����ѧϰ��1.STL��� 2.̰���㷨
һ
STL���
һ.string �� ��ʾ�ɱ䳤�ȵ��ַ����У���char���͵�������õĶࣩ
ͷ�ļ���
string��ʹ��
��1��
��ʼ��
�����Զ�string���͵ı���ֱ�Ӹ�ֵ��
string str;
str="abcd";
��2��
string �ķ���
1��ͨ���±���ʣ��������ַ����飩
#include<bits/stdc++.h>
using namespace std;
int main(){
string str;cin>>str;for(int i=0;i<str.length();i++)cout<<str[i];return 0;}
������
abcd
abcd
���⣺
���Ҫֱ����������������ַ�����ֻ����cin��cout��
��1��
��ѭ����ȡδ֪������string����
string str��
while��cin>>str��cout<<str<<ebdl;
(2)����getline()����

string line;
while(getline(cin,line)cout<<line<<endl;
��2����ʹ�õ���������
������ĵ��������ǿ��Ե���һ��ָ�룩
1���������Ķ���
string ::iterator it;
::���������������A::B��ʾ������A�е�����B��A���������ֿռ䡢�ࡢ�ṹ
����ʹ�ã�
#include<bits/stdc++.h>
using namespace std;
int main(){
string str="abcd";for(string::iterator it = str.begin();it!=str.end();it++)cout<<*it;return 0;}
(3)
1.
empty()�������ж�string�����Ƿ�Ϊ�գ�����һ������ֵ
string str;
cin>>str;
if(!str.empty())//���str��Ϊ�գ������str��cout<<str<<endl;
size��������
����string����ij���
string str;
cin>>str;
if(str.size()==5)//������ȵ���5�����strcout<<str<<endl;
3
�Ƚ�string����
��С��ϵ�����ֵ�˳���岢���ִ�Сд��ĸ
string s1="hello";
string s2="hello world";//s2>s1
string s3="Hello";//s3<s1,s3<s2
4
string���������
string s1="hello",s2="world,s3;
s3=s1;
s3=s1+s2;
����
ջ��Stack��
���Ƚ������ֻ�ܲ�����˵�Ԫ�أ�
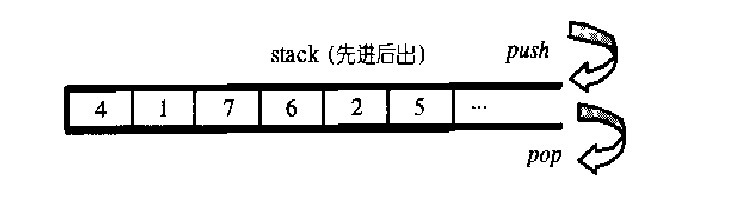
1����ζ���һ��ջ
stack<data_type>stack_name
���磺stacks;
2:
ջ�IJ�����
empty���� ����bool�ͣ���ʾջ���Ƿ�Ϊ�գ�s.empty()��
size() ����ջ��Ԫ�صĸ�����s.size()��
top() ����ջ��Ԫ��ֵ��s.top������
pop() �Ƴ�ջ��Ԫ�أ�s.pop()��
push(data_type a) ��ջ��ѹ��һ��Ԫ�أ�s.push��a����
��
����queue��
���Ƚ��ȳ���

1����ζ���һ������
queue<data_type>queue_name
���磺queues;
2:
ջ�IJ�����
empty���� ����bool�ͣ���ʾqueue�Ƿ�Ϊ�գ�s.empty()��
size() ����queueԪ�صĸ�����s.size()��
front () ����queue�ڵ���һ��Ԫ�أ�s.front()��
back() ����queue�ڵ����һ��Ԫ�أ�s.back()��
pop() �Ƴ�queue�е�һ��Ԫ�أ�s.pop()��
push(data_type a) ��queueѹ��һ��Ԫ�أ�s.push��a����
��
��̬���� Vector
1:
vector ��Ӧ��
���壺vector <data_type> vector_name;
�磺vector v;
������
empty() �C ����bool�ͣ���ʾvector�Ƿ�Ϊ�� (v.empty() )
size() �C ����vector��Ԫ�ظ��� (v.size() )
push_back(data_type a) ��Ԫ��a������β��
pop_back() ����β��Ԫ��ɾ��
v[i] ��������ȡ��i��λ�õ�Ԫ��(v[0] )
�壺
sort
ͷ�ļ�: #include
sort(begin, end);
sort(begin, end, cmp);
����
int num[] = {
1,5,6,2,9};1) sort(num, num + 5);//Ĭ�ϴ�С��������num[] = {1,2,5,6,9};
2) bool cmp(int a, int b){
return a > b;
}
sort(num, num + 5, cmp); //num[] = {9,6,5,2,1};
��ʾ��sort����Ĭ��Ϊ�������У����Ҫ�������У�Ҫ����һ�����������
bool cmp(int a,int b)return a>b;//��������
��
��ô�漶����һ����
rand�������ڲ���һ�������
ͷ�ļ� : #include < cstdlib >
���㷨��Ҫһ����ʼֵ����Ϊ���ӣ����������֡����û�и���һ�����ӣ���ô������ÿ������ʱ������ͬ����������
���ɴ˿ɼ���������Ҫ�ٸ���һ�����ӣ�
����srand������ʵ��
int main()
{
index c[100];srand( time(0) );//ϵͳ��ʱ��for (int i = 0 ; i < 100 ; ++i ){
c[i].a = rand()%10 ; c[i].b = rand()%10 ;}sort( c , c+100 , cmp );for (i = 0 ; i < 100 ; ++i ){
cout<<c[i].a <<" "<<c[i].b <<endl;}return 0;
}С��ʾ��
����ʹ��rand�ĺ�������ô��������Ĵ�С��
����һ����Χ�������ͨ�ñ�ʾ��ʽ
Ҫȡ��[a��b)�����������ʹ��(rand() % (b-a))+ a;
Ҫȡ��[a��b]�����������ʹ��(rand() % (b-a+1))+ a;
Ҫȡ��(a��b]�����������ʹ��(rand() % (b-a))+ a + 1;
ͨ�ù�ʽ��a+ rand()%n�����е�a����ʼֵ��n�������ķ�Χ��
�� ���ȶ��У�priority_queue��
(����Ԫ�ص�Ȩֵ���У�Ȩֵ��ߵ�����ǰ�棬���������ֲ�һ���ǰ���С���У�ֻ��֤��ǰ��������ģ�

ͷ�ļ�: #include
���壺priority_queue <data_type> priority_queue_name;
�磺priority_queue q;
������
q.push(elem) ��Ԫ��elem�������ȶ���
q.top() �������ȶ��е���һ��Ԫ��
q.pop() �Ƴ�һ��Ԫ��
q.size() ���ض�����Ԫ�صĸ���
q.empty() �������ȶ����Ƿ�Ϊ��
�� ȥ��unique
�ú����������ǡ�ȥ����������������������Ԫ�ص��ظ����ֵ�Ԫ��!
�����ȥ���������������erase�����ǽ��ظ���Ԫ�طŵ�������ĩβ������ֵ��ȥ��֮���β��ַ��
unique��Ե�������Ԫ�أ����Զ���˳��˳����ҵ������Ա������������Ա����Ҫ�Ƚ�������sort().
int main()
{
int a[100];int t, n;scanf("%d",&n);for(int i = 0; i < n; i++){
scanf("%d",&a[i]);}t = unique(a,a+n)-a;//������ظ�Ԫ�صĸ���for(int i = 0; i < t; i++){
printf("%d ",a[i]);}return 0;
}�ţ� ��������
ͷ�ļ�: #include
bool next_permutation(begin, end);
�ı�������Ԫ�ص�˳������һ�����С�
bool prev_permutation(begin, end);
����ǰһ�����С�
endΪ���һ��Ԫ�ص���һ��λ�á�
upper_bound �� lower_bound
upper_bound(begin, end, value);
����>value��Ԫ�صĵ�һ��λ�á�
lower_bound(begin, end, value);
����>=value��Ԫ�صĵ�һ��λ�á�
num[] = {1,2,2,3,4,5};
lower_bound(num, num + 6, 2)Ϊnum + 1
upper_bound(num, num + 6, 2)Ϊnum + 3
ʮ�� set��multset
set �� multiset������ض����������Զ���Ԫ���������ߵIJ�֮ͬ������multiset��������Ԫ���ظ���set������Ԫ���ظ���

ͷ�ļ�: #include
���壺set <data_type> set_name;
�磺set s;//Ĭ����С��������
����밴���Լ��ķ�ʽ����������С�ںš�
struct new_type{int x, y;bool operator < (const new_type &a)const{if(x != a.x) return x < a.x;return y < a.y;}
}
������
s.insert(elem) �C ����һ��elem������������Ԫ��λ�á�
s.erase(elem) �C �Ƴ���elemԪ����ȵ�����Ԫ�أ����ر��Ƴ� ��Ԫ�ظ�����
s.erase(pos) �C �Ƴ�������pos��ָλ���ϵ�Ԫ�أ�����ֵ��
s.clear() �C �Ƴ�ȫ��Ԫ�أ�������������ա�
s.size() �C ������������
s.empty() �C ���������Ƿ�Ϊ�ա�
s.count(elem) �C ����Ԫ��ֵΪelem��Ԫ�صĸ�����
s.lower_bound(elem) �C ���� Ԫ��ֵ>= elem�ĵ�һ��Ԫ��λ�á�
s.upper_bound(elem) �C ����Ԫ��ֵ > elem�ĵ�һ��Ԫ�ص�λ�á�
����λ�þ�Ϊһ����������
s.begin() �C ����һ��˫���������ָ���һ��Ԫ�ء�
s.end() �C ����һ��˫���������ָ�����һ��Ԫ�ص���һ ��λ��
������������
multiset :: iterator pos;
for(pos = s.begin(); pos != s.end(); pos++)
�� ��
ʮһ��map��multimap
����Ԫ�ض������Ԫ�صļ�ֵ�Զ�����map������Ԫ�ض���pair��pair�ĵ�һ��Ԫ�ر���Ϊ��ֵ���ڶ���Ԫ��Ϊʵֵ��map����������Ԫ������ͬ�ļ�ֵ����multimap���ԡ�
ͷ�ļ�: #include
������
m.size() ����������С
m.empty() ���������Ƿ�Ϊ��
m.count(key) ���ؼ�ֵ����key��Ԫ�صĸ���
m.lower_bound(key) ���ؼ�ֵ����key��Ԫ�صĵ�һ���ɰ��� ��λ��
m.upper_bound(key) ���ؼ�ֵ����key��Ԫ�ص����һ���ɰ� ���λ��
m.begin() ����һ��˫���������ָ���һ��Ԫ�ء�
m.end() ����һ��˫���������ָ�����һ��Ԫ�ص���һ�� λ�á�
m.clear() ������������ա�
m.erase(elem) �Ƴ���ֵΪelem������Ԫ�أ����ظ������� ��map��˵��0��1��
m.erase(pos) �Ƴ�������pos��ָλ���ϵ�Ԫ�ء�
ֱ��Ԫ�ش�ȡ��
m[key] = value��
���ҵ�ʱ�����û�м�ֵΪkey��Ԫ�أ���һ����ֵΪkey����Ԫ�أ�ʵֵΪĬ��(һ��0)��
m.insert(elem) ����һ��Ԫ��elem
a)����value_type����
map<string, float> m;
m.insert(map<string, float>:: value_type (��Robin��, 22.3));
b) ����pair<>
m.insert(pair<string, float>(��Robin��, 22.3));
c) ����make_pair()
m.insert(make_pair(��Robin��, 22.3));
ʮ����
һЩС��ʾ
#include<bits/stdc++.h>using namespace std;int main()
{
sync_with_stdio(false);....return 0;
}��#include<bits/stdc++.h>
�����˼�������Ҫ�õ�ͷ�ļ�
sync_with_stdio(false); ���Լӿ�cin cout ������ʱ��
#define �궨��
#include<bits/stdc++.h> #define rep(i,a,n) for (int i=a;i<=n;i++)//iΪѭ��������aΪ��ʼֵ��nΪ����ֵ������#define per(i,a,n) for (int i=a;i>=n;i--)//iΪѭ�������� aΪ��ʼֵ��nΪ����ֵ���ݼ���#define pb push_back#define IOS ios::sync_with_stdio(false);cin.tie(0); cout.tie(0)#define mp make_pairusing namespace std;�ɶ��Ա����ܼӿ�д������ٶȡ�
����̰���㷨
�����õ�����
��һ��������ֳɼ���С���⣬С������Ѱ�����Ž⣨�ֲ����ţ��ϵ�һ�������Ҳ�����š�
1����ô��̰��
��1�����鿴������Ƿ�����̰�ĵIJ���
��2�� ѡ��̰������ѡ�ý�Ǯ����������С���Լ۱ȵȣ�
��

#include<bits/stdc++.h>
using namespace std;
struct load
{
int index;int w;
}box[10005];
bool cmp (load a,load b)
{
return a.w<b.w;
}
int main ()
{
int c,n,x[10000];cin>>c>>n;memset(box,0,sizeof(box));memset(x,0,sizeof(x));for(int i=1;i<=n;i++){
cin>>box[i].w;box[i].index=i;}stable_sort(box,box+n+1,cmp);if(box[1]>c)cout<<"no answer"<<endl;int i;for(i=1;i<=n&&box[i].w<=c;i++){
x[box[i].index]=1;c-=box[i].w;}cout<<i-1<<endl;for(int i=1;i<=n;i++)if(x[i])cout<<i;cout<<endl;return 0;
}����ѧϰ����
ѧϰ�˺ܶ���֪ʶ��Ҳ���ܵ���ACM���Ѷȣ������������е�������������Ȼ��ϲ����һ�γ̡���Ȼ��������Լ�һ����ѡ���ſΣ����������ѡ�����Ժ���Ի��ڡ�˵�����ſΰɣ����Ҵ����˲�С��ѹ�����Ҹо�����������Ĵ�ѧ����Ҳ��������ѧ��֪ʶ����Ϊ��ģ���Ϊ�����Լ���� ���á����ſ�Ҳ���Ҹ��ܵ�����߲�һ������ѧ�ԣ��һ��кܶ�����ȥ�ֲ�����������һ���������������Լ�������һ���⣬����Դ����ʵ���� ���㡣���������ұ����ó����������п�Ŀ��Ŭ�������ACM�Ρ�����ѹ������Ҳ�ж�����Ŭ�����Լ���ø��á�