���ļ�¼1
-
- Abstract
- һRelated works
-
- A�߹���Ӱ�����
- Bͼ��������
- ��The Proposed method
-
- Aͼ��������
- B���ص������ӳ��
- C��̬ͼϸ��
- D��������ӳ��
- �������������
-
- A���ݼ�
- B��������
- C������
- D��ǩ��������������Ӱ��
- E������Ӱ��
- F���ڷ���Ablation Study
- Gѵ��ʱ��
- �����
���Ͼ�������ѧ Sheng Wan ��2019��9��26�շ�����Ԥӡ����վarxiv�ϣ� ���ӡ�
��������ѧϰͼ�������ڸ߹���ң�������Ӧ���ио�д�ıȽ������һƪ������������������ǿ���⣬���Ժ�鿴��
Abstract
�ⲿ���Ƕ��ڱ��ĵ�������ܡ�
-
�߹���Ӱ����༼���ķ�չ
- ���ڹ��������ʹ�ͳģʽʶ�����ģ�KNN��SVM
- �ںϿռ���Ϣ�ĸ߹���Ӱ��������ECHO classifier, Markov Random Field (MRF), mathematical morphology, Gabor filtering
��Щ���ڵ���ƽ�����ɺ�ͬ���Եļ�����ڽ���߹���Ӱ��������һ���IJ������ԣ���Ϊ���߿�����ContextAware Dynamic Graph Convolutional Network�� (CAD-GCN)��
-
���ģ�͵�����
- GCN �ܹ��ܺõIJ������ؼ�������Ĺ�ϵ��
- ����ͼӳ�䣨��pixel to region���ͷ�ӳ��(region to pixel)��ܲ����������Ĺ�ϵ��
��̬ͼϸ��������ȷ��������ؼ�Ĺ�ϵ�ͷ��־�ȷ�������ʾ��
-
ģ�Ͱ������������֣��Լ����ֵ�ԭ��
-
�������һ��������˼�Ĺ۵㣺deep stacking of local operations for creating a large receptive field with long range context has also been proven inefficient[1]�����ѵ�����������������Ұ�������ǵ�Ч�ģ�����Ȥ�Ŀ��Կ��ο�����һ������һ������������̡������������������⣬��������Ľ������������ʹ�� pixel-to-region assignment ��������ԭʼ������Ϣ���оۺϳɲ������ regions������ȹ���ķ���������Ӻ�����Ȼ�����GCN�ܹ��������������ݵ���������GCN������Щ regions ֮��ߵ���Ϣ, ��ͬregion ������Ϣ�������Ϳ��Բ���ͼ����Ĺ�ϵ��Ϣ��ͨ��������� CAD-GCN �ܻ��ں��ٵĽڵ������Ч�ı�ʾѧϰ�������� region-to-pixel assignment�任����õ������ص���Ϣ��
-
������һ������˼�Ĺ۵㣺ͨ���̶���ͼȥ��GCN���ڸ߹���Ӱ�����Ч���������룬��Ϊ����ŷ����þ����Ԥ����ͼ���ܲ��ʺϲ������ǵ���ʵ�����ԡ�Ϊ�˸��õ�ѧϰ�����Զ��������߲��þ���������̬����ȥ��ʾ region��
-
�����Ϊѧϰ����ͼ���ܰ������ʵ���������ӣ��ر����ڲ�ͬ������֮��ı߽總�����������ˡ���Ե������ edge filter�������Թ��˳�����ȷ����������ıߣ���ϸ��ͼ����ʾ�������Ĺ�ϵ��
-
���ں�������Ŀǰ����һ�ο����ⲻ�Ǻ����⣨2021/3/7д����������ͨ��һ��֮�����������ͣ���ͷ������ʱ�����Щ�о��ˣ�2021/3/8д�����������Ŀ��������������֮һ���Ƕ���顣
һRelated works
�ڱ����лع���һЩ�뱾�о���صĹ���HSI�����GCN�Ĵ������о���
A�߹���Ӱ�����
- ������
- ��-��Ϸ���
�����-�����Ϣ�ķ���
- �ṹ�˲���
- ��ѧ��̬ѧ����
- ����������
Bͼ��������
- Ƶ�����ص㣺ͨ��������������Ƶ��
- ������the convolution is defined as a weighted
average function over the neighbors of each node�� �ص㣺����Ŀ��ڵ㹹�����ʵ�����
��The Proposed method
��һС�ڽ�����ϸ�Ľ��� CAD-GCN ģ�͡���Ҫ����Ϊ�����Σ�һһ�������£�

Aͼ��������
GCN �����۲��֣��Թ�����һ������ͨ�û������κ�ѧϰͼ������Ķ�Ӧ�����գ���������ͼ������һƪ����ȥѧϰͼ������������۲��֣�������ƪ���Ķ���ͼ����������������DZȽ�����ģ�������Ϊ���䡣
������ڽ��ھ���A �Ĺ�������Ҫ��ע�����ڵ������ֶ�̬ͼϸ���ὲ��һ���֡�
B���ص������ӳ��
Ŀǰ���Ǻ�ȷ�������pixel-to-region�� SLIC�㷨������죬��Ϊ�����㷨�����Ƿdz��˽⡣������ο�һƪ���ͣ�������SLIC�㷨���ܡ�
����һ��ͼ��������Ҫ�Լ�����ҪҪ�ֶ��ٳ����ز��֣������ڷָ�ͼƬ��ʱ��Ҫ������Ҫ�ķָ��������ʼ��һЩ�㣬��Ϊ���ӣ�Ȼ�����������Щ�����Χ�ĵ㹲ͬ��ɳ����ء��������SLIC�㷨�ij�ʼ��������ϣ���ָ��ÿ�������ؾ����ܵش�С��࣬����˵��һ��1020��ͼ������ֳ�8�������أ���ʱ���Ҿ��Ⱦ��ȷָÿ����������25�����أ�Ϊ55�ij�ʼ�飬Ȼ������ľ������ķ����ݶ���С�ĵط������������ѡ�ڱ߽��ϣ�ͬʱ���;�����ʼ��ѡ���������ص�ļ��ʡ�����ͼ��

��ÿ�ε�������ֻ�������뵱ǰ��������2S��������ص㣬����ͼ�Ҿ��������뵱ǰ��������10�����ص����ڵ����ؼ�����롣���ﻹ�漰�˾���Ķ������⡣���½���ɫ����Ϳռ�������ֶ���������һ����Ϊ���յľ�����������Ͼ���pixel-to-region �ļ����⡣
C��̬ͼϸ��
������ϸ�����Ҹ�������Ϊͼ��֦��
���߶��ڹ���ͼ���ڽӾ���A�����˴��������������������ʱ��ԭʼ��ʽ������ N~(zi)\widetilde{N}\left(\mathbf{z}_{i}\right)N
(zi?)�������� z ���ڵ���������Ҳ������ z ���ڵ������������ڵ�����
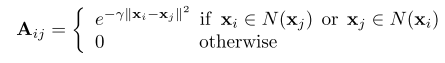
Ȼ��Ϊ�˳������ͼ�ṹ���������Ͼ��룬����ŷʽ���빹���ڽӾ���
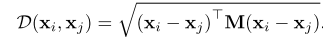
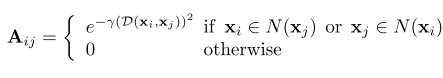
Ȼ����DZ�С�ڶ���һ���������Ľ�һ���ֹ������ڶ���ͼ�����У����ÿһ�㣬���¼����ڽӾ���
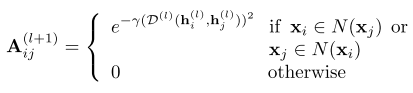
����hi(l)\mathbf{h}_{i}^{(l)}hi(l)?������ l ��ڵ� x ��������
Ȼ���ص����ˣ������һ�λ�����ֱ�ӷ��룺Since the intra-class examples are generally more similar than the inter-class ones, it is believed that the element Aij(l)\mathbf{A}_{i j}^{(l)}Aij(l)? with relatively small value is more likely to represent inter-class relations than the Aij(l)\mathbf{A}_{i j}^{(l)}Aij(l)? with large value. Therefore, we employ a threshold ��(l) for each graph convolutional layer to filter out the interclass relations and reduce the adverse effect of inter-class feature aggregation.
��������������������������ͨ���������ƣ������������������ű�ʾ���ڹ�ϵ��ֵAij(l)\mathbf{A}_{i j}^{(l)}Aij(l)? �Ƚϴ�ʾ����ϵ��ֵAij(l)\mathbf{A}_{i j}^{(l)}Aij(l)?С����ΪҪ֪��Aij(l)\mathbf{A}_{i j}^{(l)}Aij(l)?�ڷ����ʱ����һ�������½���������Ҫ���˸�ͼ��

�������߾ͼ���һ�����ƣ��趨��һ����ֵ��ֻ�д��������ֵ�IJű�����ϵ��������Ϊ0����
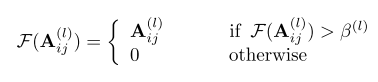
��������Dynamic Graph Refinement��
D��������ӳ��
����ֻ����һ���������Բ�ֵ����������������ص�ӳ�䣬��
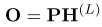
�����յ�ͼ�����������H(L)\mathbf{H}^{(L)}H(L)���������������������(P)\mathbf{(P)}(P)��ô��ʵ���˲�ֵ��Ŀǰ����֪������Ҫ������ġ�
�������������
��һС�ڽ��������飬�������������˷�����
A���ݼ�
�������������ݼ��Ͻ������飺Indian Pines��University of Pavia��Salinas��
B��������
ÿ�����ѡ��30�������㣬�������30�������������ѡ��15������Ϊѵ������ѵ������90%��Ϊѵ����10%��Ϊ��֤����
C������
������ͣ�Ц��������
D��ǩ��������������Ӱ��
������ͣ�Ц��������
E������Ӱ��
CAD-GCN��Ҫ��Ҫ�����ij������������ִΣ�ѧϰ���ʣ�������Ԫ��������ֵ������Ҫ���������Ķ��٣�һ�㶼�����㡣
F���ڷ���Ablation Study
��ν���ڷ�����ָ���ڹ���CAD-GCN�������Ҫ�������֣�ͼӳ�䣬��̬ͼϸ�����漰�����������ָĽ��Ľڵ�������ԭ�Ĺ�ʽ12�����˲���ԭ�Ĺ�ʽ13��������ģ�ͱ���������Ӱ�졣�����Ȼ��������ͣ�Ц��������
Gѵ��ʱ��
������ͣ�Ц����������̫��Ǯ�ˣ�with a 3.60GHz Intel Xeon CPU with 264 GB of RAM and a Tesla P40 GPU������
�����
������ͣ�Ц���������ܽ��ƪ���µ��ص�����ķ������������ص������ӳ�䣬��֦������ͼ��ӳ�䣬ֻ��Ҫ��ʱ����������У������Ҹо�������Ҫ�����������У��Լ������е��������ģ����빦��̫���ˣ�����Ŀǰ��Ҳû�д��롣
�ο����ף�
[1] W. Luo, Y. Li, R. Urtasun, and R. Zemel, ��Understanding the effective receptive field in deep convolutional neural networks,�� pp. 4898�C4906, 2016.
[2] WAN S, GONG C, ZHONG P, ��. Hyperspectral Image Classification With Context-Aware Dynamic Graph Convolutional Network[J]. arXiv:1909.11953 [cs, eess, stat], 2019.����
[3] SLIC����