写在前面:
Sequence Model第四周的Transformer的内容貌似是比较新的内容,简单搜了一下都没有搜到答案,所以自己写了一个。顺便写点对题的理解,如有谬误欢迎指出。
第一题
A Transformer Network, like its predecessors RNNs, GRUs and LSTMs, can process information one word at a time. (Sequential architecture).
- True
- False 正确
Correct! A Transformer Network can ingest entire sentences all at the same time.
第二题
Transformer Network methodology is taken from: (Check all that apply)
- None of these.
- Convolutional Neural Network style of processing. 正确
- Convolutional Neural Network style of architecture.
- Attention mechanism. 正确
self-attention机制是和卷积操作有一些共同处的。可以看一看李宏毅老师讲的self-attention,我记得有。
第三题
The concept of Self-Attention is that:(懒得弄图片了,并不影响做题)
- Given a word, its neighbouring words are used to compute its context by taking the average of those word values to map the Attention related to that given word.
- Given a word, its neighbouring words are used to compute its context by selecting the lowest of those word values to map the Attention related to that given word.
- Given a word, its neighbouring words are used to compute its context by summing up the word values to map the Attention related to that given word.
- Given a word, its neighbouring words are used to compute its context by selecting the highest of those word values to map the Attention related to that given word. 正确
self-attention中α(alpha) 和V相乘后再相加。
第四题
Which of the following correctly represents Attention ?
- Attention(Q, K, V) =
- Attention(Q, K, V) =
- Attention(Q, K, V) =
- Attention(Q, K, V) =
正确
第五题
Are the following statements true regarding Query (Q), Key (K) and Value (V) ?
Q = interesting questions about the words in a sentence
K = specific representations of words given a Q
V = qualities of words given a Q
- False 正确
- True
Incorrect! Q = interesting questions about the words in a sentence, K = qualities of words given a Q, V = specific representations of words given a Q
第六题
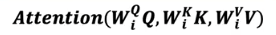
i here represents the computed attention weight matrix associated with the ithith “word” in a sentence.
- False
- True 正确
Correct!i here represents the computed attention weight matrix associated with the ith “head” (sequence).
第七题
Following is the architecture within a Transformer Network. (without displaying positional encoding and output layers(s))

What information does the Decoder take from the Encoder for its second block of Multi-Head Attention ? (Marked X, pointed by the independent arrow)
(Check all that apply)
- V 正确
- Q
- K 正确
K和V其实是一个特征值,靠encoder编码得到;Q包含翻译的句子的信息,由output通过attention计算得出。
第八题
Following is the architecture within a Transformer Network. (without displaying positional encoding and output layers(s))

What is the output layer(s) of the Decoder ? (Marked Y, pointed by the independent arrow)
- Linear layer
- Linear layer followed by a softmax layer. 正确
- Softmax layer followed by a linear layer.
- Softmax layer
这很容易理解,就像卷积操作过后通常也会跟一个线性层计算一样,Transformer也需要一个线形层进行处理。最后翻译问题可以看成一个分类问题,所以还需要一个softmax。
第九题
Why is positional encoding important in the translation process? (Check all that apply)
- Position and word order are essential in sentence construction of any language. 正确
- It helps to locate every word within a sentence.
- It is used in CNN and works well there.
- Providing extra information to our model. 正确
第十题
Which of these is a good criteria for a good positionial encoding algorithm?
- It should output a unique encoding for each time-step (word’s position in a sentence). 正确
- Distance between any two time-steps should be consistent for all sentence lengths. 正确
- The algorithm should be able to generalize to longer sentences. 正确
- None of the these.