- KMP算法
-
- 步骤
- KMP完整代码模板
- 例题
-
- String Commutativity (2020ccpc湖南省赛题)
- BM算法
-
- 原理
- BM算法代码实现
-
- 坏字符
- 好后缀
- 完整代码
- Sunday算法
-
- 原理
- 代码模板
KMP算法
KMP的匹配是从模式串的开头开始匹配的
步骤
①寻找前缀后缀最长公共元素长度
如果给定的模式串是:“ABCDABD”,从左至右遍历整个模式串,其各个子串的前缀后缀分别如下表格所示:


②求next数组
找最大对称长度的前缀后缀,然后整体右移一位,初值赋为-1(当然,你也可以直接计算某个字符对应的next值,就是看这个字符之前的字符串中有多大长度的相同前缀后缀)。


③根据next数组进行匹配
KMP的next 数组相当于告诉我们:当模式串中的某个字符跟文本串中的某个字符匹配失配时,模式串下一步应该跳到哪个位置。如模式串中在j 处的字符跟文本串在i 处的字符匹配失配时,下一步用next [j] 处的字符继续跟文本串i 处的字符匹配,相当于模式串向右移动 j - next[j] 位。
KMP完整代码模板
// s[]是模板串,p[]是子串,n是s的长度,m是p的长度
//求模式串的Next数组:
for (int i = 2, j = 0; i <= m; i ++ )
{
while (j && p[i] != p[j + 1]) j = ne[j];if (p[i] == p[j + 1]) j ++ ;ne[i] = j;
}// 匹配
for (int i = 1, j = 0; i <= n; i ++ )
{
while (j && s[i] != p[j + 1]) j = ne[j];if (s[i] == p[j + 1]) j ++ ;if (j == m){
j = ne[j];// 匹配成功后的逻辑}
}例题
String Commutativity (2020ccpc湖南省赛题)
题目描述
Bobo has n strings s1, … , sn, and he would like to find the number of pairs i < j where si + sj = sj + si.
Note that a + b means the concatenation of the string a and b, i.e., writing the string a first, and the string b second.
输入描述:
The input consists of several test cases terminated by end-of-file.
The first line of each test case contains an integer n. The i-th of the following n lines contains a string si.
・ 1 ≤ n ≤ 10^5
・ |si| ≤ 10^6, si contains only lower case characters.
・ The sum of strings does not exceed 5×10^6
输出描述:
For each test case, print an integer which denotes the result.
示例1
输入
2
a
ab
2
ab
ab
3
a
aa
aaa
输出
0
1
3
题意:
求满足 si + sj = sj + si pair(i, j)数。
思路:
由于是找前后连接起来相同的字符串对数,所以就需要sj字符串和si的前缀和后缀相同,即为循环节的定义,用最小循环表示各个字符串即可。
#include<iostream>
#include<map>
using namespace std;typedef long long ll;
const ll maxn = 1e6 + 100;
const ll N = 1e6 + 100;
const int inf32 = 0x3f3f3f3f;
const ll inf64 = 0x3f3f3f3f3f3f3f3f;
const double eps = 1e-8;map<string, ll> p;
string s, s1;
ll n, m;
ll nex[maxn];void getnex()
{
//kmp找next数组int j = -1;nex[0] = -1;int i = 0;int len = s.length();while(i < len){
if(j == -1 || s[i] == s[j]){
i++;j++;nex[i] = j;}elsej = nex[j];}
}int main()
{
while(cin >> m){
ll ans = 0;for(int i = 1; i <= m; ++i){
cin >> s;n = s.length();getnex();ll k = 0;if(n % (n - nex[n]))//自己本身是最小循环节 k = 1;elsek = n / (n - nex[n]);s1 = s.substr(0, n / k);//获取最小循环节ans += p[s1];p[s1]++;//数量加1 }cout << ans << endl;p.clear();}return 0;
}
BM算法
从模式串的尾部开始匹配,且拥有在最坏情况下O(N)的时间复杂度。在实践中,比KMP算法的实际效能高。
原理
BM算法定义了两个规则:
- 坏字符规则:当文本串中的某个字符跟模式串的某个字符不匹配时,我们称文本串中的这个失配字符为坏字符,此时模式串需要向右移动,移动的位数 = 坏字符在模式串中的位置 - 坏字符在模式串中最右出现的位置。此外,如果"坏字符"不包含在模式串之中,则最右出现位置为-1。
- 好后缀规则:当字符失配时,后移位数 = 好后缀在模式串中的位置 - 好后缀在模式串上一次出现的位置,且如果好后缀在模式串中没有再次出现,则为-1。
下面举例说明BM算法。例如,给定文本串“HERE IS A SIMPLE EXAMPLE”,和模式串“EXAMPLE”,现要查找模式串是否在文本串中,如果存在,返回模式串在文本串中的位置。
-
首先,"文本串"与"模式串"头部对齐,从尾部开始比较。"S"与"E"不匹配。这时,“S"就被称为"坏字符”(bad character),即不匹配的字符,它对应着模式串的第6位。且"S"不包含在模式串"EXAMPLE"之中(相当于最右出现位置是-1),这意味着可以把模式串后移6-(-1)=7位,从而直接移到"S"的后一位。

-
依然从尾部开始比较,发现"P"与"E"不匹配,所以"P"是"坏字符"。但是,"P"包含在模式串"EXAMPLE"之中。因为“P”这个“坏字符”对应着模式串的第6位(从0开始编号),且在模式串中的最右出现位置为4,所以,将模式串后移6-4=2位,两个"P"对齐。

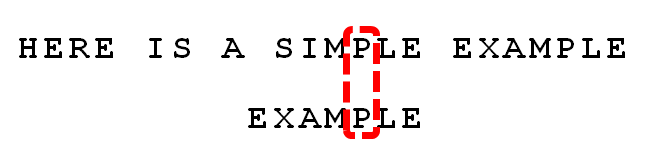
-
依次比较,得到 “MPLE”匹配,称为"好后缀"(good suffix),即所有尾部匹配的字符串。注意,“MPLE”、“PLE”、“LE”、"E"都是好后缀。

-
发现“I”与“A”不匹配:“I”是坏字符。如果是根据坏字符规则,此时模式串应该后移2-(-1)=3位。问题是,有没有更优的移法?
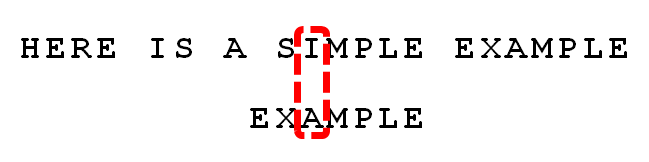
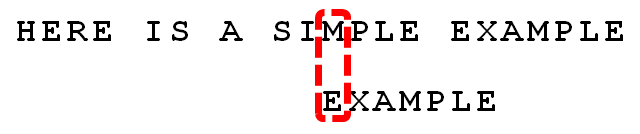
-
更优的移法是利用好后缀规则:当字符失配时,后移位数 = 好后缀在模式串中的位置 - 好后缀在模式串中上一次出现的位置,且如果好后缀在模式串中没有再次出现,则为-1。
所有的“好后缀”(MPLE、PLE、LE、E)之中,只有“E”在“EXAMPLE”的头部出现,所以后移6-0=6位。
可以看出,“坏字符规则”只能移3位,“好后缀规则”可以移6位。每次后移这两个规则之中的较大值。这两个规则的移动位数,只与模式串有关,与原文本串无关。

-
继续从尾部开始比较,“P”与“E”不匹配,因此“P”是“坏字符”,根据“坏字符规则”,后移 6 - 4 = 2位。因为是最后一位就失配,尚未获得好后缀。

BM算法代码实现
坏字符
找到坏字符在模式串中的位置(有重复的,则是靠后的那个)
采用哈希,而不是遍历。

#define SIZE 256 //字符集字符数
void generateBadChar(char *b, int m, int *badchar)//(模式串字符b,模式串长度m,模式串的哈希表)
{
int i, ascii;for(i = 0; i < SIZE; ++i){
badchar[i] = -1;//哈希表初始化为-1}for(i = 0; i < m; ++i){
ascii = int(b[i]); //计算字符的ASCII值badchar[ascii] = i;//重复字符被覆盖,记录的是最后出现的该字符的位置}
}
int str_bm(char *a, int n, char *b, int m)
//只考虑坏字符方法的程序框架
{
int *badchar = new int [SIZE];//记录模式串中每个字符最后出现的位置generateBadChar(b,m,hash); //构建坏字符哈希表int i = 0, j;while(i < n-m+1){
for(j = m -1; j >= 0; --j) //模式串从后往前匹配{
if(a[i+j] != b[j])break; //坏字符对应模式串中的下标是j}if(j < 0) //匹配成功{
return i; //返回主串与模式串第一个匹配的字符的位置}//这里等同于将模式串往后滑动 j-badchar[int(a[i+j])] 位i = i + (j - badchar[int(a[i+j])]);}return -1;
}好后缀
- 在模式串中,查找跟好后缀匹配的另一个子串
- 在好后缀的后缀子串中,查找最长的、能跟模式串前缀子串匹配的后缀子串
不考虑效率的话,上面两个操作都可以暴力查找;
解决办法: 预先对模式串进行处理。


实现过程:

预处理模式串,填充suffix,prefix
void generateGS(char *b, int m, int *suffix, bool *prefix)
//预处理模式串,填充suffix,prefix
{
int i, j, k;for(i = 0; i < m; ++i)//两个数组初始化{
suffix[i] = -1;prefix[i] = false;}for(i = 0; i < m-1; ++i)//b[0,i]{
j = i;k = 0;//公共后缀子串长度(模式串尾部取k个出来,分别比较)while(j >= 0 && b[j] == b[m-1-k])//与b[0,m-1]求公共后缀子串{
--j;++k;suffix[k] = j+1;//相同后缀子串长度为k时,该子串在b[0,i]中的起始下标// (如果有多个相同长度的子串,被赋值覆盖,存较大的)}if(j == -1)//查找到模式串的头部了prefix[k] = true;//如果公共后缀子串也是模式串的前缀子串}
}计算滑动位数
-
case1:

-
case2:

-
case3:(以上都不成立,移动整个模式串(长度m))

完整代码
/*** @description: 字符匹配BM算法* @author: michael ming* @date: 2019/6/18 22:19* @modified by: */
#include <algorithm>
#include <string>
#include <iostream>using namespace std;
#define SIZE 256 //字符集字符数
void generateBadChar(char *b, int m, int *badchar)//(模式串字符b,模式串长度m,模式串的哈希表)
{
int i, ascii;for(i = 0; i < SIZE; ++i){
badchar[i] = -1;//哈希表初始化为-1}for(i = 0; i < m; ++i){
ascii = int(b[i]); //计算字符的ASCII值badchar[ascii] = i;//重复字符被覆盖,记录的是最后出现的该字符的位置}
}
void generateGS(char *b, int m, int *suffix, bool *prefix)//预处理模式串,填充suffix,prefix
{
int i, j, k;for(i = 0; i < m; ++i)//两个数组初始化{
suffix[i] = -1;prefix[i] = false;}for(i = 0; i < m-1; ++i)//b[0,i]{
j = i;k = 0;//公共后缀子串长度(模式串尾部取k个出来,分别比较)while(j >= 0 && b[j] == b[m-1-k])//与b[0,m-1]求公共后缀子串{
--j;++k;suffix[k] = j+1;//相同后缀子串长度为k时,该子串在b[0,i]中的起始下标// (如果有多个相同长度的子串,被赋值覆盖,存较大的)}if(j == -1)//查找到模式串的头部了prefix[k] = true;//如果公共后缀子串也是模式串的前缀子串}
}
int moveByGS(int j, int m, int *suffix, bool *prefix)//传入的j是坏字符对应的模式串中的字符下标
{
int k = m - 1 - j;//好后缀长度if(suffix[k] != -1)//case1,找到跟好后缀一样的模式子串(多个的话,存的靠后的那个(子串起始下标))return j - suffix[k] + 1;for(int r = j + 2; r < m; ++r)//case2{
if(prefix[m-r] == true)//m-r是好后缀的子串的长度,如果这个好后缀的子串是模式串的前缀子串return r;//在上面没有找到相同的好后缀下,移动r位,对齐前缀到好后缀}return m;//case3,都没有匹配的,移动m位(模式串长度)
}
int str_bm(char *a, int n, char *b, int m)//a表示主串,长n; b表示模式串,长m
{
int *badchar = new int [SIZE];//记录模式串中每个字符最后出现的位置generateBadChar(b,m,badchar); //构建坏字符哈希表int *suffix = new int [m];bool *prefix = new bool [m];generateGS(b, m, suffix, prefix); //预处理模式串,填充suffix,prefixint i = 0, j, moveLen1, moveLen2;//j表示主串与模式串匹配的第一个字符while(i < n-m+1){
for(j = m -1; j >= 0; --j) //模式串从后往前匹配{
if(a[i+j] != b[j])break; //坏字符对应模式串中的下标是j}if(j < 0) //匹配成功{
delete [] badchar;delete [] suffix;delete [] prefix;return i; //返回主串与模式串第一个匹配的字符的位置}//这里等同于将模式串往后滑动 j-badchar[int(a[i+j])] 位moveLen1 = j - badchar[int(a[i+j])];//按照坏字符规则移动距离moveLen2 = 0;if(j < m-1)//如果有好后缀的话{
moveLen2 = moveByGS(j,m,suffix,prefix);//按照好后缀规则移动距离}i = i + max(moveLen1,moveLen2);//取大的移动}delete [] badchar;delete [] suffix;delete [] prefix;return -1;
}int main()
{
string a = "abcacabcbcbacabc", b = "cbacabc";cout << a << "中第一次出现" << b << "的位置(从0开始)是:" << str_bm(&a[0],a.size(),&b[0],b.size());return 0;
}
https://www.cnblogs.com/zhouzhendong/p/Berlekamp-Massey.html
Sunday算法
原理
思想跟BM算法很相似。
只不过Sunday算法是从前往后匹配,在匹配失败时关注的是文本串中参加匹配的最末位字符的下一位字符。
如果该字符没有在模式串中出现则直接跳过,即移动位数 = 匹配串长度 + 1;
否则,其移动位数 = 模式串中最右端的该字符到末尾的距离+1。

代码模板
#include<iostream>
#include<cstdio>
#include<cstring>
using namespace std;
int wei[301]={
0};
int ans=0,lend,lenc,tot=0;//tot用于统计匹配次数,便于直观地与其他算法比较
char c[10001],d[10001];
void pei()
{
int w=0;//记录d匹配失败以后向右移动的数量while(w+lend<=lenc){
int i=0;//正在匹配的位数bool f=false;//默次数认匹配成功while(i<=lend && f==false){
if(c[i+w]!=d[i])f=true;//匹配失败i++;tot++;// 匹配下一位,匹配次数+1}if(f==false){
ans++;cout<<i<<endl;w++;}//当匹配成功的话就让b串整体右移一位,与a串的下一位进行匹配else//匹配失败{
i=lend+1;// 直接匹配a串中b串再次出现的位置if(wei[c[i+w]]==-1)w=w+i+1;//没有出现过得话,就让b串整体右移lend+1位else w=w+i-wei[c[w+i]];//如果出现过的话就跳到出现位置?}}return;
}
int main()
{
gets(c);gets(d);lenc=strlen(c)-1;lend=strlen(d)-1;for(int i=0;i<=300;++i)wei[i]=-1;for(int i=0;i<=lend;++i)wei[d[i]]=i;//记录每一个字符出现的位置pei();if(ans)cout<<ans<<endl<<tot;else cout<<"mission failed";return 0;
}