1.Orthogonalization(正交化)
比如,老式电视调节画面的旋钮,每一个都具有相对独立的功能,如负责调节画面的宽度、长度等,这样才便于将画面调节到中间。又比如,控制汽车时,有三个功能独立的区块:方向、加速和刹车,而不是某一个既能操作方向又带有一定加速,这样才便于我们更好的控制汽车。这种功能设计就叫做Orthogonalization。
对于ML系统来讲,需要保证4件事情能做好,对应于每件事情,都有改进它们的相对独立的“旋钮”用于调整。
- 首先,很好地符合training set,通常是能达到接近人类能力。(更大的网络,更好的优化方法...)
- 然后,很好地符合dev set。(正则化,更多的数据)
- 然后,在test set也表现良好。(更大的dev set)
- 最后,在真实应用中表现良好。(更换dev set或者cost function,因为可能是用于调整的dev set不合适造成,也可能是cost function没有指示优化正确的东西)
比较不倾向于使用early stopping,它是一个很多人使用的并不糟糕的方法,但是它在使dev set拟合更好的同时,会使training set的拟合变得差一些,是一个相对不独立的“旋钮”,因此它的作用比较难以衡量。
2.衡量分类器的指标
①查准率和查全率
- Precision(查准率):
假设在是否为猫的分类问题中,查准率代表:所有模型预测为猫的图片中,确实为猫的概率。 - Recall(查全率):
假设在是否为猫的分类问题中,查全率代表:真实为猫的图片中,预测正确的概率。 - F1 Score:
相当与查准率和查全率的调和平均值
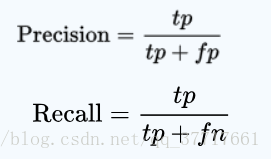

② 运行时间
假设有三个不同的分类器性能表现如下:

这里以准确度为优化指标,运行时间为满足指标,所以得出分类器B性能最好。
一般地,如果有N个评测指标,选择一个为优化指标,其余N-1个为满足指标。
3.改善模型的表现
基本假设:
- 模型在训练集上有很好的表现;
- 模型推广到开发和测试集啥会给你也有很好的表现。
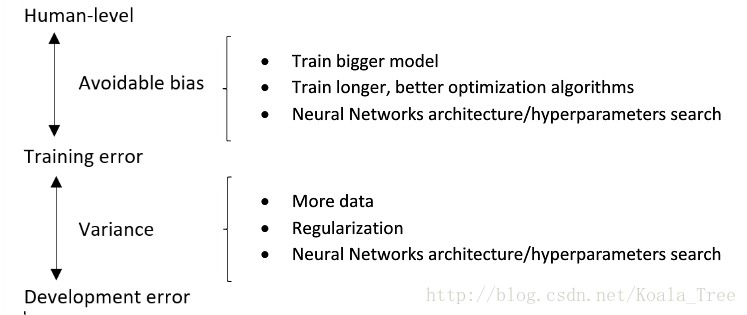
减少可避免偏差 :
- 训练更大的模型
- 训练更长时间、训练更好的优化算法(Momentum、RMSprop、Adam)
- 寻找更好的网络架构(RNN、CNN)、寻找更好的超参数
减少方差 :
- 收集更多的数据
- 正则化(L2、dropout、数据增强)
- 寻找更好的网络架构(RNN、CNN)、寻找更好的超参数
详细
4. 迁移学习、多任务学习、端到端的学习
1. 迁移学习:将训练好的模型,直接拿到新的应用场景来。
使用前提:
① 输入形式相似
② 来源问题有很多数据,而目标问题没有那么多数据
2. 多任务学习: 所有任务并行,希望每个任务都能帮助到其它所有任务,output 和 label 有多个
使用前提
①训练的一组数据可以共用低层次特征。例如无人驾驶中,识别行人、红绿灯、道路等具有相似形式特征
②每个任务的数据量差不多
③神经网络足够大
3. 端到端的学习(end to end):简而言之,以前有一些数据处理系统或学习系统,需要多个阶段的处理,而端到端可以忽略这些处理阶段,用单个神经网络来替代,能加快训练速度。
例如
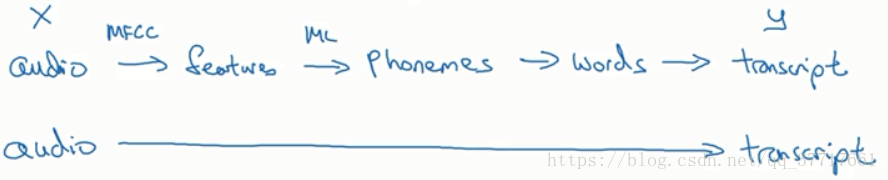
使用前提:有足够多的数据
参考1
参考2