�ȿ���������Ŀ���Ŀ¼��

����Ŀ�� Optimization Methods�С�
Until now, you've always used Gradient Descent to update the parameters and minimize the cost. In this notebook, you will learn more advanced optimization methods that can speed up learning and perhaps even get you to a better final value for the cost function. Having a good optimization algorithm can be the difference between waiting days vs. just a few hours to get a good result.

To get started, run the following code to import the libraries you will need.
import numpy as np
import matplotlib.pyplot as plt
import scipy.io
import math
import sklearn
import sklearn.datasetsfrom opt_utils import load_params_and_grads, initialize_parameters, forward_propagation, backward_propagation
from opt_utils import compute_cost, predict, predict_dec, plot_decision_boundary, load_dataset
from testCases import *%matplotlib inline
plt.rcParams['figure.figsize'] = (7.0, 4.0) # set default size of plots
plt.rcParams['image.interpolation'] = 'nearest'
plt.rcParams['image.cmap'] = 'gray'1 - Gradient Descent
A simple optimization method in machine learning is gradient descent (GD). When you take gradient steps with respect to all mm examples on each step, it is also called Batch Gradient Descent.

# GRADED FUNCTION: update_parameters_with_gddef update_parameters_with_gd(parameters, grads, learning_rate):"""Update parameters using one step of gradient descentArguments:parameters -- python dictionary containing your parameters to be updated:parameters['W' + str(l)] = Wlparameters['b' + str(l)] = blgrads -- python dictionary containing your gradients to update each parameters:grads['dW' + str(l)] = dWlgrads['db' + str(l)] = dbllearning_rate -- the learning rate, scalar.Returns:parameters -- python dictionary containing your updated parameters """L = len(parameters) // 2 # number of layers in the neural networks# Update rule for each parameterfor l in range(L):### START CODE HERE ### (approx. 2 lines)parameters["W" + str(l+1)] = parameters["W" + str(l+1)] - learning_rate * grads["dW"+str(l+1)]parameters["b" + str(l+1)] = parameters["b" + str(l+1)] - learning_rate * grads["db"+str(l+1)]### END CODE HERE ###return parametersparameters, grads, learning_rate = update_parameters_with_gd_test_case()parameters = update_parameters_with_gd(parameters, grads, learning_rate)
print("W1 = " + str(parameters["W1"]))
print("b1 = " + str(parameters["b1"]))
print("W2 = " + str(parameters["W2"]))
print("b2 = " + str(parameters["b2"]))
Expected Output:

A variant of this is Stochastic Gradient Descent (SGD), which is equivalent to mini-batch gradient descent where each mini-batch has just 1 example. The update rule that you have just implemented does not change. What changes is that you would be computing gradients on just one training example at a time, rather than on the whole training set. The code examples below illustrate the difference between stochastic gradient descent and (batch) gradient descent.
- (Batch) Gradient Descent:
-
X = data_input Y = labels parameters = initialize_parameters(layers_dims) for i in range(0, num_iterations):# Forward propagationa, caches = forward_propagation(X, parameters)# Compute cost.cost = compute_cost(a, Y)# Backward propagation.grads = backward_propagation(a, caches, parameters)# Update parameters.parameters = update_parameters(parameters, grads) - Stochastic Gradient Descent:
X = data_input Y = labels parameters = initialize_parameters(layers_dims) for i in range(0, num_iterations):for j in range(0, m):# Forward propagationa, caches = forward_propagation(X[:,j], parameters)# Compute costcost = compute_cost(a, Y[:,j])# Backward propagationgrads = backward_propagation(a, caches, parameters)# Update parameters.parameters = update_parameters(parameters, grads)In Stochastic Gradient Descent, you use only 1 training example before updating the gradients. When the training set is large, SGD can be faster. But the parameters will "oscillate" toward the minimum rather than converge smoothly. Here is an illustration of this:

Note also that implementing SGD requires 3 for-loops in total:

In practice, you'll often get faster results if you do not use neither the whole training set, nor only one training example, to perform each update. Mini-batch gradient descent uses an intermediate number of examples for each step. With mini-batch gradient descent, you loop over the mini-batches instead of looping over individual training examples.

What you should remember:
- The difference between gradient descent, mini-batch gradient descent and stochastic gradient descent is the number of examples you use to perform one update step.
- You have to tune a learning rate hyperparameter ����.
- With a well-turned mini-batch size, usually it outperforms either gradient descent or stochastic gradient descent (particularly when the training set is large).
2 - Mini-Batch Gradient descent
Let's learn how to build mini-batches from the training set (X, Y).
There are two steps:





# GRADED FUNCTION: random_mini_batchesdef random_mini_batches(X, Y, mini_batch_size = 64, seed = 0):"""Creates a list of random minibatches from (X, Y)Arguments:X -- input data, of shape (input size, number of examples)Y -- true "label" vector (1 for blue dot / 0 for red dot), of shape (1, number of examples)mini_batch_size -- size of the mini-batches, integerReturns:mini_batches -- list of synchronous (mini_batch_X, mini_batch_Y) ͬ���б�"""np.random.seed(seed) # To make your "random" minibatches the same as oursm = X.shape[1] # number of training examplesmini_batches = []# Step 1: Shuffle (X, Y)permutation = list(np.random.permutation(m))shuffled_X = X[:, permutation]shuffled_Y = Y[:, permutation].reshape((1,m))# Step 2: Partition (shuffled_X, shuffled_Y). Minus the end case.#Math.floor() ����С�ڻ����һ���������ֵ����������num_complete_minibatches = math.floor(m/mini_batch_size) # number of mini batches of size mini_batch_size in your partitionningfor k in range(0, num_complete_minibatches):### START CODE HERE ### (approx. 2 lines)mini_batch_X = shuffled_X[:,k*64:k*64+64]mini_batch_Y = shuffled_Y[:,k*64:k*64+64]### END CODE HERE ###mini_batch = (mini_batch_X, mini_batch_Y)mini_batches.append(mini_batch)# Handling the end case (last mini-batch < mini_batch_size)if m % mini_batch_size != 0:### START CODE HERE ### (approx. 2 lines)mini_batch_X = shuffled_X[:,num_complete_minibatches*64:m]mini_batch_Y = shuffled_Y[:,num_complete_minibatches*64:m]### END CODE HERE ###mini_batch = (mini_batch_X, mini_batch_Y)mini_batches.append(mini_batch)return mini_batchesX_assess, Y_assess, mini_batch_size = random_mini_batches_test_case()
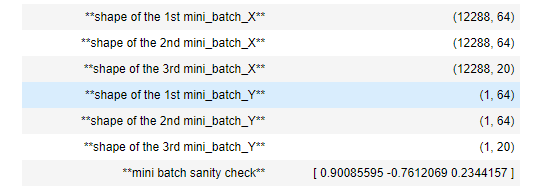
mini_batches = random_mini_batches(X_assess, Y_assess, mini_batch_size)print ("shape of the 1st mini_batch_X: " + str(mini_batches[0][0].shape))
print ("shape of the 2nd mini_batch_X: " + str(mini_batches[1][0].shape))
print ("shape of the 3rd mini_batch_X: " + str(mini_batches[2][0].shape))
print ("shape of the 1st mini_batch_Y: " + str(mini_batches[0][1].shape))
print ("shape of the 2nd mini_batch_Y: " + str(mini_batches[1][1].shape))
print ("shape of the 3rd mini_batch_Y: " + str(mini_batches[2][1].shape))
print ("mini batch sanity check: " + str(mini_batches[0][0][0][0:3]))
Expected Output:
What you should remember:
- Shuffling and Partitioning are the two steps required to build mini-batches
- Powers of two are often chosen to be the mini-batch size, e.g., 16, 32, 64, 128.
3 - Momentum
Because mini-batch gradient descent makes a parameter update after seeing just a subset of examples, the direction of the update has some variance, and so the path taken by mini-batch gradient descent will "oscillate" toward convergence. Using momentum can reduce these oscillations.
����С�����ݶ��½������ڿ���һ��ʾ���Ӽ���ͽ��в������£����Ը��µķ�����һ���ķ�����С�����ݶ��½������ߵ�·���������������������ö������Լ�����Щ��

 ���������˹�ȥ���ݶ���ƽ�����¡����ǽ��ڱ���v�д洢ǰ���ݶȵġ�������ʽ�ϣ�����֮ǰ�����ݶȵ�ָ����Ȩƽ��ֵ����Ҳ����v�����һ������ɽ����ġ��ٶȡ�������ɽ���¶�/�¶ȵķ��������ٶ�(�Ͷ���)�� ��ɫ��ͷ��ʾ�ķ���ȡ��һ�������С�����ݶ��½��붯������ɫ�ĵ��ʾÿһ�����ݶȵķ���(����ڵ�ǰ��С������)����ֻ�������ݶȣ��������ݶ�Ӱ��v��Ȼ������v�ķ�����һ����
���������˹�ȥ���ݶ���ƽ�����¡����ǽ��ڱ���v�д洢ǰ���ݶȵġ�������ʽ�ϣ�����֮ǰ�����ݶȵ�ָ����Ȩƽ��ֵ����Ҳ����v�����һ������ɽ����ġ��ٶȡ�������ɽ���¶�/�¶ȵķ��������ٶ�(�Ͷ���)�� ��ɫ��ͷ��ʾ�ķ���ȡ��һ�������С�����ݶ��½��붯������ɫ�ĵ��ʾÿһ�����ݶȵķ���(����ڵ�ǰ��С������)����ֻ�������ݶȣ��������ݶ�Ӱ��v��Ȼ������v�ķ�����һ����

# GRADED FUNCTION: initialize_velocitydef initialize_velocity(parameters):"""Initializes the velocity as a python dictionary with:- keys: "dW1", "db1", ..., "dWL", "dbL" - values: numpy arrays of zeros of the same shape as the corresponding gradients/parameters.Arguments:parameters -- python dictionary containing your parameters.parameters['W' + str(l)] = Wlparameters['b' + str(l)] = blReturns:v -- python dictionary containing the current velocity.v['dW' + str(l)] = velocity of dWlv['db' + str(l)] = velocity of dbl"""L = len(parameters) // 2 # number of layers in the neural networksv = {}# Initialize velocityfor l in range(L):### START CODE HERE ### (approx. 2 lines)
# v["dW" + str(l+1)] = np.zeros([parameters['W'+str(l+1)].shape[0],parameters['W'+str(l+1)].shape[1]])
# v["db" + str(l+1)] = np.zeros((parameters['b' + str(l+1)].shape[0],parameters['b' + str(l+1)].shape[1]))v["dW" + str(l+1)] = np.zeros_like(parameters['W'+str(l+1)])v["db" + str(l+1)] = np.zeros_like(parameters['b'+ str(l+1)])### END CODE HERE ###return vparameters = initialize_velocity_test_case()
print(parameters["W1"])
print(parameters["W2"])
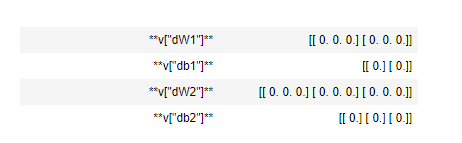
v = initialize_velocity(parameters)
print("v[\"dW1\"] = " + str(v["dW1"]))
print("v[\"db1\"] = " + str(v["db1"]))
print("v[\"dW2\"] = " + str(v["dW2"]))
print("v[\"db2\"] = " + str(v["db2"])) 
Expected Output:

# GRADED FUNCTION: update_parameters_with_momentumdef update_parameters_with_momentum(parameters, grads, v, beta, learning_rate):"""Update parameters using MomentumArguments:parameters -- python dictionary containing your parameters:parameters['W' + str(l)] = Wlparameters['b' + str(l)] = blgrads -- python dictionary containing your gradients for each parameters:grads['dW' + str(l)] = dWlgrads['db' + str(l)] = dblv -- python dictionary containing the current velocity:v['dW' + str(l)] = ...v['db' + str(l)] = ...beta -- the momentum hyperparameter, scalarlearning_rate -- the learning rate, scalarReturns:parameters -- python dictionary containing your updated parameters v -- python dictionary containing your updated velocities"""L = len(parameters) // 2 # number of layers in the neural networks# Momentum update for each parameterfor l in range(L):### START CODE HERE ### (approx. 4 lines)# compute velocities#v["dW" + str(l+1)] = beta * v["dW" + str(l+1)]+(1- beta)*grads["W"+ l+1]v["dW" + str(l+1)] = beta * v["dW" + str(l+1)] + (1- beta)*grads["dW"+ str(l+1)]v["db" + str(l+1)] = beta * v["db" + str(l+1)] + (1- beta)*grads["db"+str(l+1)]# update parameters parameters["W" + str(l+1)] = parameters['W' + str(l+1)] - learning_rate * v["dW" + str(l+1)]parameters["b" + str(l+1)] = parameters['b' + str(l+1)] - learning_rate * v["db" + str(l+1)] ### END CODE HERE ###return parameters, vparameters, grads, v = update_parameters_with_momentum_test_case()parameters, v = update_parameters_with_momentum(parameters, grads, v, beta = 0.9, learning_rate = 0.01)
print("W1 = " + str(parameters["W1"]))
print("b1 = " + str(parameters["b1"]))
print("W2 = " + str(parameters["W2"]))
print("b2 = " + str(parameters["b2"]))
print("v[\"dW1\"] = " + str(v["dW1"]))
print("v[\"db1\"] = " + str(v["db1"]))
print("v[\"dW2\"] = " + str(v["dW2"]))
print("v[\"db2\"] = " + str(v["db2"]))
Expected Output:

Note that:

![]()
4 - Adam
Adam is one of the most effective optimization algorithms for training neural networks. It combines ideas from RMSProp (described in lecture) and Momentum.
How does Adam work?


# GRADED FUNCTION: initialize_adamdef initialize_adam(parameters) :"""Initializes v and s as two python dictionaries with:- keys: "dW1", "db1", ..., "dWL", "dbL" - values: numpy arrays of zeros of the same shape as the corresponding gradients/parameters.ֵ:����Ӧ���ݶ�/������״��ͬ�����numpy���顣Arguments:parameters -- python dictionary containing your parameters.parameters["W" + str(l)] = Wlparameters["b" + str(l)] = blReturns: v -- python dictionary that will contain the exponentially weighted average of the gradient.v["dW" + str(l)] = ...v["db" + str(l)] = ...s -- python dictionary that will contain the exponentially weighted average of the squared gradient.s["dW" + str(l)] = ...s["db" + str(l)] = ..."""L = len(parameters) // 2 # number of layers in the neural networksv = {}s = {}# Initialize v, s. Input: "parameters". Outputs: "v, s".for l in range(L):### START CODE HERE ### (approx. 4 lines)v["dW" + str(l+1)] = np.zeros((parameters["W"+str(l+1)].shape[0], parameters["W"+str(l+1)].shape[1]))v["db" + str(l+1)] = np.zeros((parameters["b"+str(l+1)].shape[0], parameters["b"+str(l+1)].shape[1]))s["dW" + str(l+1)] = np.zeros((parameters["W"+str(l+1)].shape[0], parameters["W"+str(l+1)].shape[1]))s["db" + str(l+1)] = np.zeros_like(parameters['b'+ str(l+1)])### END CODE HERE ###return v, s
parameters = initialize_adam_test_case()v, s = initialize_adam(parameters)
print("v[\"dW1\"] = " + str(v["dW1"]))
print("v[\"db1\"] = " + str(v["db1"]))
print("v[\"dW2\"] = " + str(v["dW2"]))
print("v[\"db2\"] = " + str(v["db2"]))
print("s[\"dW1\"] = " + str(s["dW1"]))
print("s[\"db1\"] = " + str(s["db1"]))
print("s[\"dW2\"] = " + str(s["dW2"]))
print("s[\"db2\"] = " + str(s["db2"]))
Expected Output:

Exercise:

# GRADED FUNCTION: update_parameters_with_adamdef update_parameters_with_adam(parameters, grads, v, s, t, learning_rate = 0.01,beta1 = 0.9, beta2 = 0.999, epsilon = 1e-8):"""Update parameters using AdamArguments:parameters -- python dictionary containing your parameters:parameters['W' + str(l)] = Wlparameters['b' + str(l)] = blgrads -- python dictionary containing your gradients for each parameters:grads['dW' + str(l)] = dWlgrads['db' + str(l)] = dblv -- Adam variable, moving average of the first gradient, python dictionary Adam�������ƶ�ƽ���ĵ�һ���ݶȣ�python�ֵ�s -- Adam variable, moving average of the squared gradient, python dictionary Adam�������ƶ�ƽ���ĵ�һ���ݶȣ�python�ֵ�learning_rate -- the learning rate, scalar.beta1 -- Exponential decay hyperparameter for the first moment estimates ��һ���ص�ָ��˥������������beta2 -- Exponential decay hyperparameter for the second moment estimates epsilon -- hyperparameter preventing division by zero in Adam updatesReturns:parameters -- python dictionary containing your updated parameters v -- Adam variable, moving average of the first gradient, python dictionarys -- Adam variable, moving average of the squared gradient, python dictionary"""L = len(parameters) // 2 # number of layers in the neural networksv_corrected = {} # Initializing first moment estimate, python dictionarys_corrected = {} # Initializing second moment estimate, python dictionary# Perform Adam update on all parametersfor l in range(L):# Moving average of the gradients. Inputs: "v, grads, beta1". Output: "v".### START CODE HERE ### (approx. 2 lines)v["dW" + str(l+1)] = beta1 * v["dW" + str(l+1)] + (1-beta1)* grads['dW'+str(l+1)]v["db" + str(l+1)] = beta1 * v["db" + str(l+1)] + (1-beta1)* grads['db'+str(l+1)]### END CODE HERE #### Compute bias-corrected first moment estimate. Inputs: "v, beta1, t". Output: "v_corrected".### START CODE HERE ### (approx. 2 lines)v_corrected["dW" + str(l+1)] = v["dW" + str(l+1)] / (1 - np.power(beta1,t))#v_corrected["db" + str(l+1)] = v["db" + str(l+1)] / (1 - math.pow(beta1,l)) ����v_corrected["db" + str(l+1)] = v["db" + str(l+1)] / (1 - np.power(beta1,t))### END CODE HERE #### Moving average of the squared gradients. Inputs: "s, grads, beta2". Output: "s".### START CODE HERE ### (approx. 2 lines)s["dW" + str(l+1)] = beta2 * s["dW" + str(l+1)] + (1-beta2)* np.square(grads["dW" + str(l+1)])#s["db" + str(l+1)] = beta2 * s["db" + str(l+1)] + (1-beta2)* math.pow(grads["db" + str(l+1)],2) ����s["db" + str(l+1)] = beta2 * s["db" + str(l+1)] + (1-beta2)* np.square(grads["db" + str(l+1)])### END CODE HERE #### Compute bias-corrected second raw moment estimate. Inputs: "s, beta2, t". Output: "s_corrected".### START CODE HERE ### (approx. 2 lines)s_corrected["dW" + str(l+1)] = s["dW" + str(l+1)] / (1 - np.power(beta2, t))s_corrected["db" + str(l+1)] = s["db" + str(l+1)] / (1 - np.power(beta2, t))### END CODE HERE #### Update parameters. Inputs: "parameters, learning_rate, v_corrected, s_corrected, epsilon". Output: "parameters".### START CODE HERE ### (approx. 2 lines)#parameters["W" + str(l+1)] = parameters["W" + str(l+1)] - learning_rate * (v_corrected["dW" + str(l+1)] / (math.pow( s_corrected["dW" + str(l+1)], 1/2))+epsilon) ����parameters["W" + str(l+1)] = parameters["W" + str(l+1)] - learning_rate * (v_corrected["dW" + str(l+1)] / np.sqrt(s_corrected["dW" + str(l+1)]+epsilon)) parameters["b" + str(l+1)] = parameters["b" + str(l+1)] - learning_rate * (v_corrected["db" + str(l+1)] / np.sqrt(s_corrected["db" + str(l+1)]+epsilon))### END CODE HERE ###return parameters, v, sparameters, grads, v, s = update_parameters_with_adam_test_case()
parameters, v, s = update_parameters_with_adam(parameters, grads, v, s, t = 2)print("W1 = " + str(parameters["W1"]))
print("b1 = " + str(parameters["b1"]))
print("W2 = " + str(parameters["W2"]))
print("b2 = " + str(parameters["b2"]))
print("v[\"dW1\"] = " + str(v["dW1"]))
print("v[\"db1\"] = " + str(v["db1"]))
print("v[\"dW2\"] = " + str(v["dW2"]))
print("v[\"db2\"] = " + str(v["db2"]))
print("s[\"dW1\"] = " + str(s["dW1"]))
print("s[\"db1\"] = " + str(s["db1"]))
print("s[\"dW2\"] = " + str(s["dW2"]))
print("s[\"db2\"] = " + str(s["db2"]))
Expected Output:

You now have three working optimization algorithms (mini-batch gradient descent, Momentum, Adam). Let's implement a model with each of these optimizers and observe the difference.
�ܽ�һ�µĶ�����
1��TypeError: data type not understood
���ʹ��Python����һ�����飬����ij���Ϊ1024�������Ԫ��ȫΪ0��
�ܼ��� ʹ��zeros(1024) ����ʵ�֣�
��β���һ��2��1024��ȫ0�����أ��Ƿ���zeros(2,1024) ?
������������д���ͻ���� TypeError: data type not understood ���ִ���
��ȷ��д���� zeros((2,1024))��python�Ķ�ά���ݱ�ʾҪ�ö������������б�ʾ��
��ά�����Ƿ�ʹ���������ţ���һ�ԣ���Ȼ������ȷ������Բ�һ�£� �������������е����ֱַ����ʲô���壿
In [9]: zeros(((2,2,3)))
Out[9]:
array([[[ 0., 0., 0.],
[ 0., 0., 0.]],
[[ 0., 0., 0.],
[ 0., 0., 0.]]])
---------------------
2��python֮numpy.power()����Ԫ����n�η� �� math.pow()��������
-
numpy.power(x1, x2)
-
�����Ԫ�طֱ���n�η���x2���������֣�Ҳ���������飬����x1��x2������Ҫ��ͬ��

3��ƽ������ ƽ��
np.square(grads["dW" + str(l + 1)])
np.sqrt(s_corrected["dW" + str(l + 1)] + epsilon) ע�������epsilon�Ƿ��ڸ��������ѽ��