医学图像配准是根据图像内容的匹配原则,将不同医学图像转换到同一个坐标系统下。医学图像配准处理不同观察点,不同时间,或者使用不同设备(CT,MR,US等)的图像对是非常有必要的。传统的配准方法是由有经验的专业人士进行手工标准配准的,这种手工标准的方法耗时耗力并且可能会出现较大的误差。为了提高配准的效率与可靠的准确性,自动配准应运而生。非深度学习的配准方法也曾经非常流行,直到2012年AlexNet网络的提出,深度学习因其在目标检测、特征提取、图像分割、图像分类、图像标注、和图像重建等领域理想的性能被广泛应用。
最初,深度学习被用于提升迭代和基于强度的配准的性能。后来又学者使用强化学习进行直观的图像配准,由于对快速配准方法的需求,推动了一步计算变形评估的发展。并且由于金标准数据的缺失,推动了无监督一步变换的发展。无监督方法的困难在于使用一种合适的评价函数进行相似性度量。解决的方法包括,使用基于信息论的相似性度量、基于解剖结构的分割、生成对抗网络等方法。
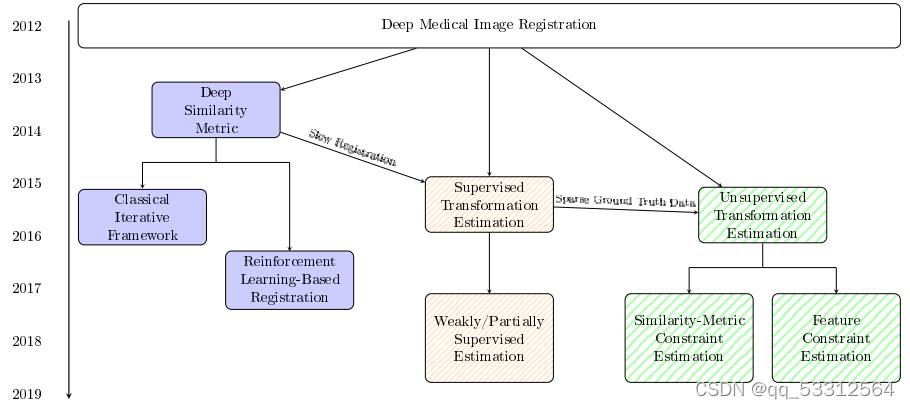
上图是不同的深度学习处理配准的方法
本文将从以下三个方面介绍:
1.深度迭代配准;
2.监督变换估计;
3.非监督变换估计;
一、深度迭代配准
基于强度的自动配准方法要求一个相似度测量函数和一个优化函数更新变换参数以至于得到图像间的最大相似程度。一些常见的相似性评估方法包括: sum of squared differences (SSD), cross-correlation (CC), mutual information (MI) normalized cross correlation (NCC), 和 normalized mutual information (NMI)。
1.基于深度相似性的配准
配准流程图如下:
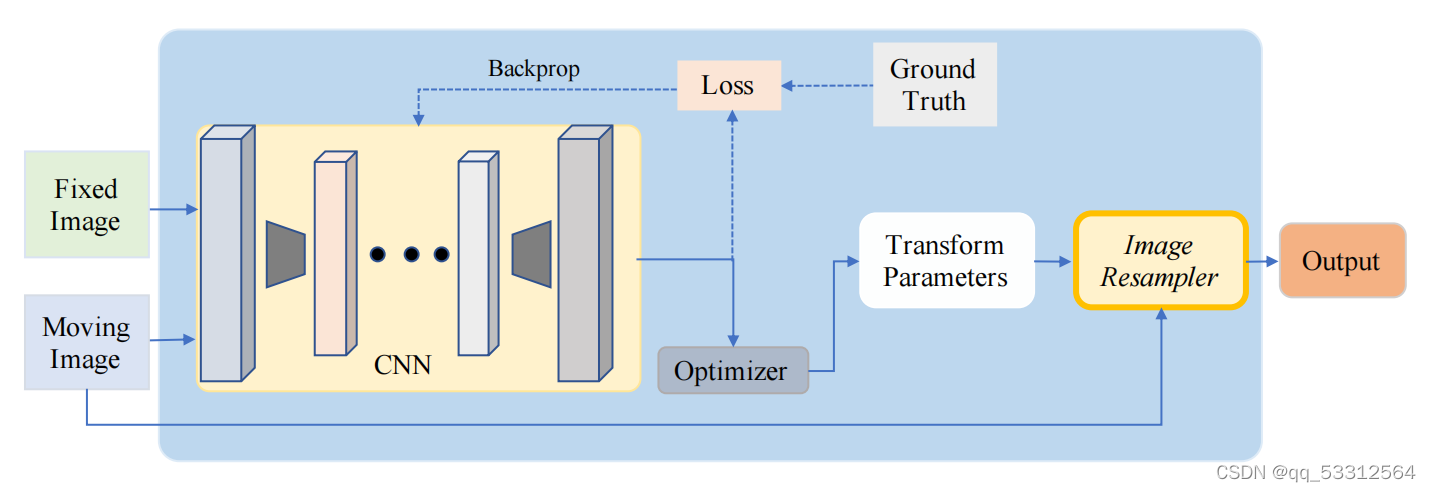
其中,实现表示在训练与测试时都要传输数据的数据流,虚线只需要在训练阶段使用。
1.1单模态配准
有学者使用卷积堆叠自编码器(convolutional stacked autoencoder ,CAE),提取可变形单模态图像特征,然后使用梯度下降法优化NCC;还有学者仅使用3D-CNN评估图像特征间的映射误差;还有学者将CNN描述器与手工标注的MRF自相似描述器进行比较发现CNN描述器的效果并不如MRF描述器,但是可以用来补充信息。
1.2多模态配准
手工标注的相似性测度在多模态图像配准上鲜有成功。于是有学者提出使用堆叠去噪自编码器(stacked denoising autoencoder)进行相似性测量,发现效果优于NMI和局部互信息(LCC);还有学者使用CNN评估已经对齐多模态图像间的不相似性并使用梯度下降法更新变形场的参数;另外,有学者使用五层神经网络进行相似性测量(刚性配准)并且使用Powells method进行优化;还有学者使用CNN预测目标配准误差( target registration error ,TRE)在使用传统优化方法前使用进化算法探索解空间以解决学习度量的缺凸性;还有学者使用长短时记忆空间共变器网络(LSTM spatial co-transformer
networks)进行迭代配准,该网络包括三个步骤:扭曲图像、残差参数预测和参数组合
以上两种类型的配准表明深度学习可以适用于有挑战性的配准任务,但有结果表明图像相似性度量适合在单模态时用作补充信息使用,此外迭代的方法不适用于需求的实时配准。
2.基于强化学习的配准
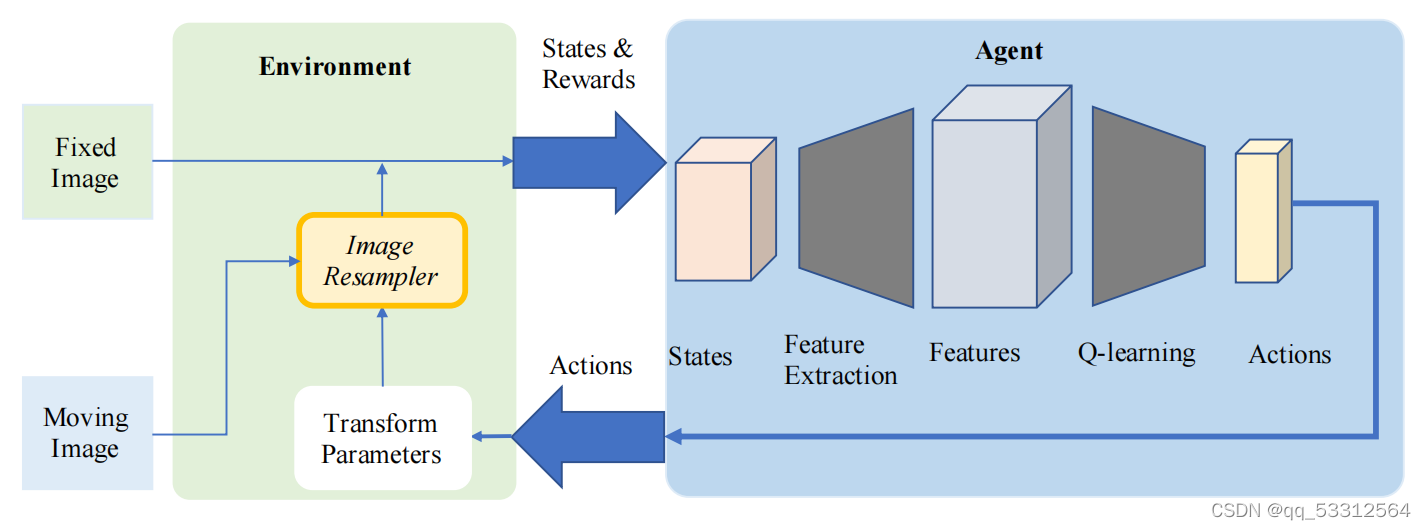
使用一个训练过的自能体替代预定义的优化算法,通常强化学习处理的是刚性配准的问题也可以处理非刚性配准的问题。
有学者使用贪婪监督算法与注意驱动的层次策略进行端到端训练,刚性配准的结果优于基于MI的配准和概率映射的语义配准;还有学者使用Q-learning并利用上下文内容确定投影图像的深度,并使用决斗网络,另外还区分了终端与非终端奖励;还有学者使用多个自能体系统,使用自动注意力机制观察多个区域,证明了多智能体机制的有效性;还有学者使用低分辨率(限制动作空间维度)模型进行配准和模糊动作控制,以影响随机动作的选择;
强化学习的缺陷是缺少处理高分辨率的能力(处理非刚性形变,形变动作复杂)。
二、监督变换估计
迭代运算减缓了配准的时间,尤其是在高纬度的可变形配准里。由此衍生出一次预测变换的需求,完全监督配准需要锦标数据定义损失函数。
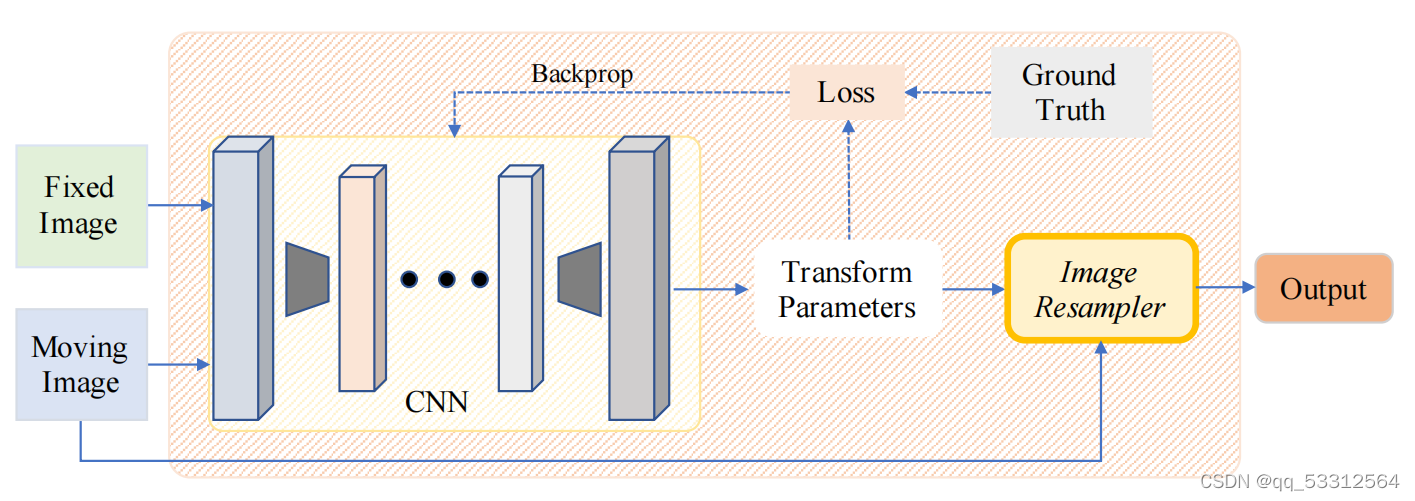
1.完全监督变换估计
使用神经网络替代迭代运算大大提升了配准过程的时间,但是由于高纬度解空间的FC全连接层的功耗大,所以进行可变形变换预测模型通常不使用传统的卷积神经网络。由于预测变形网络是完全卷积的,没有引进额外的计算约束限制解空间。
1.1刚性配准
有学者使用CNN预测刚性配准矩阵,使用将六个转换参数(x,y轴1mm的位移和1°的旋转)分为三组的层次回归方法,使用变换对其的数据作为金标准,提升效率的原因是前向传播而没有使用优化算法进行配准;又有学者使用标准仿射变换与预测变换之间的MSE训练仿射图像配准网络(affine image registration network ,AIRNet);还有学者使用残差回归网络(进行初始配准)、校正网络(增强配准的范围)和基于双变测地距离的损失函数(bivariant geodesic distance based loss function);另外学者把成对域适应模块(a pairwise domain adaptation module ,PDA)放到预训练过的CNN网络中,域适应模块用来缓解合成数据与真实数据之间的差异;另有学者使用CNN来回归T1与T2加权MRI刚性配准变换的参数,同时提出了单模态与多模态的方案,单模态时,提取低级特征的卷积参数共享,多模态时分别学习参数。
1.2可变形配准
有学者使用U-Net与FCN网络获取可变变形场并且使用大微分纯度量映射(large diffeomorphic metric mapping)提供偏置参数;随后有学者使用改善的U-Net网络,利用网格分割计算给定图像对的参考变换,并使用SSD作为损失函数;有学者使用CNN对输入patches分别获取图像对应的位移向量,全部的位移向量构成配准场,他们还使用输入图像间的相似性来辅助训练,需要注意的是他们还是用均衡的主动点引导采样策略使得具有更高梯度大小和位移值的像素块更有可能被采样训练;有学者使用CNN进行非运动校正配准,还有学者将变换参数的变分高斯分布的低等级Hession近似值量化可变形配准相关的不确定性;还有学者使用DVFs增强数据集,并且使用多尺度CNN处理数据,得到不同的特征图后再经过尺寸处理得到相同大小特征图后进行组合(双通道)作为输入数据进行训练;还有使用3D-CNN网络(有监督时减少医学图像的使用)进行多尺度和随机变换消减了对标准数据集的需要,还保留了真实的图像特征;与上述方法不同,有学者使用统计特征模型(statistical appearance models ,SAMs)生成便准数据之后使用FlowNet网络进行训练,这个方法比CNN随机生成数据效果好;还有学者使用CNN学习标准数据生成的合理变形。
有监督变换预测方法的局限性在于配准的质量由标注的数据集的质量决定,并且标注数据由设计者的专业知识决定(掌握这种技能的专业人士较少),尽管使用合成标准数据集可以一定程度上缓解这个问题,但是确保合成数据与临床数据的相似性是非常有必要的。
2.双重/弱监督变换估计
双重监督变换是使用标准数据和量化相似性的度量来训练模型,弱监督变换是利用相关解剖结构分割重叠设计损失函数。
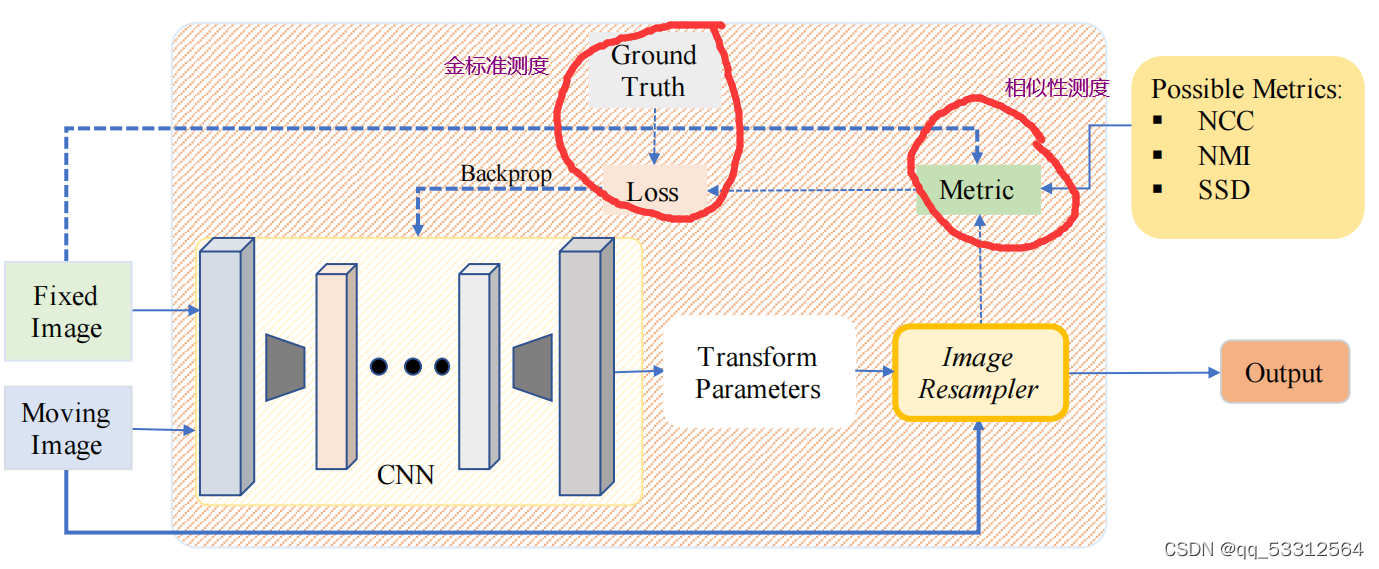
2.1双重监督
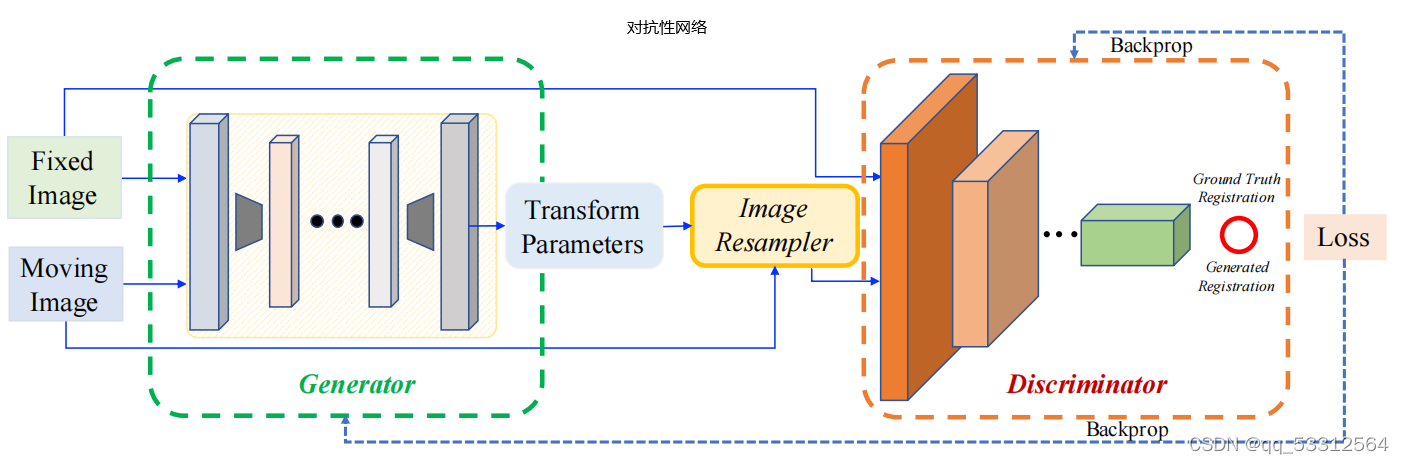
有学者使用分层、双重监督的策略,使用改良的U-Net网络(通过间隙填充“gap-filling”(u-net结束后插入卷积层)由粗到细的修改)使用预测图与标准图相似性和扭曲图与固定图像间的相似性两种相似性;还有学者受GAN网络激发,设计生成器用来预测刚性变换,鉴别器用来分别使用标准变换对齐的图像与使用预测变换对齐的图像,使用欧氏距离与对抗性损失来组成损失函数。
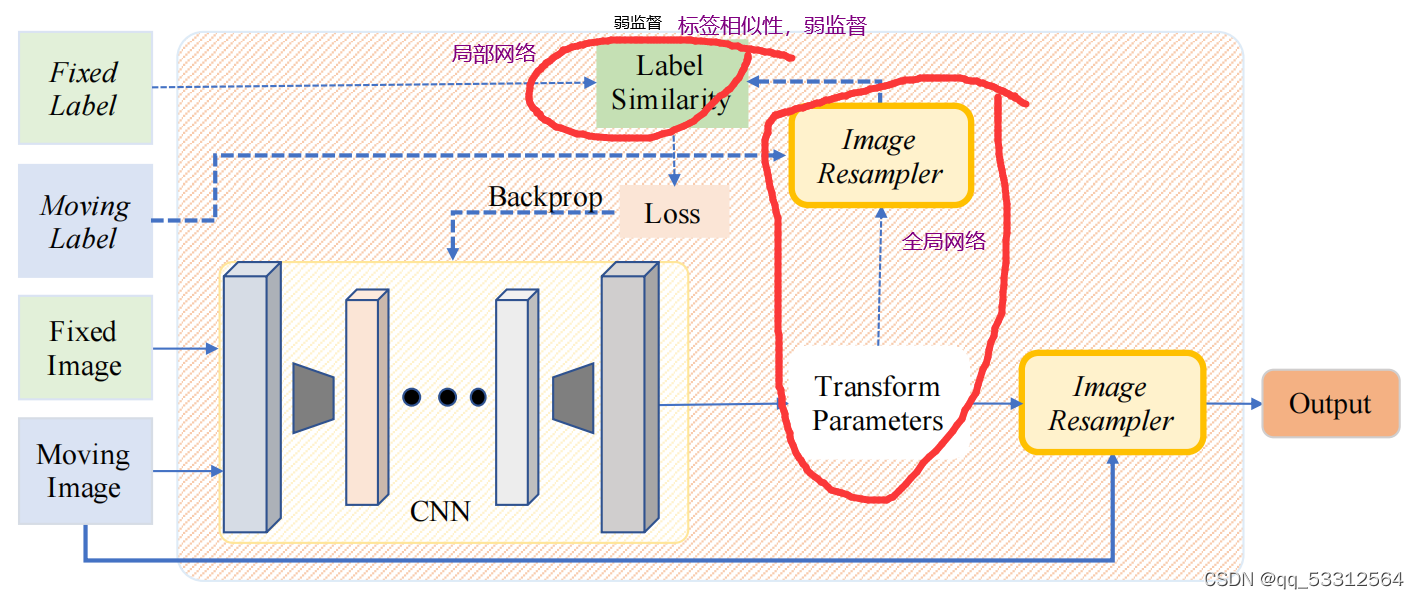
2.2弱监督
有学者使用标签相似性进行训练,使用局部网络(预测局部密集变形场)和全局网络(预测具有12个自由度的全局放射变换)两种网络进行训练学习,局部网络把全局网络输出的运动图像的变换与固定图像进行组合作为输入,之后再接一个端到端的框架。
还有学者同时使用最大化标签相似性和最小化一个对抗性损失项,目的是为了得到一个更符合实际的预测图像;还有学者在双重监督和弱监督的基础上引入基于标签和相似性度量的损失函数进行心脏动态跟踪,还使用分割重叠和基于边缘的归一化梯度场距离来构造损失函数。
一次预测对于深度学习来说已经是一个重大突破,但是对于数据的依赖性较强,部分/弱监督有效缓解了标准数据集(带有标签值的标准数据集)的需求问题,但是还是需要人工标注。弱监督允许在多模态的情况下进行相似性量化。
三、无监督变换估计
3.1基于无监督变换估计的相似性测度
相似性测度的流程图,与上面双重监督对比可知少了金标准损失值,所以为无监督。
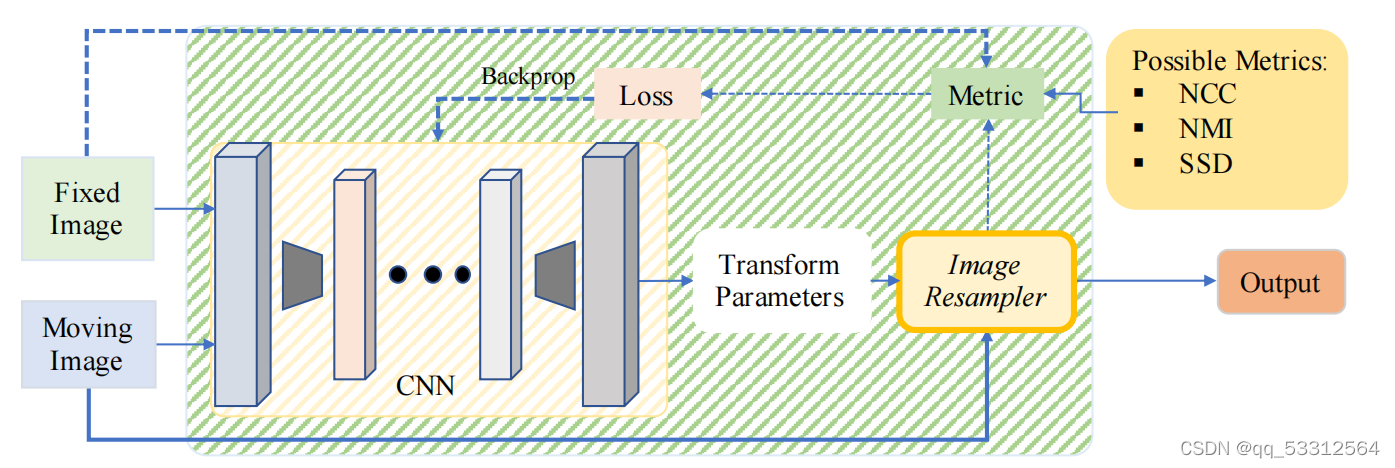
为了克服获取标准数据的困难,有学者提出使用FCN进行可变配准,使用NCC和其他正则化项(eg,平滑约束)作为损失函数 ,许多手工定义的相似性度量不适用于多模态的情况而是用于单模态的情况;还有学者使用NCC训练FCN进行配准,使用DVF对移动图像进行配准,还是用Elastix工具箱;还有学者在多个数据集上使用多阶段多尺度的方法进行单模态配准,使用NCC和弯曲能量正则化项训练网络,预测仿射变换,随后使用B样条变换模型进行由粗到细的变形;还有学者最小化扭曲图像与配准图像间的SSD上界;还有学者使用由粗到细的无监督变形配准,使用MSE作为损失函数;还有学者使用八个全连接层对学习到的潜在表征进行配准,通过嵌入法得到变形场,使用绝对误差和( sum of absolute errors ,SAE)作为损失函数;另有学者使用CNN进行线性和局部配准,估计了仿射变换(刚性)与变形(可变形),损失函数使用MSE与一个正则化项;还有学者使用神经网络学习相似性测量值与TRE之间的关系,是为了增强配准的可靠性;后又有学者使用级联的可变预测作为变分推理,将微分积分与变换器结合获得速度场,再对速度场进行平方和重新缩放后进行积分获得形变场,同样使用MSE和正则化项作为损失函数;还有提出一个Fiam框架,使用了初始化模块、低容量模式并使用残差链接而不是跳跃连接,相比于VoexlMorph也表现出良好的性能;另有学者使用基于迁移学习的方法,使用类U-Net框架进行特征提取和变换估计,使用NCC作为损失函数;虽然难以对多模态进行相似度测量,还是有学者提出由特征提取器和变形场生成器组成的3D-CNN模型,使用像素强度和梯度信息进行训练。
还有学者使用模态内的图像相似性进行多模态变形配准,NCC计算标准变形场扭曲的moving图像与预测变换扭曲的moving图像作为损失函数;另有学者使用反向一致深度网络( Inverse Consistent Deep Network,ICNet)学习对齐到同一空间(本人理解为fixed图像只有一个)的每个MR图像的对称微分变换,并且使用逆一致正则化项和反折叠正则化项,这样一个高度平滑约束不会导致形变场折叠,使用MSE作为相似性测度。
下述几个方法描述的为无监督的GAN网络。使用GAN网络隐式的学习合理变形范围的密度函数,除NMI外还添加了结构相似性索引度量(structual similarity index measure ,SSIM)和特征感知损失项,损失函数由条件约束和循环约束组成;还有学者使用GAN网络进行配准,使用鉴别器评估对齐质量这一点优于在数据集上使用真实数据、SSD、CC;另有学者使用GAN同时进行分割和配准,使用三个输入,fixed、moving、fixed图像的分割掩码,输出变换后图像的分割掩码和形变场,三个鉴别器使用循环一致性和DICE系数分别评估形变场、扭曲图像和分割的效果。
还有学者使用多网格B样条和L1范数正则化的CNN学习变形最优参数化,使用SSD作为相似性测量,L-BFGS-B作为优化,比传统的L1范数正则化多网格配准收敛速度快。
无监督方法大多数适用于单模态的配准,有待发展更多的无监督多模态配准方法。
3.2基于特征的无监督变换预测
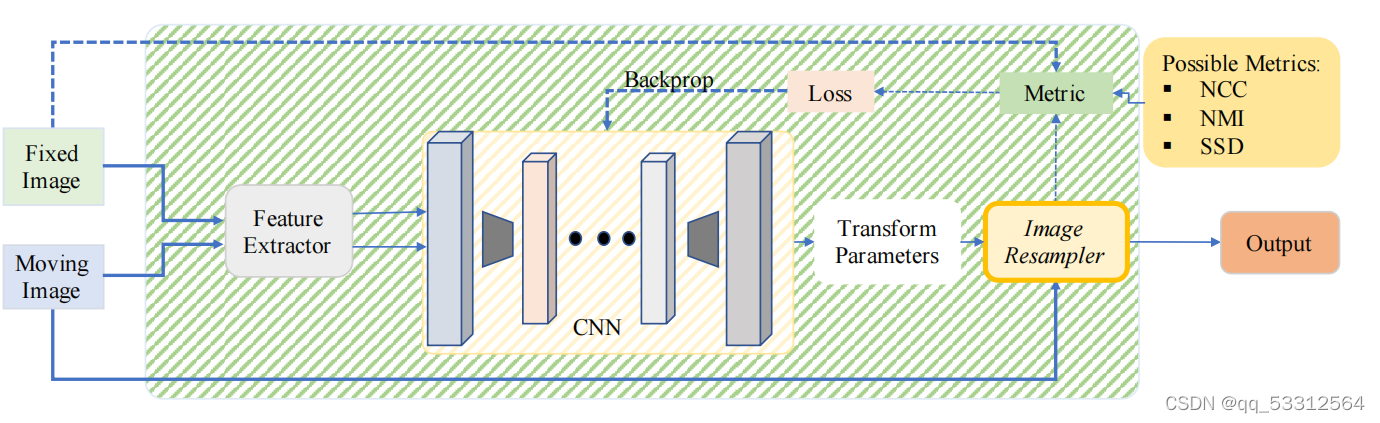
这是无监督的基于特征的配准流程图,相比于上图多了一个特征提取器,将输入图像映射到特征空间内,方便变换参数的与预测。
3.2.1单模态配准
有学者训练一个自编码器重建固定图像,利用重建的固定图像与相应的扭曲图像间L2距离及几个正则化项作为损失函数;还有学者使用基于张量的MIND方法利用主成分分析网络进行单模态与多模态配准;另有学者使用随即潜在空间学习方法绕开空间正则化进行配准,使用条件变分自编码器确保参数空间遵循规定的概率分布,利用潜在表示的固定图像的负对数及扭曲和KL散度作为损失函数。
3.2.2多模态配准
用与训练网络进行无监督的特征提取和仿射变换参数回归的配准方法,以DICE系数作为代价函数。
期待更多对于多模态的配准的研究,尤其对那些具有显著外观差异的。
4.研究趋势和未来方向
4.1深度对抗性图像配准
对抗性网络可以把鉴别器用作学习相似性测度、可以确保预测变换模型的真实性、可以进行图像转换(将多模态问题转换为单模态问题)。有些学者使用鉴别器判别对齐和未对齐图像对,但是需要预先对齐的图像对。鉴别器是用来区分所有具有相同标签的未对齐图像对,不希望建立一个错误的光谱坐标进行评判。可变形配准预测的形变场很大概率是不真实的,通常把L2范数、梯度或拉普拉斯常数项加入损失函数,但这样做会限制预测形变的大小,于是有学者提出使用类GAN网络,使用鉴别器约束形变预测。图像翻译也有利于使用单模态相似性测度,如果把图像翻译变成预处理过程必须,就可以使用常用的相似性度量来定义损失函数。
4.2基于强化学习的配准
基于强化学习的方法比较直观,可以模仿医生配准。深度学习面临的挑战包括变形配准得到变换空间的维数,使用基于强化学习的方法可以针对这一问题,
4.3原始图像域配准
有充分的实例论证深度学习可以将原始数据域的数据点映射到重建图像域进行重建。
5.总结
发展至已经有越来越多的深度学习方法,但都面临各自的挑战,共同的挑战是:缺乏多模态的相似性测度、数据量充足的数据集、标准数据的缺乏和量化模型预测的不确定性。重采样和插值往往不受研究人员的重视,应该给于这方面足够的重视。
仅供学习,侵权告删