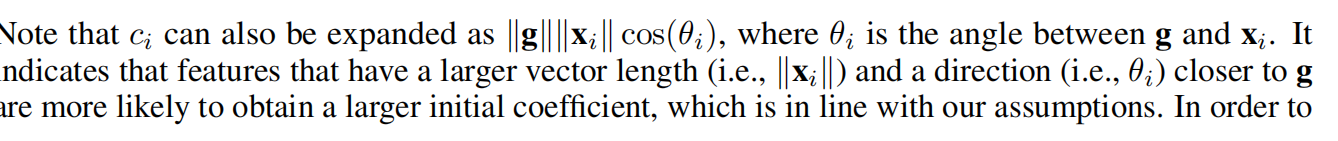
- BN:为了避免不同样本间系数的偏置大小造成的影响
- sigmoid
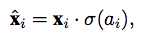
它放置的位置和SEnet一样,都是每个bottleneck最后一个BN层之后,同时group设为64

可以看到它的对于特定语义的学习还是比resnet要好的

对于比较理想的feature map,网络的空间激活值会有明显的对比,在语义相关区域有较大的数值激活,非相关区域在几乎无响应,这样的话,logit的稀疏性较强,方差较大,图3可得,确实SGE方差较大
实现结果:



