Tree Indexes II
1 B+树设计选择
1.1 Node Size 节点大小
根据存储介质,我们可能更喜欢更大或更小的节点大小。 例如,存储在硬盘驱动器上的节点的大小通常为兆字节数量级,以减少查找数据所需的搜索次数并分摊大块数据上昂贵的磁盘读取,而内存数据库可能使用页面大小小到 512 字节作为节点,以便将整个页面放入 CPU 缓存中并减少数据碎片。 这种选择也可能取决于工作负载的类型,因为点查询希望页面尽可能小以减少加载的不必要的额外信息量,而大型顺序扫描可能更喜欢大页面以减少所需的提取次数 去做。
1.2 Merge Threshold 合并阈值
虽然 B+Trees 有关于在删除后合并下溢节点的规则,但有时它可能是有益的
暂时违反规则以减少删除操作的次数。例如,急切合并可以
导致颠簸,其中许多连续的删除和插入操作导致不断的拆分和合并。它
还允许批量合并,其中多个合并操作一次发生,减少数量
必须在树上占用昂贵的写锁存器的时间。
1.3 Variable Length Keys 变长键
目前我们只讨论了具有固定长度键的 B+树。但是我们可能也想支持可变长度的键,例如大键的小子集导致大量空间浪费的情况。那里
有几种方法可以解决这个问题:
- 指针
我们可以不直接存储键,而是存储一个指向键的指针。 由于必须为每个键追逐一个指针的效率低下,在生产中使用这种方法的唯一地方是嵌入式设备,其微小的寄存器和缓存可能会受益于这种空间节省。 - 变长节点
我们还可以像往常一样存储密钥,并允许可变长度的节点。 由于处理可变长度节点的显着内存管理开销,这是不可行的并且在很大程度上不被使用。 - 填充
我们可以将每个键的大小设置为最大键的大小并填充所有较短的键,而不是改变键的大小。 在大多数情况下,这是对内存的大量浪费,因此您也不会看到任何人使用它。 - Key Map/Indirection 键映射/间接
几乎每个人都使用的方法是用单独字典中键值对的索引替换键。 这提供了显着的空间节省和潜在的快捷点查询(因为索引指向的键值对与叶节点指向的键值对完全相同)。 由于字典索引值很小,有足够的空间在索引旁边放置每个键的前缀,可能允许一些索引搜索和叶扫描甚至不必追逐指针(如果前缀完全不同) 从搜索键)。
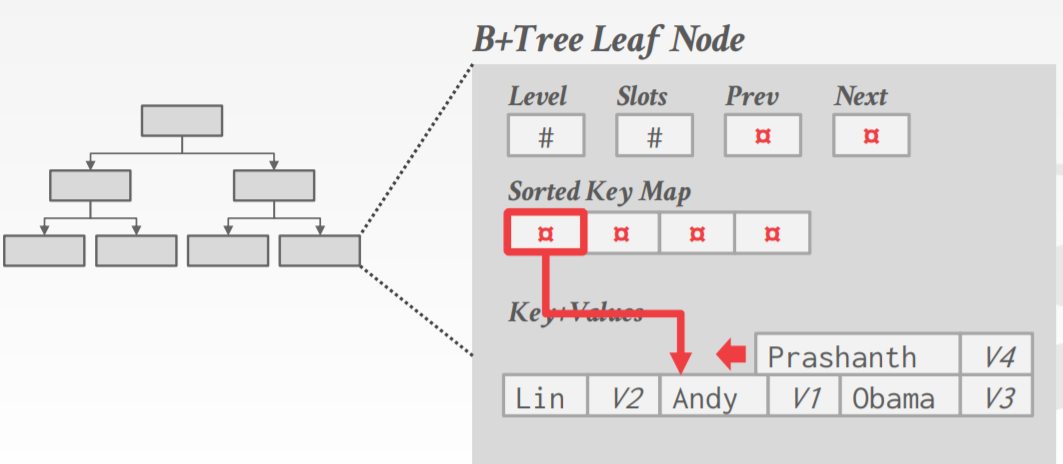
1.4 Intra-Node Search节点内搜索
一旦我们到达一个节点,我们仍然需要在该节点内进行搜索(要么从内部节点中找到下一个节点,要么在叶节点中找到我们的键值)。虽然这相对简单,但仍有一些权衡需要考虑:
- Linear线性
最简单的解决方案是只扫描节点中的每个键,直到找到我们的键。一方面,我们不必担心对键进行排序,从而更快地进行插入和删除。在另一方面,这是相对低效的,并且每次搜索的复杂度为 O(n)。
- Binary 二分
一个更有效的搜索解决方案是保持每个节点排序并使用二分搜索来找到键。这就像跳到节点的中间并根据情况向左或向右旋转一样简单
关于键之间的比较。这种方式的搜索效率更高,因为这种方法每次搜索的复杂度仅为 O(ln(n))。然而,插入变得更加昂贵,因为我们必须
维护每个节点的排序。
- Interpolation插值
最后,在某些情况下,我们可能能够利用插值来找到密钥。此方法利用存储的关于节点的任何元数据(例如最大元素、最小元素、平均值、等)并使用它来生成密钥的大致位置。例如,如果我们在一个节点中寻找 8 并且我们知道 10 是最大键,10 ? (n + 1) 是最小键(其中 n 是每个节点中的键数),那么我们知道从最大键开始向下搜索 2 个槽,因为在这种情况下,距离最大键一个槽的键必须是 9。尽管是我们给出的最快的方法,但由于其对具有某些属性(如整数)和复杂性的键的适用性有限,因此仅在学术数据库中看到这种方法。
2 Optimizations
2.1 Prefix Compression 前缀压缩
大多数情况下,当我们在同一个节点中有键时,每个键的某些前缀会有一些部分重叠(因为相似的键将在排序的 B+树中彼此相邻)。我们可以简单地在节点的开头存储一次前缀,然后只在每个槽中包含每个键的唯一部分,而不是将该前缀作为每个键的一部分多次存储。
2.2 Deduplication 去重
在允许非唯一键的索引的情况下,我们最终可能会得到包含相同键且附加不同值的叶节点。对此的一种优化可能只是编写密钥
一次,然后跟随它的所有相关值。
2.3 Suffix Truncation 后缀截断
**在大多数情况下,内部节点中的键条目仅用作路标而不是它们的实际键值(因为即使索引中存在键,我们仍然必须搜索到底部以确保它没有被删除) 。我们还可以通过仅在给定的内部节点上存储每个键的最小区分前缀来利用这一点。**虽然我们可以将其设置为最小的单个不同字符/数字,但在末尾保留一些冗余数字可能会有所帮助,以减少由于相同前缀而导致的不可确定插入发生的可能性。在这种情况下,我们必须搜索到树的底部以找到完整的键(或者在该键被删除的情况下,取决于叶节点的最小或最大键)。
2.4 Bulk Insert 批量插入
最初构建 B+Tree 时,必须以通常的方式插入每个键会导致不断的拆分操作。
由于我们已经给了叶子兄弟指针,如果我们构造一个叶子节点的排序链表,然后使用每个叶子节点的第一个键轻松地从下往上构建索引,那么初始插入数据的效率会更高。请注意,根据我们的上下文,我们可能希望尽可能紧密地包装叶子以节省空间或在每个叶子中留出空间以在需要拆分之前允许更多插入。
2.5 Pointer Swizzling 指针混淆
因为B+Tree的每个节点都存储在缓冲池中的一个页面中,所以每次加载新页面时都需要从缓冲池中获取,需要进行闩锁(锁存)和查找。为了完全跳过这一步,我们可以存储实际的原始指针代替页面 ID(称为“swizzling”),防止缓冲池获取
完全。与手动获取整个树并手动放置指针不同,我们可以在正常遍历索引时简单地存储从页面查找中得到的指针。请注意,我们必须跟踪哪些指针被 swizzled 并在它们指向的页面被取消固定和受害时将它们解调回页面 id。
3 额外的索引使用
索引是一种提供对数据项的快速访问的方法。 有许多索引方法和工具
数据库可以用来提高性能。
隐式索引
如果创建主键或唯一约束,大多数 DBMS 将自动创建隐式索引
强制执行完整性约束而不是引用约束。
部分索引
在许多情况下,用户可能不需要表中每个元组的索引,而可能只对一个
数据的子集。 部分索引是应用了某些条件或“where 子句”的索引,以便
它包括表的一个子集。 这可能会减少维护的规模和开销
表并避免不必要的数据污染缓冲池缓存。 例如,通常使用
部分索引是按日期范围(每月、每年等)对索引进行分区。

覆盖索引
如果处理查询所需的所有属性都在索引中可用,那么 DBMS 不需要
检索元组。 DBMS 只需根据索引中可用的数据即可完成整个查询。 换句话说,覆盖索引仅用于定位表中的数据记录,而不用于返回数据。 这减少了对 DBMS 缓冲池资源的争用。

索引包含列
索引包含列允许用户在索引中嵌入额外的列以支持仅索引查询。
这些额外的列存储在叶节点中,实际上并不是搜索键的一部分。

函数/表达式索引
也可以在函数或表达式上创建索引。 索引不需要以它们在基表中出现的相同方式存储键。 相反,函数/表达式索引将函数或表达式的输出存储为键而不是原始值。 DBMS 的工作是识别哪些查询可以使用该索引。

4 Trie Index
观察 B+Tree 中的内部节点键无法告诉您索引中是否存在键。 每次查找一个key,都必须遍历到叶子节点。
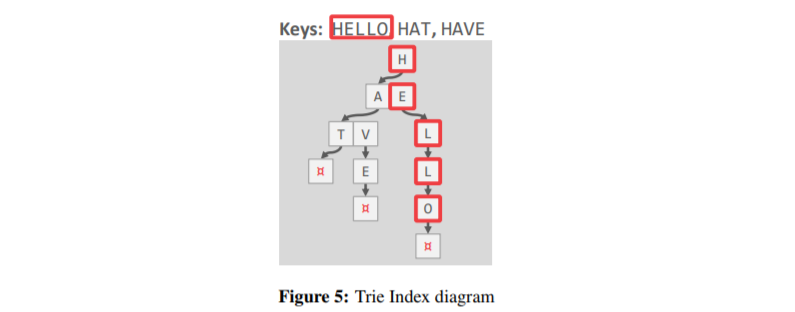
Trie Index 允许我们在树的顶部知道是否存在键。 特里索引使用键的数字表示来逐一检查前缀,而不是比较整个键。
Trie 索引有许多有用的属性。 一方面,它们的形状仅取决于密钥空间和长度,不需要重新平衡操作。 此外,所有操作都有 O(k) 复杂度,其中 k 是密钥的长度。 这是因为到叶子节点的路径代表叶子的键。Trie级别的跨度是每个部分密钥/数字代表的位数。
5 Radix Tree
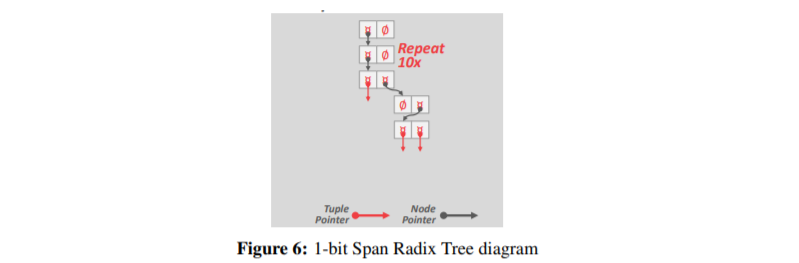
A radix tree is a variant of a trie data structure. 它与 trie 索引的不同之处在于省略了只有一个子节点的节点。 相反,节点被合并以表示键不同之前的最大前缀。
Radix Tree会产生误报,因此 DBMS 必须始终检查原始元组以查看键是否匹配。
Radix Tree的高度取决于键的长度,而不是像 B+Tree 中的键数。 到叶子节点的路径代表叶子的键。 并非所有属性类型都可以分解为基数树的二进制可比较数字。
6 Inverted Indexes 倒排索引
Inverted Indexes 存储单词到目标属性中包含这些单词的记录的映射。这些有时在 DBMS 中称为全文搜索索引。倒排索引对关键字搜索特别有用。
大多数主要的 DBMS 本身都支持倒排索引,但也有专门的 DBMS,这是唯一可用的表索引数据结构。
查询类型
倒排索引允许用户进行三种类型的查询,而这些查询不能在 B+Trees 上执行。首先,倒排索引允许短语搜索,它可以定位包含按给定顺序的单词列表的记录。
它们还允许邻近搜索,记录两个单词出现在彼此的 n 个单词中的位置。
第三,倒排索引允许通配符搜索,查找包含匹配某种模式(例如,正则表达式)的单词的记录。
设计决策
开发倒置树的两个主要决策决定是存储什么和何时更新。
倒排索引至少需要能够存储每条记录中包含的单词(用标点符号分隔)。它们还可能包括附加信息,例如词频、位置和其他信息。
元数据。
每次修改表时更新倒排索引既昂贵又缓慢。正因为如此,倒排索引通常会维护辅助数据结构来进行阶段更新,然后批量更新索引。