在pytorch中,图像的预处理过程中常常需要对图片的格式、尺寸等做一系列的变化,这就需要借助transforms。
transforms中很多类,可以对图片进行不同的操作
transforms的使用:
重要的是转化图片的输入格式要进行变换
利用ToTensor这个类将PIL格式转换成tensor类型的
from PIL import Image
from torchvision import transformsimg_path='mmexport1632131149054.jpg'
img=Image.open(img_path)
print(img)
tensors_trans=transforms.ToTensor()
tensor_img=tensors_trans(img)
print(tensor_img)
输出:
<PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=1440x1080 at 0x19D27A2C520>
tensor([[[0.8000, 0.8000, 0.8000, ..., 0.6588, 0.6588, 0.6588],[0.8000, 0.8000, 0.8000, ..., 0.6588, 0.6588, 0.6588],[0.8000, 0.8000, 0.8000, ..., 0.6588, 0.6588, 0.6588],...,[0.3020, 0.3020, 0.3020, ..., 0.2824, 0.2824, 0.2824],[0.3020, 0.3020, 0.3020, ..., 0.2784, 0.2784, 0.2784],[0.3020, 0.3020, 0.3020, ..., 0.2784, 0.2784, 0.2784]],[[0.8353, 0.8353, 0.8353, ..., 0.7176, 0.7176, 0.7176],[0.8353, 0.8353, 0.8353, ..., 0.7176, 0.7176, 0.7176],[0.8353, 0.8353, 0.8353, ..., 0.7176, 0.7176, 0.7176],...,[0.0745, 0.0745, 0.0745, ..., 0.0471, 0.0471, 0.0471],[0.0745, 0.0745, 0.0745, ..., 0.0431, 0.0431, 0.0431],[0.0745, 0.0745, 0.0745, ..., 0.0431, 0.0431, 0.0431]],[[0.8706, 0.8706, 0.8706, ..., 0.8000, 0.8000, 0.8000],[0.8706, 0.8706, 0.8706, ..., 0.8000, 0.8000, 0.8000],[0.8706, 0.8706, 0.8706, ..., 0.8000, 0.8000, 0.8000],...,[0.0706, 0.0706, 0.0706, ..., 0.0471, 0.0471, 0.0471],[0.0706, 0.0706, 0.0706, ..., 0.0431, 0.0431, 0.0431],[0.0706, 0.0706, 0.0706, ..., 0.0431, 0.0431, 0.0431]]])
从这个可以看出,PIL类型的图片已经转化为tensor类型的了
也可以看出Totensor这个类在图像增强中很常用
为什么要转化为tensor类型:
简单说,有些情况下训练起来简单,当然也很好用。 在图像识别当中,一般步骤是先读取图片,然后把图片数据转化成tensor格式,再输送到网络中去(初学者个人理解)
常见的transforms的使用
transforms.Compose()
这个类的主要作用是串联多个图片变换的操作
在compose参数中是一个transforms的列表

可以看到,transforms列表中,前一个的输出作为后一个输入,所以顺序也至关重要。
这个类后面样例会用,先放这
官方文档
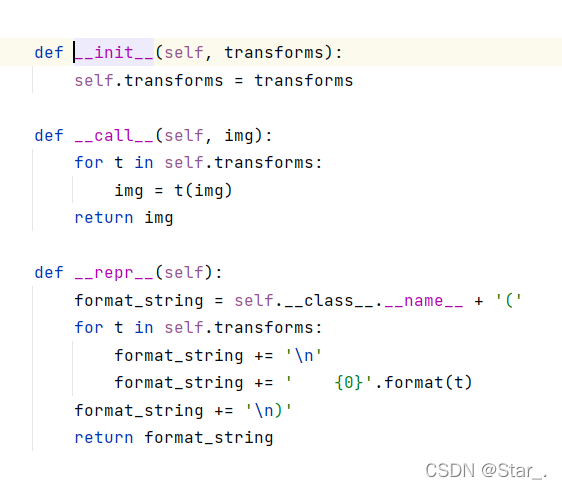
transforms.Totensor():
将PIL格式的图像以及numpy(即cv2读取的图像)转化成tensor类型,刚才示例上也写了
transforms.Normalize()
(归一化)
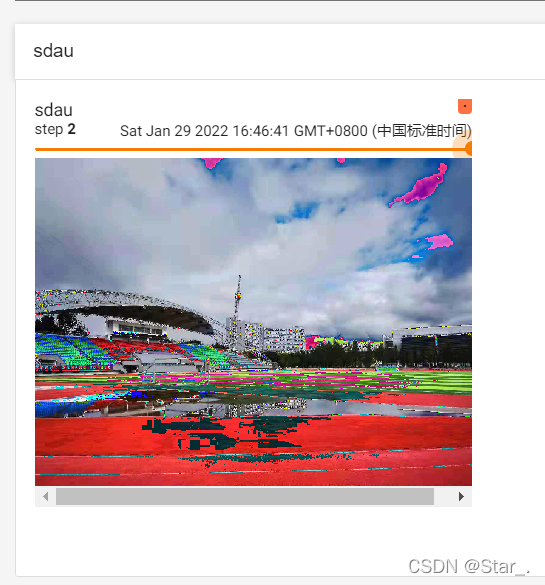
功能:图像进行标准化(均值变为0,标准差变为1),可以加快模型的收敛
output = (input - mean) / std
mean:各通道的均值
std:各通道的标准差
inplace:是否原地操作
from PIL import Image
from torchvision import transforms
from torch.utils.tensorboard import SummaryWriter
img_path='mmexport1632131149054.jpg'
img=Image.open(img_path)
writer=SummaryWriter('logs')
tensors_trans=transforms.ToTensor()
tensor_img=tensors_trans(img)
trans_normal=transforms.Normalize((3,5,4),(3,2,1))
img_normal=trans_normal(tensor_img)
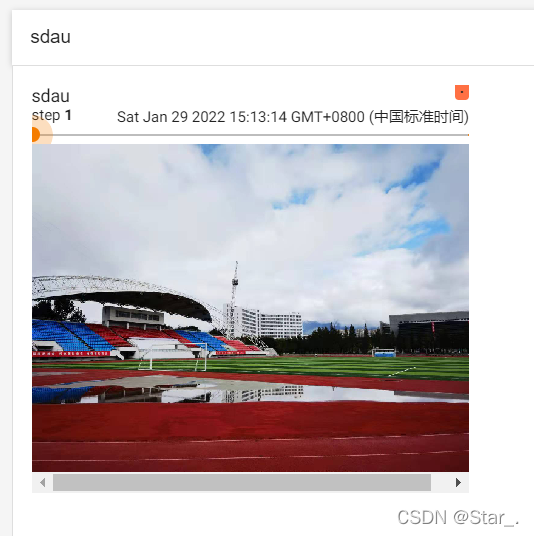
writer.add_image("sdau",tensor_img,1)
writer.add_image("sdau",img_normal,2)
writer.close()
然后使用tensorboard可视化
transforms.Resize()
调整PILImage对象的尺寸,注意不能是用io.imread或者cv2.imread读取的图片
参数就是图片的长于高,如果只传入了一个参数,就是按照最短边进行缩放,而且resize()返回的是PIL类型的变量

from PIL import Image
from torchvision import transforms
from torch.utils.tensorboard import SummaryWriter
img_path='mmexport1632131149054.jpg'
img=Image.open(img_path)
writer=SummaryWriter('lwx')
tensors_trans=transforms.ToTensor()
tensor_img=tensors_trans(img)
writer.add_image("test",tensor_img,1)
resize_trans=transforms.Resize((512,512))
resize_img=resize_trans(img)
resize_img=tensors_trans(resize_img)
writer.add_image("sdau",resize_img,1)
writer.close()
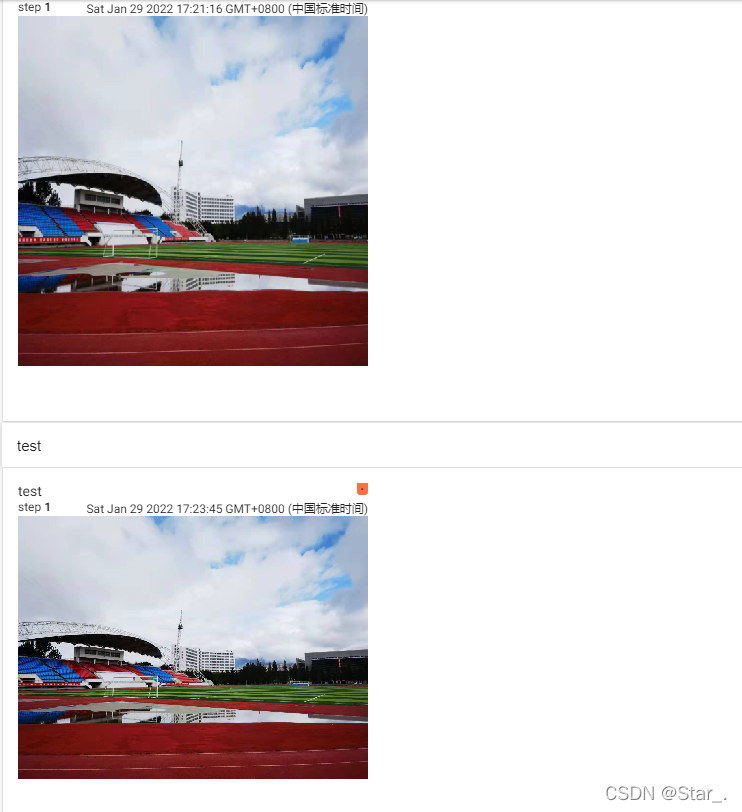
可以看出第一张有明显的缩放
下面利用compose将上述操作串联起来
from PIL import Image
from torchvision import transforms
from torch.utils.tensorboard import SummaryWriter
img_path='mmexport1632131149054.jpg'
img=Image.open(img_path)
writer=SummaryWriter('lwx')
tensors_trans=transforms.ToTensor()
tensor_img=tensors_trans(img)
writer.add_image("test",tensor_img,1)
resize_trans=transforms.Resize((512,512))
compose_trans=transforms.Compose([resize_trans,tensors_trans])
resize_img=compose_trans(img)
writer.add_image("sdau",resize_img,1)
writer.close()
transforms.RandomResizedCrop()
随机裁剪
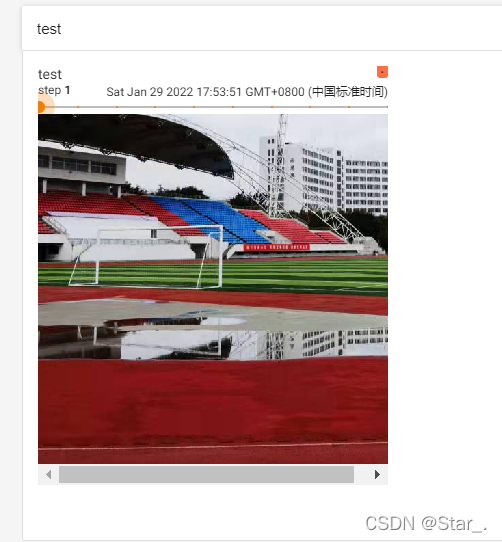
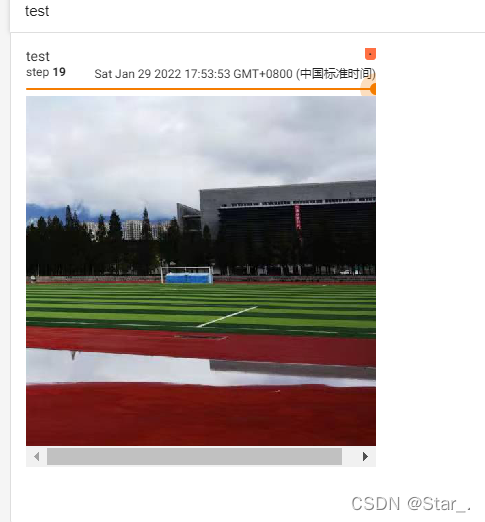
示例:裁剪512x512的图片20张
from PIL import Image
from torchvision import transforms
from torch.utils.tensorboard import SummaryWriter
img_path='mmexport1632131149054.jpg'
img=Image.open(img_path)
writer=SummaryWriter('lwx')
tensors_trans=transforms.ToTensor()
tensor_img=tensors_trans(img)
rendomcrop_trans=transforms.RandomCrop(512)
compose_trans=transforms.Compose([rendomcrop_trans,tensors_trans])
for i in range(20):rendomcrop_img=compose_trans(img)writer.add_image("test",rendomcrop_img,i)
writer.close()
等